



1.确保自己安装好了docker
2.Ubuntu容器安装JDK与Hadoop
下载ubuntu镜像
$ docker pull ubuntu
启动一个基础Ubuntu镜像的容器,挂载一个容器卷(volume),然后将 Hadoop的安装包放入宿主机指定的目录下。
# 宿主机:/home/hadoop/build
$ ls
hadoop.tar.gz
启动容器
docker run -it -v /home/hadoop/build:/root/build --name ubuntu ubuntu
更新apt源、安装vim、安装ssh、安装JDK
#容器中
$ apt-get update
$ apt-get install vim
$ apt-get install ssh
$ apt-get install default-jdk
开启sshd服务
$ /etc/init.d/ssh start
生成公私钥对
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
测试能否无密码连接localhost,如果需要输入密码,重新生成公私钥对
$ ssh localhost
# 记得logout
编辑~/.bashrc文件,配置好java以及sshd自启动
$ vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
/etc/init.d/ssh start
进入/root/build目录
$ cd /root/build
$ ls
hadoop.tar.gz
# 安装Hadoop
tar -zxvf hadoop.tar.gz -C /usr/local
到这里Haddoop已经安装完成,默认配置成单机版本,可运行如下命令进行测试
$ cd /usr/local/hadoop-3.3.4
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
$ cat output/*
3.配置分布式Hadoop集群
打开hadoop_env.sh文件,修改JAVA_HOME、设置USER
$ cd /usr/local/hadoop-3.3.4/etc/hadoop
$ vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
打开core-site.xml,输入以下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
然后再打开hdfs-site.xml输入以下内容
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/namenode_dir</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/datanode_dir</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
修改yarn-site.xml文件,输入以下内容
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
输入以下命令,获得一个mapred-site.xml的template拷贝(不要修改文件内容!!)
$ cp mapred-site.xml mapred-site.xml.template
至此,已经完成分布式Hadoop的配置。
4.制作镜像
我们将当前容器制作成为一个镜像
# 宿主机
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9cc679d7ddfe ubuntu "bash" 14 hours ago Up 8 minutes ubuntu
$ docker commit 9cc679d7ddfe ubuntu-hadoop:1.0
输出所有镜像查看是否保存成功
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu-hadoop 1.0 6a1294a5a6bd 14 hours ago 2.26GB
5.启动Hadoop集群
在三个终端上启动三个ubuntu-hadoop镜像,分别代表Hadoop集群中的master、slave01、slave02。通过-h标志来指定每个容器的主机名,便于互相连通。
# 第一个终端
$ docker run -it -h master --name master ubuntu-hadoop:1.0
# 第二个终端
$ docker run -it -h slave01 --name slave01 ubuntu-hadoop:1.0
# 第三个终端
$ docker run -it -h slave02 --name slave02 ubuntu-hadoop:1.0
打开/etc/hosts可以查看本机的ip和主机名信息,得到三个容器的ip和主机地址:
172.17.0.2 master
172.17.0.3 slave01
172.17.0.4 slave02
再将我们得到的host信息加入到/etc/hosts中(三个容器都需要执行这一步)
$ vim /etc/hosts
172.17.0.2 master
172.17.0.3 slave01
172.17.0.4 slave02
测试master能否无密码连接到slave01和slave02
# master容器
ssh slave01
# 记得logout
ssh slave02
# 记得logout
配置master主机的workers文件,将自己和两个slave写进去。
# master容器
$ cd /usr/local/hadoop-3.3.4/etc/hadoop
$ vim workers
slave01
slave02
master
至此,集群的配置完毕,接下来我们启动集群
# master容器
$ cd /usr/local/hadoop-3.3.4
$ bin/hdfs namenode -format
$ sbin/start-all.sh
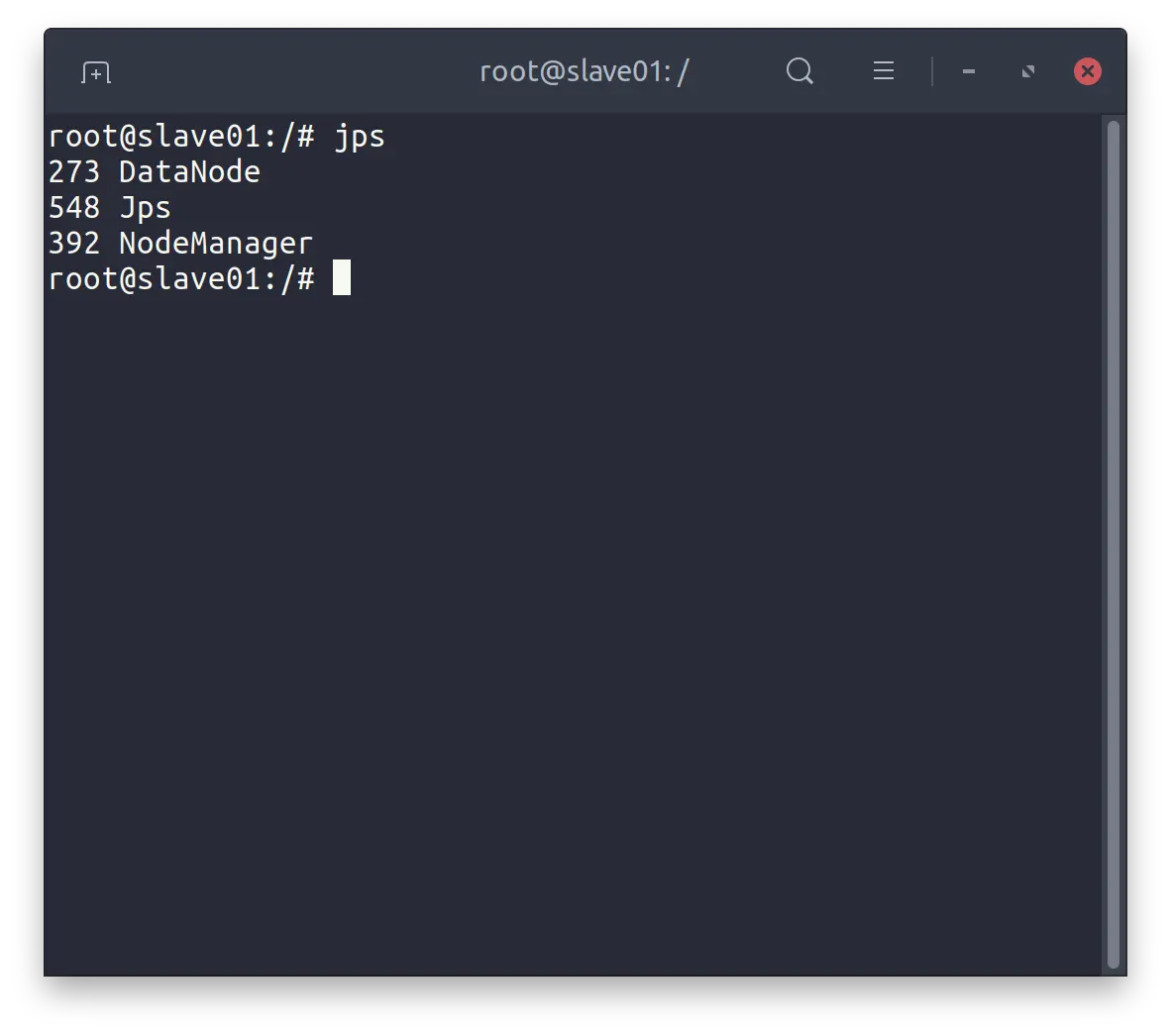
slave01
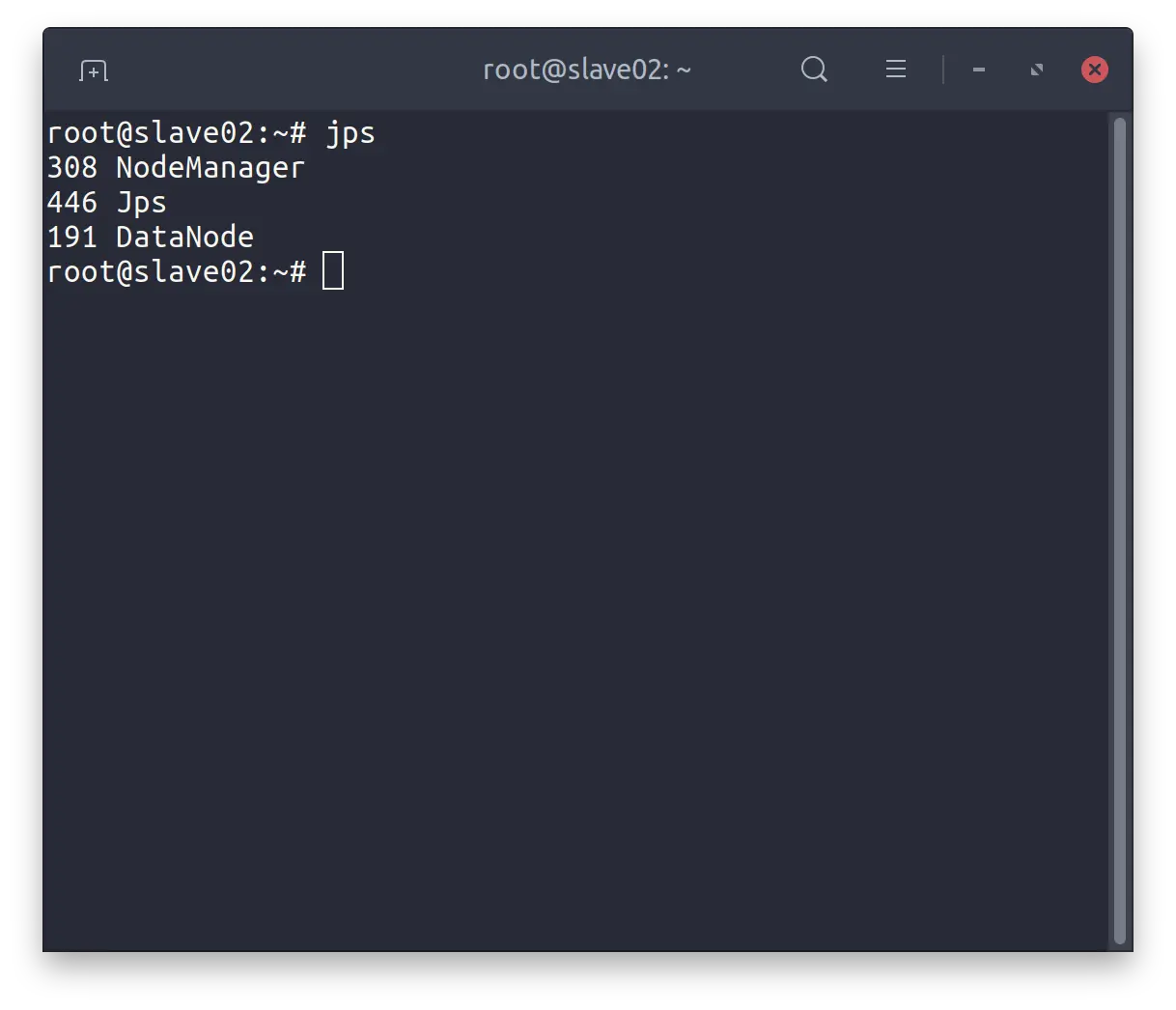
slave02
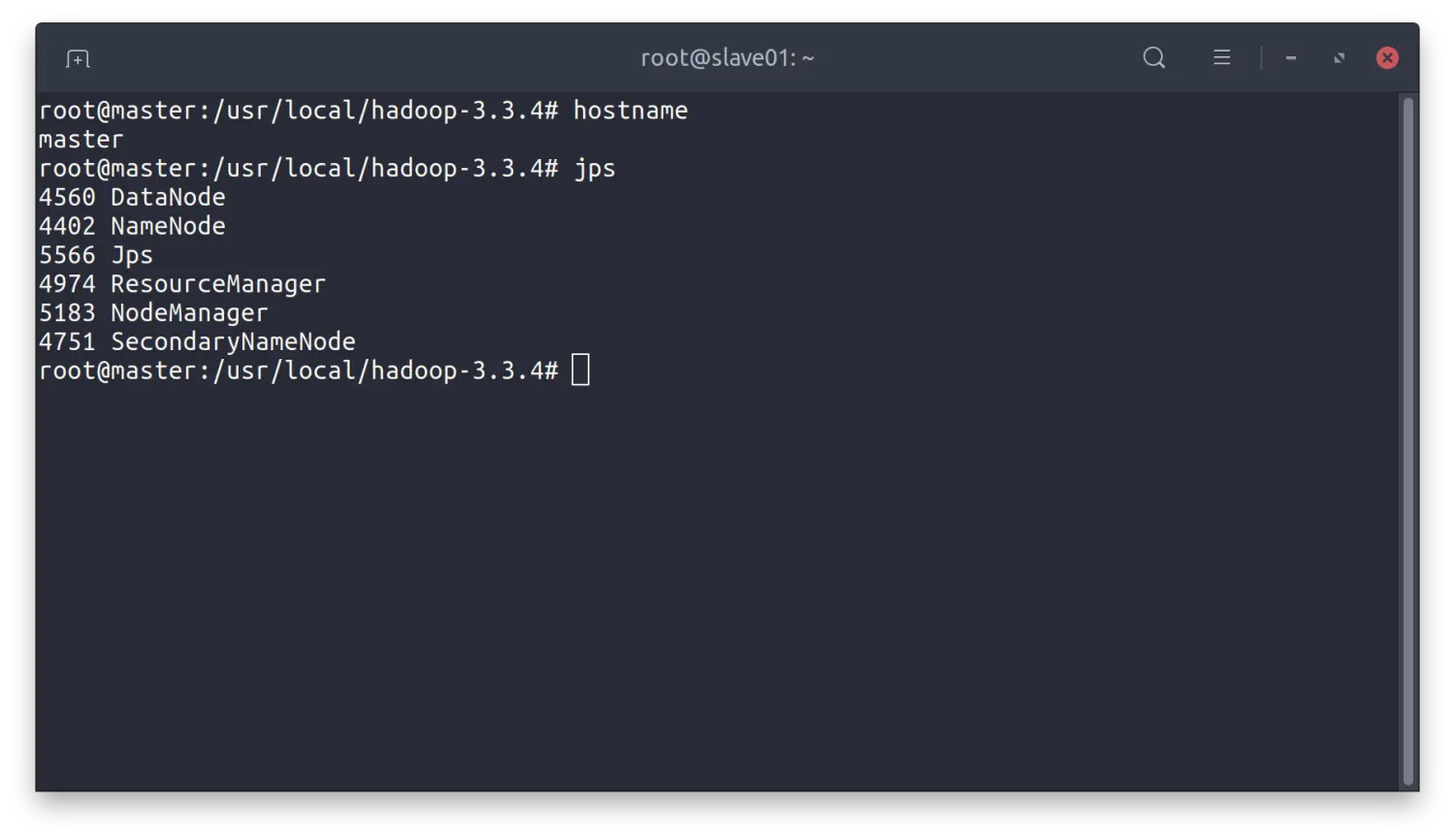
master
6.测试Hadoop集群
在HDFS上创建一个input目录(本节操作均在master容器中)
$ ./bin/hdfs dfs -mkdir -p /user/hadoop/input
拷贝测试文件到input目录
$ ./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
运行测试程序
$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input output 'dfs[a-z.]+'
查看结果
$ ./bin/hdfs dfs -cat output/*
1 dfsadmin
1 dfs.replication
1 dfs.namenode.name.dir
1 dfs.datanode.data.dir
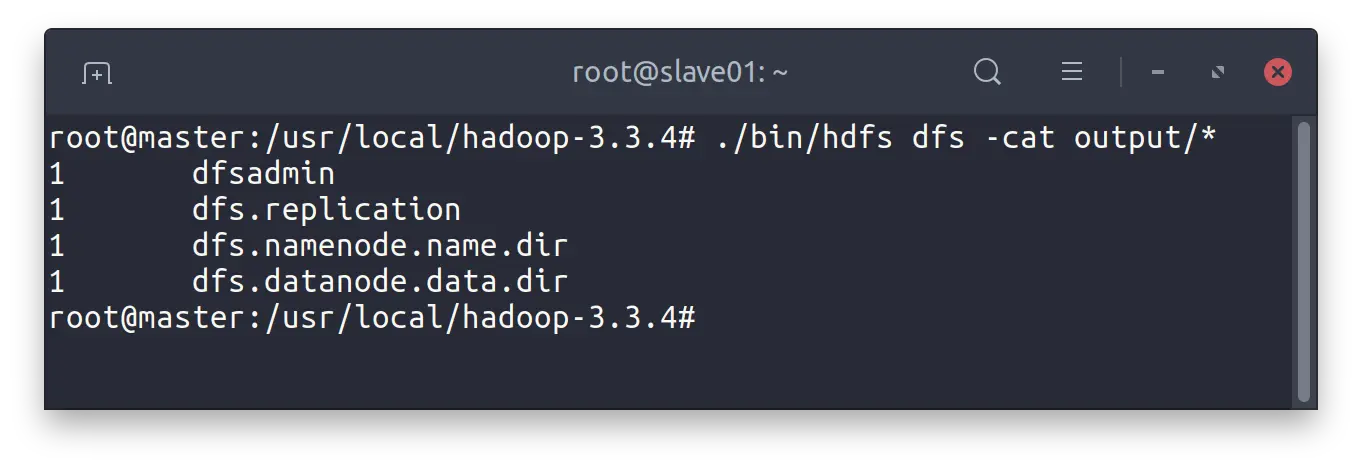
测试运行结果
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 4486
4486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









