



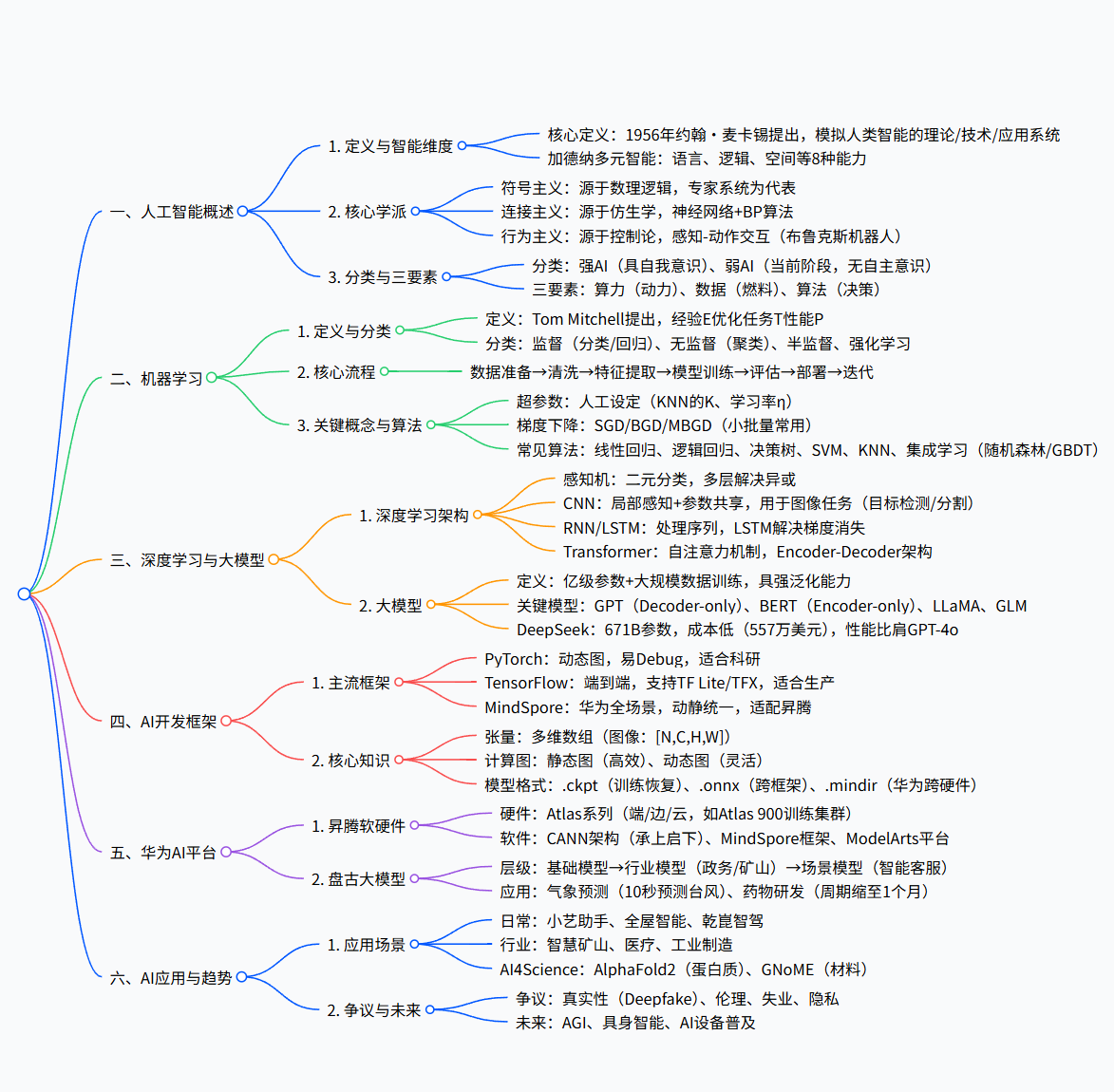
人工智能概述
通用定义:AI 是研究、开发用于模拟 / 延伸 / 扩展人类智能的理论、方法、技术及应用系统的交叉学科,1956 年首次提出,核心是让机器 “像人一样思考和行动”。
“人工” 与 “智能” 拆解:“人工” 即人设计制造;“智能” 参考霍华德・加德纳多元智能理论,含 8 种能力:语言、逻辑、空间、肢体动觉、音乐、人际、内省、自然。
AI、机器学习、深度学习的关系
层级关系:AI 是研究领域→ML 是 AI 的核心实现途径→DL 是 ML 的主流分支(源于人工神经网络)。
核心定义:
ML:模拟人类学习行为,通过经验(数据)优化性能,Tom Mitchell 定义:“对任务 T、性能 P,程序随经验 E 提升 P 表现”。
DL:模仿人脑机制解释数据(如图像、文本),含多层隐藏层的感知器是典型结构,通过组合低层特征形成高层抽象表示。
| 学派 | 核心思想 | 关键成果 |
| 符号主义 | 源于数理逻辑,认为智能是 “符号推理”,人 / 计算机都是物理符号系统 | 启发式算法、专家系统、知识工程 |
| 连接主义 | 源于仿生学,认为智能是 “神经元连接”,核心是神经网络模型与脑模型 | 反向传播(BP)算法、多层神经网络 |
| 行为主义 | 源于控制论,认为智能是 “感知 - 行动” 迭代进化,无需知识表示与推理 | 布鲁克斯六足行走机器人 |
AI 发展三要素与产业生态
三要素
算力:AI 的 “发动机”,依赖数据中心、云计算、边缘计算、HPC(高性能计算)。
数据:AI 的 “燃料”,需数据挖掘、分析、可视化、安全与隐私保护。
算法:AI 的 “大脑”,含 ML、DL、NLP、CV、推荐系统等。
产业生态
基础设施:互联网、传感器、物联网、服务器、高性能芯片。
基础技术:大数据、云计算。
AI 要素:数据、算法、算力。
技术方向:计算机视觉(CV)、语音处理、自然语言处理(NLP)、规划决策系统、大数据分析。
AI 应用:金融、医疗、安防、娱乐、教育、零售、农业等。
人工智能分类
| 类型 | 特征 | 当前阶段 |
| 强人工智能 | 能推理、解决问题,有知觉 / 自我意识,可独立思考、制定方案,具备生物本能 | 理论 |
| 弱人工智能 | 仅 “看起来智能”,无自主意识,仅在特定领域(如语音助手、图像识别)表现出智能 | 我们现在的阶段 |
AI 技术领域核心内容
自然语言处理(NLP)
定义:实现人机自然语言通信,目标是让计算机 “理解 + 生成” 人类语言。
发展历程:基于规则→机器学习→深度学习→大语言模型(LLM)。
核心任务:
文本分类:输入文档与类别集合,输出所属类别(如情感分类)。
序列标注:对文本序列(字 / 词)标注标签(如词性标注、中文分词)。
文本生成:自动生成符合语法的文本(如新闻、机器翻译)。
知识图谱:结构化表示实体及关系(如人 - 朋友 - 地点),NLP 为其提供构建手段。
计算机视觉(CV)
定义:模拟人类视觉,从图像 / 视频提取信息、分析理解并决策。
核心任务:
目标检测:定位图像中感兴趣目标,输出类别与边界框(如交通监控、人脸识别)。
图像分割:按需求细分图像子区域,含语义分割(像素级类别标注)、实例分割(逐个实例标注),适用于无人驾驶道路分割。
目标跟踪:获取目标时间维度运动轨迹(如智能交通、安防监控)。
文字识别(OCR):将图片 / 扫描件文字转为可编辑文本(如身份证、发票识别)。
图像生成:生成 / 修改图像(如超分辨率、风格迁移、图像修复)。
大模型
定义:大规模数据训练、海量参数、功能强大的模型,参数量通常亿级以上。
核心特点:
规模大:参数量十亿级起(如 GPT-3 达 1750 亿),模型文件数十至数百 GB。
算力需求高:训练需数千至数万计算卡。
能力强:多任务处理、举一反三(few-shot 学习)、跨模态理解(文本 / 图像 / 音频融合)。
发展来源:
基础架构:2017 年 Google 提出的 Transformer(Encoder-Decoder 结构)。
代表模型:GPT 系列(Decoder-only)、BERT(Encoder-only)、GLM、LLaMA、T5 等。
关键能力 “涌现”:模型规模超临界值后,突然具备复杂任务能力,如:
上下文学习(ICL):通过示例理解任务关系。
思维链(CoT):通过分步推导解决复杂推理(如数学计算)。
与小模型对比:小模型轻量高效,适用于资源受限 / 单一任务;大模型能力强、精度高,适用于复杂场景。
DeepSeek 概览及其产业影响
时间线
| 时间 | 关键事件 |
| 2023 年 7 月 | 由幻方量化梁文峰成立 |
| 2023 年 11 月 | 发布 DeepSeek coder(开源商用)、DeepSeek LLM(670 亿参数)及 Chat 版本 |
| 2024 年 5 月 | 聊天版本价格低于同行,LLM 排名第七 |
| 2024 年 11 月 | 发布 DeepSeek-R1,宣称逻辑 / 数学推理超 OpenAI o1 |
| 2024 年 12 月 | 发布 DeepSeek-V3(671B 参数,55 天训练,成本仅同行 1/10) |
| 2025 年 1 月 | 发布 DeepSeek-R1-Lite-Preview,支持模型蒸馏;App 下载量全球榜首 |
成功原因
成本低:V3 训练成本 557 万美元(同行 1/20),R1 推理成本 2.2 美元 / 百万 tokens(o1 的 3%)。
性能优:V3 比肩 GPT-4o,数学 / 代码能力更优;R1 推理能力突出。
开源策略:开源 V3、R1 及蒸馏小模型,提供详细技术报告,降低开发门槛。
产业影响
冲击格局:挑战巨头垄断(如 OpenAI),引发价格战与技术竞争。
推动技术:开源促进技术共享,改变 “重算力 / 规模、轻算法” 的发展思路。
拓展市场:降低应用门槛,满足金融、医疗、教育等多样化需求。
影响算力:推理算力重要性提升,利好国产算力生态。
人工智能应用
应用发展历程
阶段 1:模式识别(1956-2015)→阶段 2:大数据 + DL “认识世界”(2015-2022)→阶段 3:生成式 AI “创造生成”(2022-)→未来:通用人工智能(AGI)。
里程碑:ChatGPT(2022 年 OpenAI 发布,2 个月活跃用户破 1 亿,GPT-4o 具备多模态能力)。
典型应用案例
智慧矿山:机电硐室自动巡检(机器人替代人工)、井下皮带监控(撕裂 / 跑偏 / 堆煤检测)、违规行为识别(安全帽佩戴、抽烟检测)。
生物多样性保护:智利 “自然守卫者”(华为云 + AI,声学监测达尔文狐,识别盗猎 / 伐木声,实时告警)、希腊巴尔干羚羊保护。
智能电网:南方电网智能巡检(数字人 + AI 视觉,监测设备状态)。
盘古大模型(华为行业大模型)
层级划分:基础模型(如盘古自然语言大模型,2000 亿参数)→行业模型(如政务、矿山、气象大模型)→场景模型(如智能客服、政务办公助手)。
应用场景:自动驾驶、工业设计、气象预测(台风路径预测)、医疗辅助、数字人直播、智能运维等。
人工智能的争议与未来
核心争议
虚假信息:GAN、DeepFake 生成虚假图像 / 视频(如 Lyrebird 模仿人声),降低内容可信度。
伦理问题:歧视与污名化、自主决策不可追溯、目标 / 方法不可解释、侵犯人类尊严与隐私。
失业风险:AI 替代重复性 / 危险工作(如流水线、井下巡检),但也创造新岗位(如 AI 训练师)。
隐私安全:数据采集可能泄露隐私,需通过差分隐私、联邦学习、模型加密(如 MindArmour 框架)保护。
可控性:强 AI 若实现,是否可控尚无定论;AI 创作物版权归属、机器人权利赋权等法律空白。
未来趋势
价值层面:
应用场景扩展:智慧交通(公路 / 机场 / 港口)、能源(电力 / 油气)、金融(银行 / 保险)、数字政府(智慧城市 / 水利)。
市场增长:2024 年全球 AI 市场规模 6382 亿美元,中国智算服务市场 2024H1 同比增长 79.6%。
效率提升:AI 改造后工厂研发周期缩短 20.7%,生产效率提高 34.8%。
技术层面:
通用人工智能(AGI):具备跨领域学习 / 推理 / 决策能力。
具身智能:AI 融入物理本体(如机器人),实现自主感知 - 学习 - 行动。
设备层面:AI 手机(自然交互)、智能家电(节能 / 语音控制)、智能汽车(L4 + 自动驾驶)、服务机器人(管家 / 护理)。
华为人工智能解决方案
昇腾 AI 基础软硬件平台
全栈架构:芯片(Ascend 系列)→芯片使能(CANN)→框架(MindSpore)→应用使能(ModelArts、MindX)。
全场景部署:公有云、私有云、边缘计算、物联网终端、消费终端。
核心产品:
硬件:Atlas 系列(模块、板卡、服务器、集群,如 Atlas 900 AI 集群)。
软件:
MindSpore:全场景 AI 框架,支持端 - 边 - 云协同。
ModelArts:一站式 AI 开发平台(数据标注、训练、部署)。
MindX:应用使能套件(SDK、Edge 智能边缘、DL 深度学习使能)。
机器学习概览
1. 机器学习基础
(1)核心定义与本质
学习算法:通过经验(数据)优化性能的程序,核心是 “从历史数据归纳规律,预测未来”。
与传统基于规则的区别:传统靠人工显性编程,ML 靠数据自动学习规则(适用于规则复杂 / 数据分布动态变化场景)。
(2)解决的主要任务
| 任务类型 | 核心目标 | 输出类型 | 案列 |
| 分类 | 将输入映射到 k 个类别中的某一类 | 离散类别 | 垃圾邮件识别、图像分类 |
| 回归 | 预测输入对应的连续数值 | 连续数值 | 房价预测、股票价格预测 |
| 聚类 | 无标签数据按内在相似性分组,类内相似高、类间相似低 | 类别划分 | 用户画像、图片检索 |
2. 机器学习分类(按学习方式)
| 分类 | 核心特点 | 典型算法 / 案例 |
| 监督学习 | 用 “带标签样本” 训练,学习输入 - 输出映射(如 “选择题 + 标准答案”) | 线性回归、逻辑回归、SVM、决策树 |
| 无监督学习 | 用 “无标签样本” 训练,挖掘数据内在结构(如 “选择题无答案,自行分类”) | K-means、层次聚类、PCA |
| 半监督学习 | 结合少量有标签 + 大量无标签样本训练,降低标注成本 | 半监督 SVM、标签传播 |
| 强化学习 | 智能体与环境交互,通过 “奖励 / 惩罚” 优化行为(如 “试错学习”) | Q-learning、DQN、AlphaGo |
3. 机器学习整体流程
数据准备:采集数据,划分训练集(训练模型)、验证集(调超参数)、测试集(评估泛化能力)。
数据清洗:处理 “脏数据”(缺失值、异常值、不一致值)
特征提取与选择:
特征提取:将原始数据转为模型可识别的特征(如文本→词向量、图像→像素特征)。
特征选择:筛选关键特征,避免维度爆炸,方法包括:
Filter(过滤法):独立于模型,如皮尔逊相关系数、卡方检验。
Wrapper(包装法):依赖模型,如递归特征消除,计算成本高。
Embedded(嵌入法):融入模型训练,如 LASSO 回归(L1 正则)。
模型训练:选择算法,用梯度下降等优化器最小化损失函数。
模型评估:用指标评估性能(如分类用准确率 / 召回率,回归用 MAE/MSE)。
模型部署与反馈迭代:部署到生产环境,持续收集数据优化模型。
4. 模型有效性与评估
(1)核心概念
泛化能力:模型对新样本的适应能力,是 ML 的核心目标。
误差:
训练误差:模型在训练集上的误差。
泛化误差:模型在新样本上的误差(需最小化)。
欠拟合 vs 过拟合:
欠拟合:训练误差大,模型未学到特征(解决方案:更复杂模型、延长训练)。
过拟合:训练误差小但泛化误差大,模型学了噪声(解决方案:正则化、Dropout、更多数据)。
偏差与方差:
偏差:模型预期预测与真实值的差异(高偏差→欠拟合)。
方差:模型预测结果的波动(高方差→过拟合)。
理想状态:低偏差 + 低方差。
(2)性能评估指标
回归任务:
MAE(平均绝对误差):(越近 0 越好)。
MSE(均方误差):惩罚大误差)。
R²(决定系数):(取值 [0,1],越近 1 越好)。
分类任务:
混淆矩阵:TP(真正例)、TN(真负例)、FP(假正例)、FN(假负例)。
核心指标:
准确率:(整体正确率)。
召回率(查全率):TP/P(正例识别率,如疾病漏诊率关注)。
查准率:TP/(TP+FP)(预测正例的正确率,如垃圾邮件误判关注)。
F1 值:2PR/(P+R)(查准率与召回率的调和平均)。
5. 关键训练技术
(1)梯度下降算法
核心思想:沿负梯度方向更新参数,最小化损失函数,公式:(η为学习率)。
变种:
SGD(随机梯度下降):单样本更新,速度快但波动大。
BGD(批量梯度下降):全样本更新,稳定但速度慢。
MBGD(小批量梯度下降):批量样本更新(如 32/64 样本),兼顾效率与稳定(最常用)。
(2)参数与超参数
参数:模型自动学习(如线性回归的权重w、偏置b)。
超参数:人工设定(如学习率η、KNN 的K、树模型的树深度),搜索方法:
网格搜索:穷举所有组合,适用于超参数少的场景。
随机搜索:随机采样组合,适用于超参数多的场景。
(3)交叉验证
k 折交叉验证:将数据均分 k 组,每组轮流做验证集,其余做训练集,最终取 k 次评估结果的平均值(k 通常取 3/5/10),避免数据划分偏差。
6. 常见机器学习算法
(1)监督学习算法
线性回归:
定义:建模变量间线性关系,模型函数
损失函数:均方误差(MSE),用梯度下降求解。
扩展:多项式回归(处理非线性数据)、Ridge(L2 正则,防过拟合)、Lasso(L1 正则,特征选择)。
逻辑回归:
定义:二分类模型,用 Sigmoid 函数将线性输出映射到 [0,1](概率),模型:
损失函数:交叉熵损失,扩展 Softmax 回归(多分类)。
决策树:
结构:根节点(特征)→子节点(特征分支)→叶节点(类别)。
构建关键:特征选择(信息熵、GINI 系数,衡量纯度)、剪枝(预剪枝 / 后剪枝,防过拟合)。
算法:ID3(信息增益)、C4.5(信息增益比)、CART(回归 / 分类均可)。
支持向量机(SVM):
核心:找到 “最大间隔超平面” 分割数据,支持线性 / 非线性(通过核函数,如高斯核)。
适用场景:小样本、高维数据(如图像分类)。
K 近邻(KNN):
核心:“近朱者赤”,新样本类别由 k 个邻居的多数类别决定(分类)或平均值决定(回归)。
特点:非参数模型,计算量大,k 越小越易过拟合。
朴素贝叶斯:
基础:贝叶斯定理 + 特征独立假设,模型:
适用场景:文本分类(如垃圾邮件识别)、小样本。
(2)集成学习
定义:组合多个 “基学习器” 提升泛化能力,核心是 “群众智慧”。
主流方法:
Bagging(并行):独立训练基学习器,投票 / 平均输出(如随机森林 = Bagging+CART 树)。
Boosting(串行):逐步优化基学习器,纠正前序错误(如 AdaBoost、GBDT、XGBoost)。
(3)无监督学习算法
K-means:
步骤:指定 k→随机选 k 个中心→迭代分配样本 + 更新中心→收敛。
特点:简洁高效,需提前指定 k,对初始中心敏感。
层次聚类:
策略:自下而上聚合(AGNES)或自上而下拆分(DIANA),形成树形聚类结构( dendrogram)。
三、深度学习和大模型基础
1. 感知机与多层感知机
(1)感知机
定义:最简单的神经网络单元,接收多个输入x,加权求和后通过阶跃函数输出(0/1),
公式: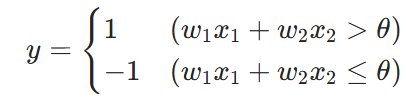
局限:仅解决线性可分问题(如与门、或门),无法解决异或问题。
(2)多层感知机(MLP)
结构:输入层→隐藏层(≥1 层)→输出层,通过堆叠感知机解决非线性问题(如异或:与门 + 与非门 + 或门组合)。
非线性来源:激活函数(如 Sigmoid、ReLU),若用线性激活,多层与单层等价。
2. 深度神经网络(DNN)基础
(1)激活函数
| 激活函数 | 公式 | 特点与适用场景 |
| Sigmoid |  | 输出 [0,1],易梯度消失,适用于二分类输出层 |
| Tanh | 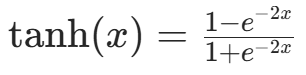 | 输出 [-1,1],中心对称,仍有梯度消失问题 |
| ReLU | ReLU(x)=max(0,x) | 缓解梯度消失,计算高效,适用于隐藏层 |
| Leaky ReLU | 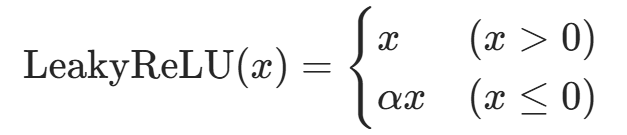 | 解决 ReLU 负半轴死亡问题 |
| Softmax | 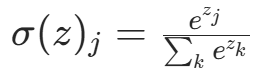 | 输出多分类概率(和为 1),适用于多分类输出层 |
(2)神经网络训练流程
前向传播:输入数据通过网络层(加权求和 + 激活)计算输出。
反向传播:用链式法则计算损失函数对各参数的梯度,更新参数(梯度下降)。
梯度问题:
梯度消失:深层网络中,梯度经多层乘法趋近于 0(解决方案:ReLU、LSTM、残差连接)。
梯度爆炸:梯度经多层乘法趋近于无穷(解决方案:梯度裁剪、权重初始化)。
3. 优化器与正则化
(1)优化器(梯度下降改进)
| 优化器 | 核心改进 | 特点 |
| 动量优化器 | 引入动量项αΔwk−1,模拟 “惯性” | 加速收敛,抑制波动 |
| Adagrad | 自适应学习率(参数梯度大则学习率小,反之则大) | 适合稀疏数据,学习率易衰减至 0 |
| RMSprop | 引入衰减系数β,平滑梯度平方,缓解 Adagrad 衰减问题 | 适用于非平稳目标(如 RNN) |
| Adam | 结合动量(一阶矩)与 RMSprop(二阶矩),自适应学习率 | 泛用性强,多数场景首选 |
(2)正则化(防过拟合)
L1 正则:损失函数加λ||w||1,使部分参数为 0(特征选择)。
L2 正则:损失函数加λ∥w∥2,使参数趋近于 0(权重衰减)。
提前停止:验证集损失上升时停止训练。
Dropout:训练时随机 “关闭” 部分神经元,测试时权重缩放,模拟集成学习。
4. 卷积神经网络(CNN)
(1)核心思想
局部感知:神经元仅感知输入的局部区域(如图像局部像素相关性高)。
参数共享:同一卷积核在全图共享参数,减少参数量(如一个卷积核提取 “边缘” 特征)。
(2)架构与核心层
输入层:图像数据(如 RGB 图像为 3 通道, shape 为 [H,W,C])。
卷积层:用卷积核(如 3×3)滑动提取特征,输出特征图,公式:(K为卷积核,b为偏置)。
池化层:降低特征图维度,保留关键信息:
最大池化:取局部区域最大值(保留纹理)。
平均池化:取局部区域平均值(保留整体特征)。
全连接层:将高维特征映射为一维向量,连接输出层(如分类任务的 Softmax)。
(3)适用场景
图像识别、目标检测、图像分割、人脸识别等。
5. 循环神经网络(RNN)与变种
(1)RNN 基础
结构:含时间步的网络,隐藏层状态依赖当前输入与上一时间步隐藏状态,公式:St=σ(USt+WXt),Ot=softmax(VSt)。
局限:时序反向传播(BPTT)中,梯度易消失 / 爆炸,无法处理长序列(如超过 20 步)。
(2)LSTM(长短期记忆网络)
核心改进:通过 “三门结构” 控制信息存储与遗忘,解决长序列依赖:
遗忘门(ft):决定丢弃多少历史信息。
输入门(it):决定存储多少新信息。
输出门(ot):决定输出多少当前信息。
公式:
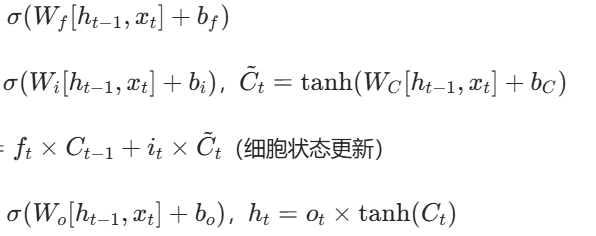
(3)Seq2Seq(序列到序列)
架构:Encoder(编码输入序列为固定向量)+ Decoder(解码向量为输出序列),基于 RNN/LSTM,适用于机器翻译、文本摘要等。
6. Transformer 架构(核心为 Attention 机制)
(1)Attention 机制
核心思想:模拟人类 “关注重点”,计算输入序列中各元素的权重,加权求和得到 Attention 值。
计算步骤:
计算 Query(查询)与 Key(键)的相似度(如点积)。
Softmax 归一化相似度,得到权重。
权重与 Value(值)加权求和,得到 Attention 输出。
Self-Attention:Query=Key=Value(如文本中词与词的关联)。
优点:并行计算(无时间步依赖)、长序列建模能力强、可解释性高。
(2)Transformer 结构
Encoder:多层(如 6 层),每层含 Multi-Head Attention(多头注意力,捕捉多维度关联)、Feed Forward(前馈网络)、Add & Norm(残差连接 + 层归一化)。
Decoder:多层(如 6 层),除 Encoder 层组件外,含 Masked Multi-Head Attention(屏蔽未来位置信息,如翻译时不看未来词)。
位置编码:通过正弦 / 余弦函数注入时序信息(Transformer 无循环结构,需额外编码位置)。
(3)适用场景
自然语言处理(如 BERT、GPT 系列)、计算机视觉(如 ViT)、多模态任务。
7. 大模型基础
(1)定义与特点
定义:亿级以上参数、大规模数据训练、多任务处理能力的模型(如 GPT-3、LLaMA、GLM)。
核心特点:
规模大:参数量十亿至万亿级(如 GPT-4 猜测 1.76 万亿)。
能力强:跨任务泛化、少样本 / 零样本学习、涌现能力(如 CoT 推理)。
跨模态:融合文本 / 图像 / 音频数据(如 GPT-4o、MidJourney)。
(2)典型大模型架构
GPT 系列:Decoder-only 结构,自回归生成文本(如 GPT-3、GPT-4)。
BERT:Encoder-only 结构,双向语境理解(如文本分类、问答)。
MoE(混合专家模型):将模型拆分为多个 “专家” 子模型,门控机制选择专家,平衡规模与效率(如 DeepSeek-V3、GLaM)。
(3)大模型训练流程
预训练:用海量通用数据(如互联网文本)训练基础模型,学习通用知识。
微调:用行业 / 场景数据微调,适配特定任务(如医疗大模型用病历数据微调)。
四、人工智能开发框架
1. AI 框架核心作用与主流框架
(1)核心作用
数据预处理:支持音 / 视 / 图 / 文数据转换、增强。
开发接口:提供统一 API(如 CNN、RNN),降低开发门槛。
调试调优:可视化工具(如损失曲线、参数分布)。
编译执行:优化计算图,适配硬件(CPU/GPU/NPU)。
推理部署:支持模型下发、算力调度(如端侧 / 边侧 / 云侧部署)。
1. 人工智能概览
(多选)计算机视觉应用场景:B. 语义分割、C. 智能驾驶、D. 视频分析(A. 知识图谱属于 NLP)。
(单选)不属于有监督学习的算法:D. K-means(A. 线性回归、B. 决策树、C. KNN 均为有监督)。
(判断)梯度下降是机器学习唯一方法:B. False(还有牛顿法、拟牛顿法等)。
2. 深度学习基础
(单选)不属于深度学习神经网络的是:D. Logistic(Logistic 回归是传统 ML,A. CNN、B. RNN、C. LSTM 是 DL)。
(多选)卷积神经网络部件:A. 激活函数、B. 卷积核、C. 池化、D. 全连接层。
(判断)CNN 比 RNN 更适合图像识别:A. True(CNN 局部感知 / 参数共享适配图像,RNN 适配序列)。
(判断)Transformer 与 Seq2Seq 特性类似:B. False(Transformer 基于 Attention,无 RNN 的时序依赖,Seq2Seq 基于 RNN)。
3. 华为人工智能平台
昇腾芯片架构名称:达芬奇架构。
CANN 中图像预处理单元名称:DVPP(数字视觉预处理模块)。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









