







 超级会员免费看
超级会员免费看
文章目录
在上一章,我们了解了扩散模型的基本原理,但它离实现Stable Diffusion的文生图或图生图功能显然还有一段距离,那就是如何将文字或图片信息融入到生成图片的过程中,比如,像下图这样?
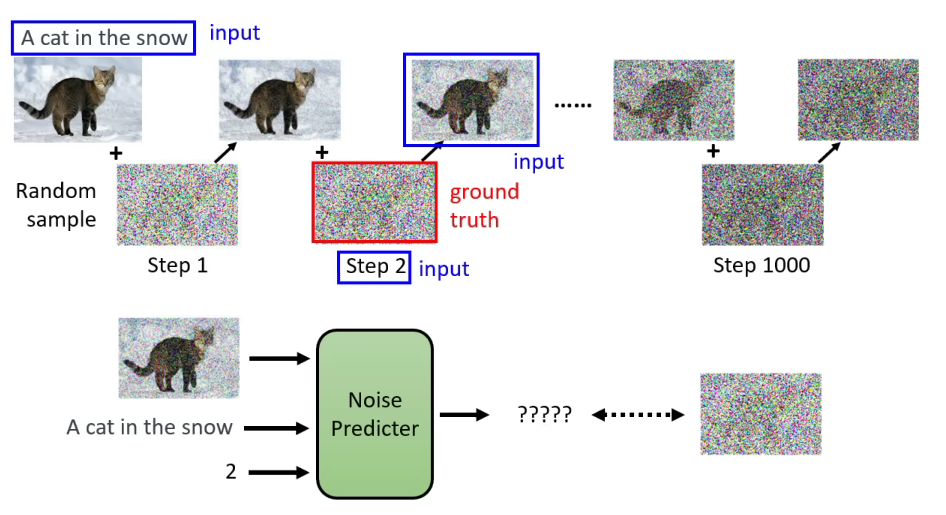
除此之外,扩散模型的一个重要特点就是维度的不变性,这就限制了生成图片大小的上限,原始论文中最大的图片生成大小也就是256×256,这意味着所有的中间表示也是这个尺度,如果再大一点,显卡和耐心可能就不够用了。
LDM
为了解决上述两个难题,我们需要在隐空间中重新审视扩散过程,并基于此重新设计生成模型,这也是Stable Diffusion的直接原理。这里我们要读一篇发表于CVPR2022的论文:《High-Resolution Image Synthesis with Latent Diffusion Models》
概述
论文提出了一个名为Latent Diffusion Models (LDM)的新模型,旨在减少直接在像素空间中训练扩散模型所带来

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2046
2046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











