



前言
在一些流数据用例场景中,用户希望将数据长时间存储在流中。虽然 Apache Pulsar 对topic backlog的大小没有限制,但将所有数据存储在 Pulsar 中较长时间,存储成本比较大。分层存储支持在不影响终端用户的条件下,将较旧的数据移动到长期存储中。
在推荐服务中,开发者不希望限制 backlog 的大小。以音乐服务为例,终端用户每听一首歌,就向 topic 中添加一条消息。使用这一 topic 训练推荐算法,根据终端用户听过的音乐推荐用户可能喜欢的音乐。然后,将计算结果推荐给用户,再循环这个过程。
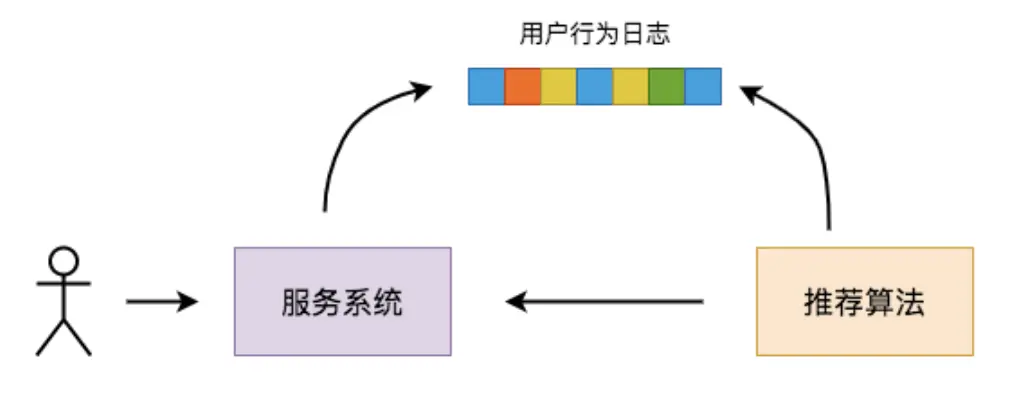
推荐算法并非一成不变。音乐服务的数据科学家一直在不断优化推荐算法,以更好地预测用户喜欢的音乐,从而提高用户对推荐服务的满意度和参与度。
但是,如果每次修改算法时,都只运行修改时间点之后的用户数据,不仅预测的准确度会受到影响,判断算法的修改效果也会需要一段较长的时间。为了解决这一问题,算法需要尽可能多地运行用户历史数据。
一、Pulsar 分层存储
Pulsar 允许用户存储任意大小的 topic backlog。当集群将要耗尽空间时,用户只需添加新的存储节点,系统将会自动重新平衡数据。但是,这样的操作运行一段时间后,运维成本十分昂贵。
Pulsar 通过提供分层存储(Apache Pulsar 2.1 起新增的特性)减少了成本/大小的损失。分层存储为用户提供大小不受限制的 backlog,且无需添加存储节点;卸载较旧的 topic 数据到长期存储中,长期存储的成本比在 Pulsar 集群中存储的成本低一个数量级。对于终端用户来说,消费存储在 Pulsar 集群或分层存储中的 topic 数据没有明显差别。位于 Pulsar 集群和分层存储中的 topic 生产和消费消息的方式也完全相同。
Pulsar 通过分片架构实现了分层存储。Pulsar topic 的消息日志由一系列分片组成。序列中的最后一个分片是 Pulsar 当前写入的分片。当前序列之前的所有分片都已封装,也就是说,这些分片中的数据不可变。由于数据不可变,因此可以轻易地将数据复制到另一个存储系统,而不必担心一致性的问题。复制完成后,可以立即更新消息日志元数据中的数据指针,并且可以删除 Pulsar 在 Apache BookKeeper 中存储的数据副本。
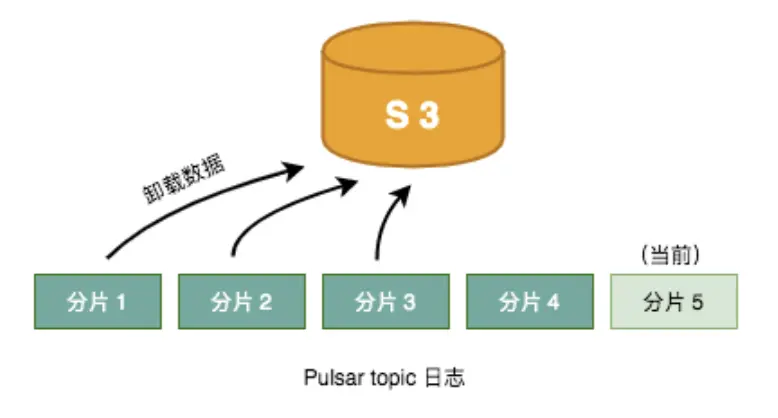
二、在 Pulsar 中使用分层存储
Pulsar 目前支持通过 Amazon S3、GCS(Google Cloud Storage)、HDFS 进行长期存储。
整体配置操作也是非常简单的,只需要在broker.conf中配置卸载地址和路径,并开启卸载自动运行即可,详细配置大家可参考: https://pulsar.apache.org/docs/en/cookbooks-tiered-storage/
要使用 S3 进行分层存储,管理员需要先在 S3 中创建一个存储桶(bucket);然后,用存储桶和创建存储桶的区域配置 broker。
managedLedgerOffloadDriver=S3
s3ManagedLedgerOffloadRegion=eu-west-3
s3ManagedLedgerOffloadBucket=pulsar-topic-offload
用户不直接在 Pulsar 中配置身份验证。Pulsar 使用的 DefaultAWSCredentialsProviderChain 可以在多个位置查找验证信息。
配置验证信息最简单的方式是在pulsar-env.sh中设置环境变量。
关于配置身份验证方法的更多信息,参阅分层存储文档:
http://pulsar.apache.org/docs/en/concepts-tiered-storage/
配置好所有 broker 后,就可以开始使用分层存储了。可以配置分层存储的数据卸载为自动运行,也可以手动触发。
自动迁移数据到长期存储
管理员可以为命名空间设置大小阈值策略。配置大小阈值策略后,如果命名空间中的任一 topic 在 Pulsar 集群上的数据大小超过了阈值,topic 就会卸载分片到长期存储中,直到 Pulsar 集群上的数据大小在阈值之内。
例如,当 Pulsar 集群上的数据大小超过 1 GB 时,指定命名空间中的 topic 卸载分片,可以使用以下命令:
pulsar-admin namespaces set-offload-threshold --size 1G my-tenant/my-namespace
当命名空间中的任一 topic 超过阈值时,topic 将会移动数据至长期存储,释放 Pulsar 集群上的存储空间。
手动卸载
除了配置自动卸载数据外,还可以通过 REST 接口或命令行界面在单个 topic 上手动触发卸载操作。要通过命令行界面触发,用户必须指定在 Pulsar 集群上为 topic 保留的最大数据量。如果 Pulsar 集群上的 topic 数据大小超过了设置的阈值,则将此 topic 上的分片移动到长期存储中,直到 Pulsar 集群上的数据大小在阈值之内。移动数据时,先移动较旧的分片。
pulsar-admin topics offload --size-threshold 10M my-tenant/my-namespace/topic1
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 34
34

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









