



目录
基本概念
什么是 AI
模型(Model)
大语言模型 (LLM)
提示词 (Prompt)
词元(Token)
Spring AI 是什么
快速入门
环境要求
申请 API Key
项目创建
接口编写
核心接口
ChatModel
ChatClient
消息类型
SystemMessage
UserMessage
AssistantMessage
输出格式
结构化输出
流式输出
SSE 协议介绍
SSE 数据格式
data
event
id
retry
SSE 使用示例
Flux
Advisors
基本概念
什么是 AI
AI:也就是 人工智能(Artificial Intelligence),顾名思义,就是让机器模拟人类智能的科学与技术
我们通过一个示例来对比理解:
普通计算机程序:像一台自动售货机。你按下特定的按钮(输入),它就给你一瓶特定的饮料(输出)。它的所有行为都是程序员预先设定好的规则
人工智能程序:更像是一个正在学习的孩子。你给它看很多猫和狗的图片(数据),并告诉它哪个是猫,哪个是狗。经过学习后,当你给它一张它从未从未见过的猫咪图片时,它也能识别出来。它自己从数据中学会了规律,而不是依赖硬编码的规则
因此,AI 的核心是从经验中学习,并根据所学做出决策或预测
而目前最主流、最引人注目的 AI 分支是 生成式人工智能,也就是现在常说的 AIGC(Artificial Intelligence Generated Content,人工智能生成内容)。它与传统 AI(主要用于分析数据,比如识别人脸)不同,它的目标是利用人工智能技术自动生成或创造出各类数字内容,比如写文章、报告、翻译、编程
为了更好的理解 AI,我们先来理解其中的一些常见术语
模型(Model)
模型(Model)是 AI系统的核心,它是通过算法在数据数据上训练后得到的结果。模型本质上是一个数学函数,它接收输入数据,并进行计算,然后产生输出。
我们常说的“调用一个AI”,实际上就是在使用这个“模型”。模型文件大小不一,可以从几MB到几十GB
可以把 AI 模型想象成一个 “虚拟大脑”。这个大脑通过在大量数据上进行“训练”或“学习”,掌握了一些技能和知识。而当被提问时,就需要运用这个大脑掌握的知识来解决问题
大语言模型 (LLM)
LLM( Large Language Model,大语言模型):一种基于深度学习的、使用海量文本数据训练的模型。它的主要任务是理解和生成人类语言。LLM是当前生成式AI热潮的代表。它们的特点是“大”,体现在训练数据量大、模型参数数量巨大
可以将其看做一个进行了超大规模训练的 “专家大脑” 。它通过学习互联网上几乎所有的文本,掌握了语言的语法、句法、事实知识以及上下文逻辑,拥有数百亿甚至数千亿个参数,并且因为它什么都学过,所以能应对各种各样的话题和任务
提示词 (Prompt)
提示词(Prompt):用户提供给AI模型的指令、问题或上下文信息。模型根据提示词来生成相应的回复。提示词的质量直接决定了 AI 回答的质量。
而设计和优化提示词的过程被称为“提示词工程”,是一门新兴的技能。
提示词就像是给AI这位“天才天才”下达的“工作订单”。订单越清晰、越具体,完成的工作质量就越高。
例如:
简单提示词:“法国的首都是哪里?” -> 模型回答:“巴黎。”
复杂提示词(角色扮演):“假设你是一位资深营养师,请为我(一位办公室久坐的上班族)设计一份为期一周的健康午餐食谱。” -> 模型会以营养师的口吻提供一份详细的食谱。
词元(Token)
词元(Token):是模型处理和理解的基本文本单位。它不是完全等同于一个英文单词或一个汉字。模型在处理前,会先将文本拆分成词元,同时,词元也是计费和衡量模型处理长度的基本单位。
英文中,单词
“unbelievable”可能会被拆分成三个词元[“un”, “believe”, “able”]中文中,“我喜欢编程”这句话,很可能会被拆分成四个词元[“我”, “喜”, “欢”, “编程”]
不同模型的分词规则不同,同一个词在不同模型中可能被拆分成不同词元
了解了 AI 的基本概念,接下来,我们来看 Spring AI 相关内容
Spring AI 是什么
Spring AI 是一个基于 Spring 生态系统的开源人工智能应用框架,它的核心目标是简化 AI 功能在 Java 应用程序中的集成过程,让 Java 开发者也能高效地构建生成式 AI 应用
官方文档:简介 :: Spring AI 参考文档 - Spring 框架
Spring AI 提供了作为开发 AI 应用基础的抽象。这些抽象具有多种实现,可以通过最少的代码更改轻松实现组件切换。
Spring AI 提供了一系列强大而实用的功能,使其成为一个功能完备的 AI 应用开发框架:
1. 统一的多模型支持:支持与众多主流的 AI 模型提供商进行交互,包括 OpenAI、Microsoft、Amazon、Google 和 Anthropic 等,无论是云端模型还是本地部署的模型(如通过 Ollama),都能通过一致的接口进行调用
2. 强大的数据集成能力:这是 Spring AI 的一大亮点。它内置了对向量数据库(如 Chroma、Pinecone、Redis 等)的支持
3. 与 Spring 生态无缝集成:作为 Spring 大家庭的一员,它能自然地与 Spring Boot、Spring Data 等其他知名项目协同工作
4. 简化的开发模式:允许 AI 模型根据需要请求执行客户端定义的函数,从而接入实时信息或触发具体动作
了解了相关概念后,我们就来上手体验一下 Spring AI
快速入门
环境要求
JDK 版本:JDK 17 或以上 (推荐 JDK 21),这是强制要求,因为 Spring Boot 3.x 本身就需要 JDK 17+
Spring Boot 版本:Spring Boot 3.2 或以上 ,具体版本可以是 3.3.3、3.4.3 或 3.5.0,选择一个稳定的3.x最新版本即可。
AI 服务凭证:有效的 API Key,需要一个来自 AI 服务提供商(如 OpenAI、DeepSeek、阿里百炼等)的账户和 API Key
在本篇文章中,我们以 DeepSeek 作为示例来进行学习
申请 API Key
我们访问 DeepSeek 官网:DeepSeek | 深度求索
进入 API 开放平台:

创建 API Key:
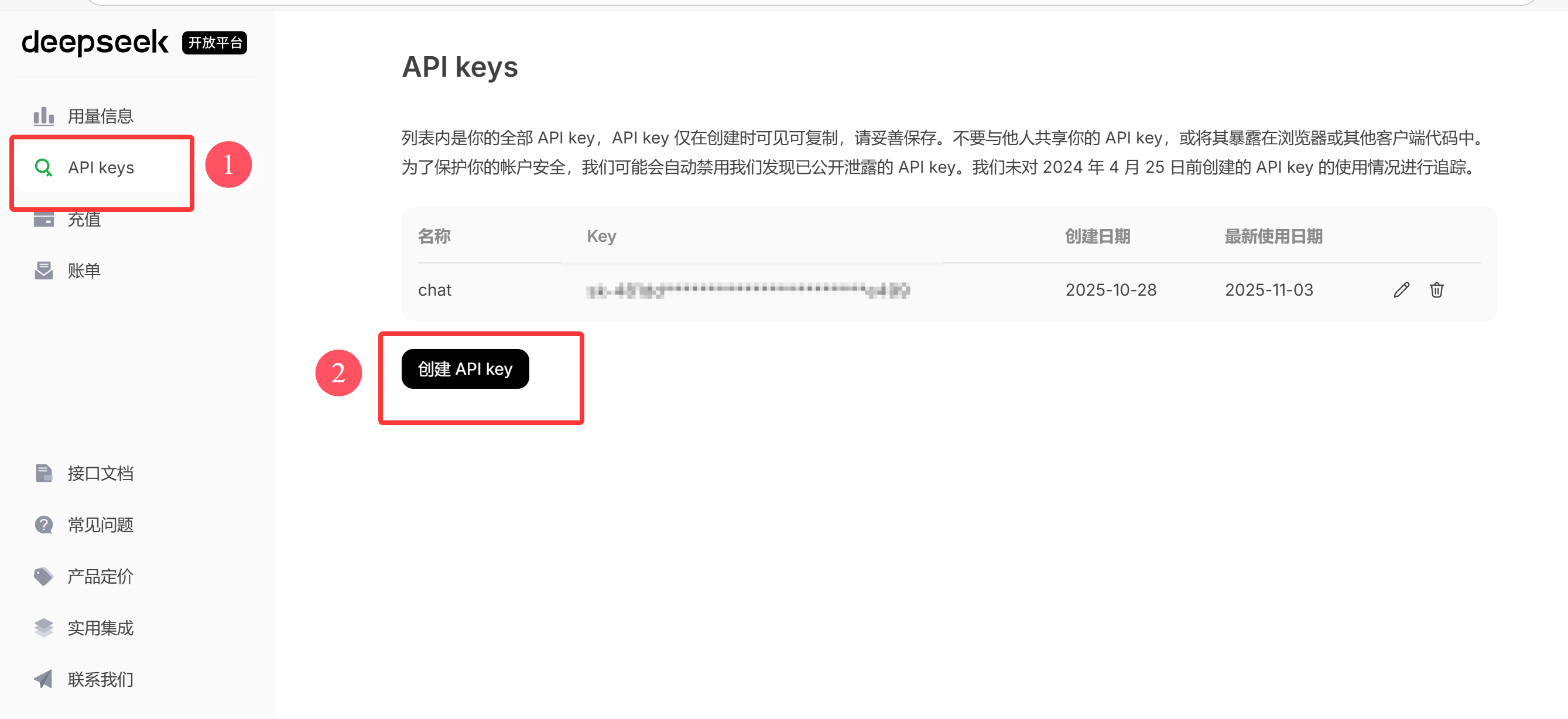
点击创建之后输入名称即可完成创建,但需要注意的是 API key 仅在创建时可见可复制
然后需要进行充值(充值前需要进行实名认证):
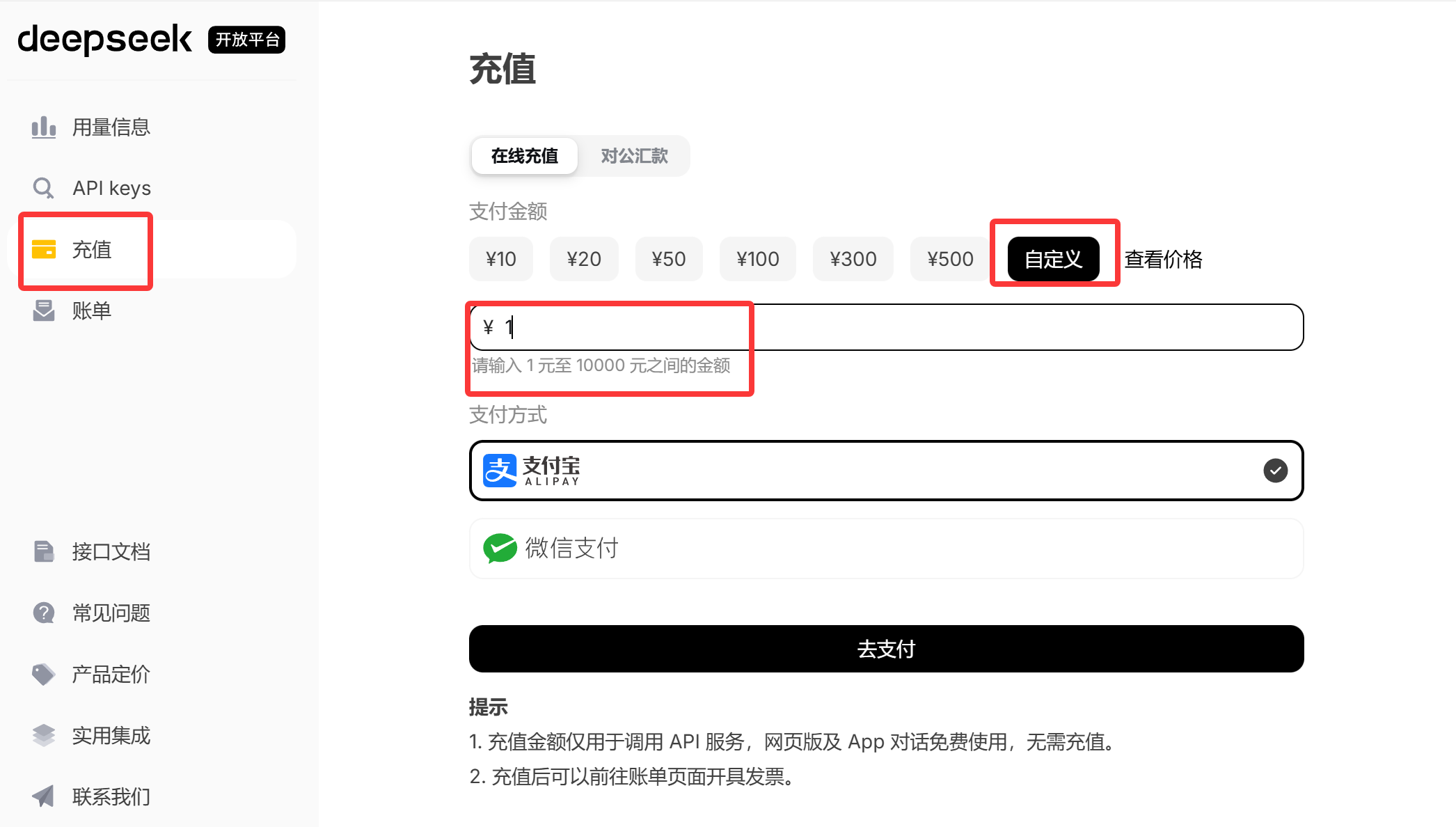
只是学习使用,1块就够了
项目创建
Spring AI 专门为 OpenAI 及兼容 API 服务设计了 spring-ai-openai-spring-boot-starter,用于快速集成大模型语言能力到 Spring Boot 应用中:
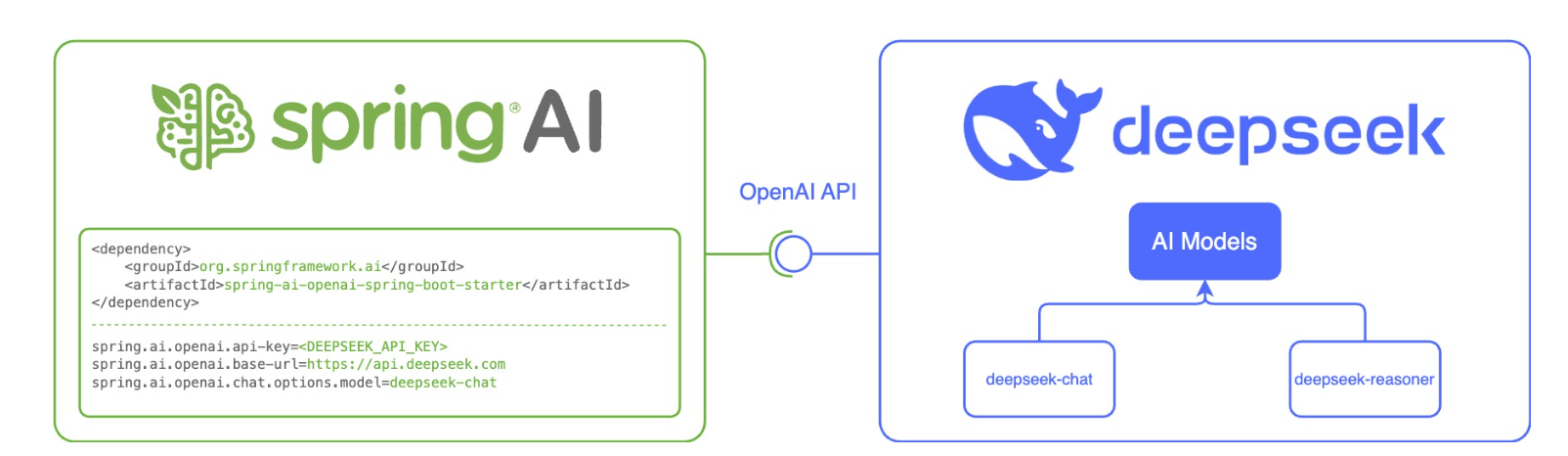
正常创建 Maven 项目(注意JDK 和 Spring Boot 版本),并添加 Spring AI 依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>依赖版本可参考:https://docs.spring.io/spring-ai/reference/getting-started.html
在 application.yml 中配置 API 密钥:
spring:
ai:
openai:
#DeepSeek
api-key: 申请的 API Key
base-url: https://api.deepseek.com
chat:
options:
model: deepseek-chat
temperature: 0.7其中:
spring.ai.openai.base-url:要连接的 URL
spring.ai.openai.api-key:申请的 DeepSeek API 密钥
spring.ai.openai.chat.options.model:要使用的 DeepSeek LLM 模型
spring.ai.openai.chat.options.temperature:用于控制模型生成文本的随机性和创造性:低温 (接近 0.0) → 保守、确定、可预测;高温 (接近 2.0) → 冒险、多样、富有想象力。也就是说,temperature 值越低,相同的提问得到的结果越类似。此外,不建议在同一个补全请求中同时修改 temperature 和 top_p,因为这两个设置的交互作用难以预测。
配置项可参考:https://docs.spring.io/spring-ai/reference/api/chat/deepseek-chat.html
此时,就已经完成了 项目的创建 和 DeepSeek 的接入,接下来,我们通过编写接口来调用模型
接口编写
@RestController
@RequestMapping("/deepseek")
public class DeepSeekChatController {
@Autowired
private OpenAiChatModel deepSeekChatModel;
@GetMapping("/chat")
public String generate(String message) {
return deepSeekChatModel.call(message);
}
}运行,并访问 127.0.0.1:8080/deepseek/chat?message=你是谁 进行测试

上述,我们通过 ChatModel 完成了与模型的交互
而在 Spring AI 框架中,ChatModel 和 ChatClient 是构建 对话式AI 应用的两大核心接口,接下来,我们分别来看这两个接口
核心接口
ChatModel
ChatMode 直接与底层 AI 模型(如 GPT-4、Claude 等)通信,处理原始的请求和响应
因此,ChatModel 更底层,使用更灵活
@Service
public class ChatService {
@Autowired
private ChatModel chatModel; // 例如 OpenAiChatModel
public String askQuestion(String question) {
// 1. 构造消息
UserMessage userMessage = new UserMessage(question);
// 2. 创建 Prompt
Prompt prompt = new Prompt(List.of(userMessage));
// 3. 调用并获得完整响应
ChatResponse response = chatModel.call(prompt);
// 4. 从响应中提取内容
return response.getResult().getOutput().getContent();
}
}ChatClient
ChatClient 在 ChatModel 之上提供了一层流畅的 API,简化了常见的使用模式
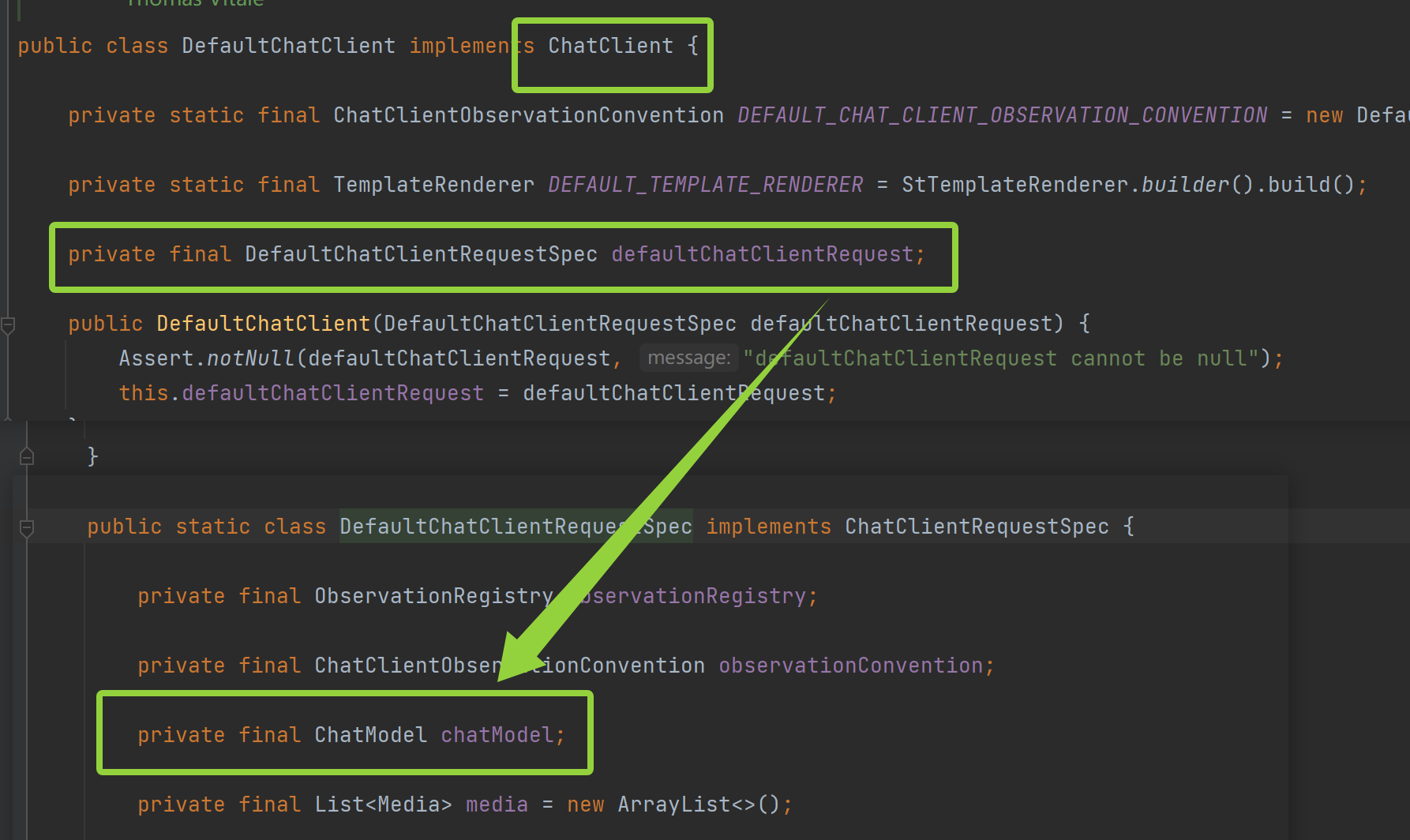
即 ChatClient 是对 ChatMode 的一层包装
因此,ChatClient 更高级,也更简洁
@Service
public class ChatService {
@Autowired
private ChatClient chatClient;
public String askQuestion(String question) {
// 一行搞定
return chatClient.call(question);
}
}可以看到,ChatClient 的使用更加简洁直观
ChatMode 与 ChatClient 对比:
维度 ChatModel ChatClient
抽象层级 底层,接近原始模型 高层,面向业务使用
返回值 ChatResponse(包含丰富元数据的完整响应对象) ChatResponse(直接获得内容的纯文本)或流式响应
使用方法 需要手动构造 Prompt 对象 提供流式的 builder 模式
控制粒度 精细控制 快捷简便
消息类型
在 Spring AI 中,所有消息类型都实现了 org.springframework.ai.chat.messages.Message 接口,系统中的消息被设计用来模拟一个多轮对话中的不同参与者
其中,最常使用的是 SystemMessage、UserMessage 和 AssistantMessage
SystemMessage
SystemMessage 通常用于设定 AI 助手的身份、性格、行为准则和对话规则,一般位于对话的开头,为整个对话设定基调
例如,我们可以为其进行角色预设:
@RequestMapping("/chat")
@RestController
public class ChatClientController {
private ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.defaultSystem("你叫小小鱼,是一款专业的智能答疑AI助手,擅长Java和Python,以友好的态度来回答问题")
.build();
}
@GetMapping("/call")
public String generation(String userInput) {
return this.chatClient.prompt()
.user(userInput) // 用户输入
.call() // 调用 API
.content(); // 返回响应
}
}在 ChatClient 中,通过 defaultSystem 来设置 AI 模型的默认系统消息,通过 ChatClient.Builder 链式调用设置的系统消息会作为对话的 "初始指令",注入到每次对话的上下文中,引导 AI 的回复风格或身份设定
此时,我们访问接口,再次询问其身份:

UserMessage
UserMessage 表示我们提出的具体问题或指令,上述输入的 "你是谁",就是 UserMessage
AssistantMessage
AssistentMessage:是AI模型给出的回复

AssistentMessage 是实现 连贯多轮对话 的关键。每次 AI 回复后,可以将这个回复作为 AssistantMessage 保存下来,并在下一次请求时将其作为历史上下文的一部分发送给 AI
输出格式
结构化输出
若想要从 LLM 接收结构化输出,Spring AI 支持将 ChatModel/ChatClient 方法的返回类型从 Spring 更改为其他类型
通过 entity() 方法将模型输出转化为自定义实体
例如:
@RequestMapping("/chat")
@RestController
public class ChatClientController {
private ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.build();
}
@GetMapping("/entity")
public String entity(String userInput) {
Recipe entity = this.chatClient.prompt()
.user(String.format("请帮我生成%s的菜谱", userInput))
.call()
.entity(Recipe.class);
return entity.toString();
}
record Recipe(String dis, List<String> ingredients) {}
}
流式输出
首先我们对比来看什么是流式输出:
传统输出(非流式):等待全部生成完成后才一次性返回,用户长时间等待 → 突然显示完整答案。像寄送一封平信,写完所有内容才寄出,对方一次性收到整封信。
流式输出:边生成边返回,立即推送部分结果,几乎立即开始显示 → 逐字逐句增长。像打电话一样,对方一边说话,你一边就能听到。
流式输出过程:
用户提问: "请写一篇关于春天的短文"
AI 模型生成过程:
"春天"... (立即返回)
"春天来了"... (继续返回)
"春天来了,万物复苏"... (持续返回)
直到生成完整回答SSE 协议
Spring AI 主要通过 响应式编程 来实现流式输出,使用 stream() 方法生成 Flux<String> 流
@RequestMapping("/chat")
@RestController
public class ChatClientController {
private ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.build();
}
@GetMapping(value = "/stream", produces = "text/html;charset=utf-8")
public Flux<String> stream(String userInput) {
return this.chatClient.prompt()
.user(userInput)
.stream()
.content();
}
record Recipe(String dis, List<String> ingredients) {}
}但是,我们思考这样一个问题:由于 HTTP 协议本身设计为无状态的请求-响应模式,也就是严格来说,无法做到服务器主动推送消息到客户端,那么我们要如何实现服务器的流式响应呢?
我们可以通过 SSE(Server-Sent Events,服务器发送事件)来实现流式传输,允许服务器主动向浏览器推送数据流
SSE 协议介绍
SSE 是一种基于 HTTP 的轻量级实时通信协议,浏览器通过内置的 EventSource API 接收并处理这些实时事件
服务器向客户端声明:接下来发送的是 流消息(streaming)、
此时客户端不会关闭连接,会一直等待服务器发送过来新的数据流
SSE 核心特点:
1. 单向通信:数据流只能从服务器推送到客户端。客户端不能通过这个连接向服务器发送数据(除了最初的建立连接请求)。
2. 基于 HTTP/HTTPS:SSE 使用标准的 HTTP 协议,这意味着它可以轻松地穿越大多数防火墙和代理服务器,无需特殊的配置。
3. 长连接:客户端发起一个普通的 HTTP 请求,但服务器会保持这个连接处于打开状态,而不是在发送一次响应后就关闭它。
4. 文本数据流:服务器通过这个持久的连接,持续地向客户端发送遵循特定格式的文本数据流。
5. 自动重连:SSE 协议内建了重连机制。如果连接意外断开,浏览器会自动尝试重新连接到服务器。
SSE 数据格式
服务器向浏览器发送 SSE 数据,需要设置必须的 HTTP 头信息
Content-Type: text/event-stream;charset=utf-8
Connection: keep-alive整个数据流由一系列消息组成,每条消息(message)由一行或多行文本构成,每行文本以一个字段名开头,后跟一个冒号和一个空格,然后是字段的值,每条消息以一个空行(即两个连续的换行符 \n\n)结束
每一行格式:[field]: value\n
field 的常见取值有:data、event、id、retry
data
data:消息主体,是最重要的字段,用于承载消息的实际内容,如果一个消息包含多个 data 行,客户端会将它们用换行符 (\n) 连接起来,形成一个完整的数据字符串。可用于传递 JSON 字符串、纯文本、XML 等任何文本数据
示例:
data: 这是一条简单的消息\n\n
data: Hello\n
data: World\n
data: !\n\n
event
event:事件类型,用于指定消息的自定义类型,若提供了此字段,客户端将触发对该特定事件名的监听器;否则,将触发通用的 onmessage 事件,可用于对不同类型的消息进行分类处理
示例:
event: userJoined
data: Alice
id
id:事件id,用于为消息设置一个唯一的 ID(字符串),如果连接中断,当客户端重新连接时,会在 HTTP 请求头 Last-Event-ID 中自动发送最后一个接收到的 ID。可以用于实现消息的幂等性和断点续传。
示例:
id: msg-123
data: 这是一条重要消息
retry
retry:重连时间,表示建议浏览器在连接断开后再次尝试连接之前应等待的毫秒数,由于这不是一个强制命令,浏览器可能会忽略它。用于避免在服务器出现故障时,客户端过于频繁地重试。
示例:告诉浏览器,如果连接失败,请等待 10 秒后再尝试重连
retry: 10000
我们通过一个简单的示例来看 SSE 协议的使用
SSE 使用示例
后端接口:
@Slf4j
@RequestMapping("/sse")
@RestController
public class SseController {
@RequestMapping("/end")
public void end(HttpServletResponse response) throws IOException, InterruptedException {
log.info("发起请求: event");
response.setContentType("text/event-stream;charset=utf-8");
PrintWriter writer = response.getWriter();
for (int i = 0; i < 10; i++) {
// 事件 foo 事件
String s = "event: foo\n";
s += "data: " + new Date() + "\n\n";
writer.write(s);
writer.flush();
Thread.sleep(1000L);
}
//定义end事件, 表示当前流传输结束
writer.write("event: end\ndata: EOF\n\n");
writer.flush();
}
}前端实现:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>SSE</title>
</head>
<body>
<div id="sse"></div>
<script>
let eventSource = new EventSource("/sse/end");
eventSource.addEventListener("foo", function(event) {
console.log(event);
document.getElementById("sse").innerHTML = event.data;
});
eventSource.addEventListener("end", function(event) {
console.log("连接关闭")
eventSource.close();
});
</script>
</body>
</html>运行,观察控制台打印的日志:
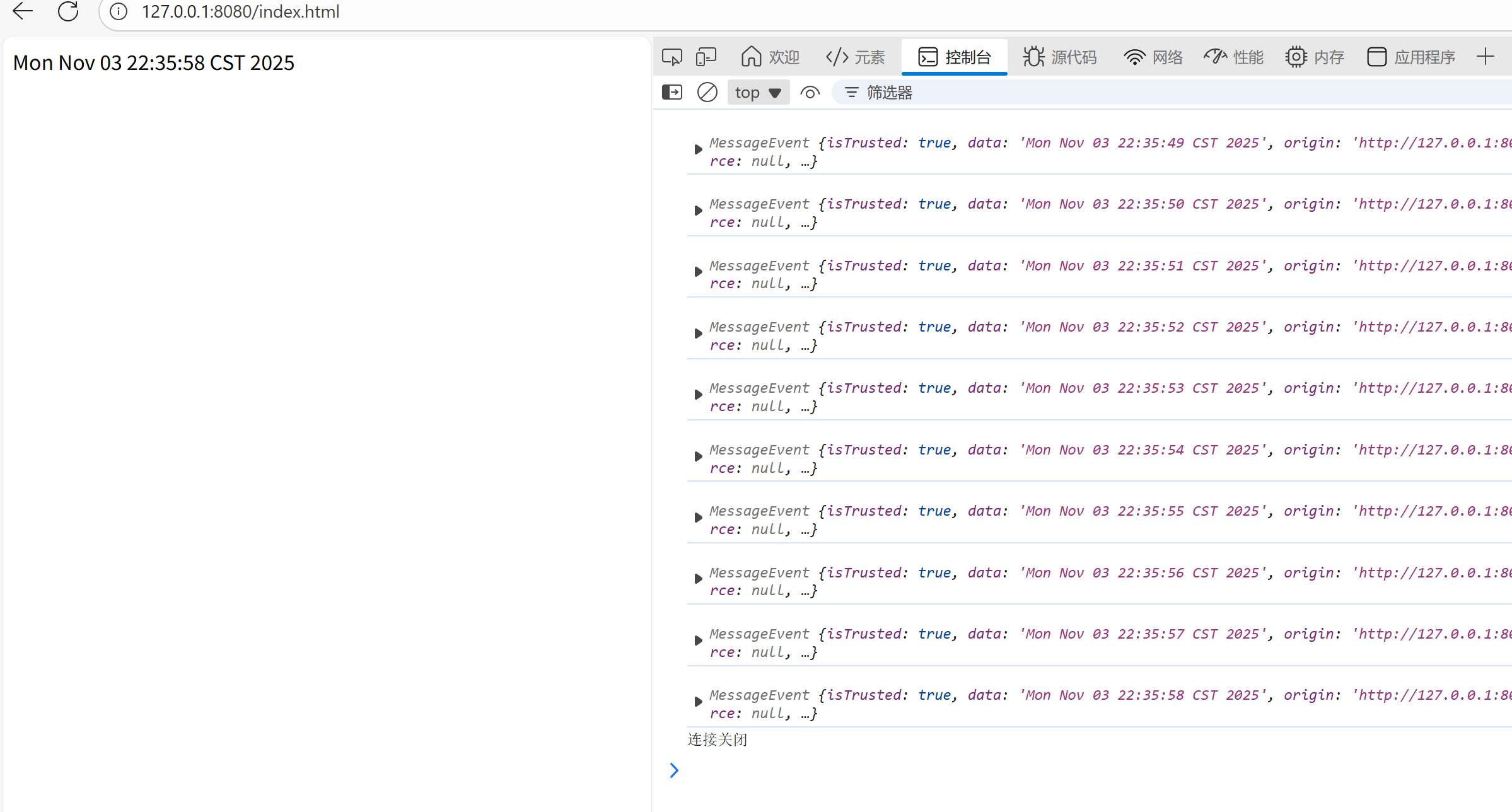
可以看到成功传输消息,并在消息传输完毕后关闭连接
而在 Spring 中,可以通过 WebFlux 优雅地实现 SSE 协议,也就是我们之前使用的 Flux,它是 WebFlux 中的核心组件,我们来看 Flux 的使用和常见操作
Flux
Flux 的使用流程:创建 → 转换 → 过滤 → 消费
创建 Flux:
import reactor.core.publisher.Flux;
// 1.1 从固定值创建
Flux<String> fixedFlux = Flux.just("Hello", "World", "!");
// 1.2 从集合创建
List<String> list = Arrays.asList("A", "B", "C");
Flux<String> fromCollection = Flux.fromIterable(list);
// 1.3 数值范围
Flux<Integer> rangeFlux = Flux.range(1, 5); // 1,2,3,4,5
// 1.4 动态生成
Flux<Long> intervalFlux = Flux.interval(Duration.ofSeconds(1)).take(5);
// 1.5 从数组创建
Flux<String> arrayFlux = Flux.fromArray(new String[]{"X", "Y", "Z"}));
// 1.6 空流
Flux<String> emptyFlux = Flux.empty();
// 1.7 从 Future 创建(适配传统异步API)
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Result");
Flux<String> futureFlux = Flux.fromFuture(future);转化操作:
// 2.1 map - 一对一转换
Flux<String> original = Flux.just("apple", "banana", "cherry");
Flux<String> uppercased = original.map(String::toUpperCase); // APPLE, BANANA, CHERRY
// 2.2 flatMap - 一对多转换(异步展平)
Flux<String> words = Flux.just("hello world", "spring ai");
Flux<String> splitWords = words.flatMap(word ->
Flux.fromArray(word.split(" "))
);
// 2.3 cast - 类型转换
Flux<Object> objects = Flux.just("text1", "text2");
Flux<String> strings = objects.cast(String.class);
// 2.4 scan - 累积计算
Flux<Integer> numbers = Flux.range(1, 4);
Flux<Integer> cumulativeSum = numbers.scan((acc, current) -> acc + current); // 1,3,6,10过滤操作:
// 3.1 filter - 条件过滤
Flux<Integer> allNumbers = Flux.range(1, 10);
Flux<Integer> evenNumbers = allNumbers.filter(n -> n % 2 == 0); // 2,4,6,8,10
// 3.2 distinct - 去重
Flux<String> withDuplicates = Flux.just("A", "B", "A", "C");
Flux<String> uniqueItems = withDuplicates.distinct()); // A,B,C
// 3.3 take - 取前 N 个
Flux<String> limited = original.take(2); // apple, banana
// 3.4 skip - 跳过前 N 个
Flux<String> skipped = original.skip(1); // banana, cherry
// 3.5 takeWhile / skipWhile - 条件取/跳
Flux<Integer> sequence = Flux.range(1, 100);
Flux<Integer> firstPart = sequence.takeWhile(n -> n < 10); // 1,2,3,...,9
// 3.6 sample - 采样(定期取最新元素)
Flux<Long> sampled = Flux.interval(Duration.ofMillis(100)))
.sample(Duration.ofSeconds(1)))
.take(3); // 每隔1秒取样,共取3次消费操作:
// 4.1 subscribe - 最基本的消费方式
Flux<String> data = Flux.just("one", "two", "three");
data.subscribe(
item -> System.out.println("Received: " + item),
error -> System.err.println("Error: " + error)),
,
() -> System.out.println("Completed!"))
);
// 4.2 collectList - 收集所有元素到 List
Mono<List<String>> listMono = data.collectList());
// 4.3 blockFirst / blockLast - 阻塞获取(仅用于测试)
// String first = data.blockFirst();
// 4.4 reduce - 归约操作
Mono<Integer> sum = numbers.reduce(0, Integer::sum));
// 4.5 count - 计数
Mono<Long> count = data.count();
// 4.6 hasElement - 检查是否有元素
Mono<Boolean> hasData = data.hasElements();
// 4.7 then - 忽略元素,只在完成后触发
Mono<Void> completionSignal = data.then();Advisors
Advisors 是 Spring AI 中的一种拦截器机制,允许我们在 AI 调用链的特定节点注入自定义逻辑。
Advisors 在两个关键的时机点介入:
Before Call(调用前):在请求发送到 AI 模型之前执行,主要用于修改提示词
After Call(调用后):在收到 AI 响应后、返回给客户端之前执行
其执行流程为:
用户输入 → Advisor1.before() → Advisor2.before() → AI 模型调用 → Advisor2.after() → Advisor1.after() → 最终响应
在 Spring AI 中内置了一些 Advisor,如 SimpleLoggerAdvisor,其主要功能是进行日志记录,只需要将其添加到 Advisor 链中,就可以自动记录 Advisor 的聊天请求和响应:
@RequestMapping("/chat")
@RestController
public class ChatClientController {
private ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.defaultSystem("你叫小小鱼,是一款专业的智能答疑AI助手,擅长Java和Python,以友好的态度来回答问题")
.build();
}
@GetMapping("/advisor")
public String advisor(String userInput) {
return this.chatClient.prompt()
.advisors(new SimpleLoggerAdvisor())
.user(userInput)
.call()
.content();
}
record Recipe(String dis, List<String> ingredients) {}
}我们将日志级别配置为 debug 来观察:
logging:
level:
org.springframework.ai.chat.client.advisor: debug
观察打印的日志内容:
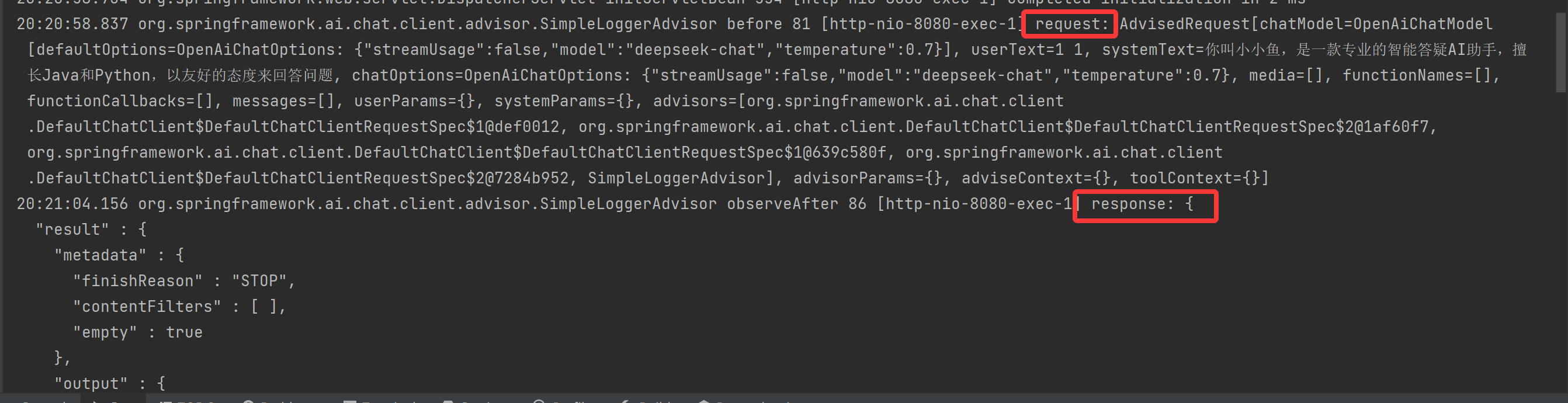
成功打印了对应的请求和响应日志。

















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









