



一个状态同步的接口,如 “将审批单状态同步到 OA 系统”,即使重复同步,目标系统可通过 “审批单 ID + 当前状态” 判断是否需要更新,重复调用不会产生异常状态。
前言
大家好,我是田螺。
最近面试了一位Java开发候选人,10年的开发经验,居然不知道接口幂等如何设计。。。
我们本文来聊聊,后端设计的一个重要原则:接口幂等性。以及什么样的接口才做幂等处理。
是否所有的接口都必须进行幂等处理呢?是否所有涉及数据变更的接口,都要做幂等处理呢?
显然不是,我们要综合考虑业务场景、数据重要程度、数据修复难易程度等,灵活判断是否需要幂等设计,避免过度设计!
- 什么是接口幂等性?
- 哪些接口必须做幂等处理
- 哪些接口可酌情不做幂等处理
- 通用方案:如何设计幂等接口?
- 幂等涉及的分布式唯一ID如何生成
- 幂等设计的核心原则
1. 什么是接口幂等性?
幂等是一个数学与计算机科学概念。
- 在数学中,幂等用函数表达式就是:
f(x) = f(f(x))。比如求绝对值的函数,就是幂等的,abs(x) = abs(abs(x))。 - 计算机科学中,幂等表示一次和多次请求某一个资源应该具有同样的副作用,或者说,多次请求所产生的影响与一次请求执行的影响效果相同。
比如说,你调用下游接口做转账,然后接口网络超时了(实际下游转账成功了),然后你用原来的流水号发起重试,如果下游接口不做幂等处理,那就会导致重复支付!
2. 哪些接口必须做幂等处理
判断接口是否需要幂等处理,核心标准是 “重复调用是否会造成业务损失或数据异常”。一般资金交易、订单相关等接口,都要实现幂等性,比如:
- 支付接口:如用户下单支付、退款、转账等接口。若未做幂等,用户重复发起支付请求,可能导致多笔扣款,引发严重的资金纠纷和用户信任危机。
- 订单创建接口:若用户因网络延迟重复提交订单,未做幂等会生成多个重复订单,不仅增加库存管理、物流配送的复杂度,还可能导致商家错发货物。
3. 哪些接口可酌情不做幂等处理
有些接口,业务场景简单、数据也相对没那么重要,重复调用概率比较小,且重复调用造成的影响也很小,则可考虑不做幂等处理,以降低开发成本和系统开销。
典型场景如内部OA系统的一些审批
内部审批单(如员工报销审批、部门采购审批)通常具备以下特点,使其无需强制幂等:
- 调用场景封闭:接口仅在企业内部系统使用,调用者是内部员工或指定系统,不存在外部用户因网络问题重复提交的高频场景。
- 按钮置灰:且内部系统通常会有前端按钮置灰、提交后跳转等逻辑,从源头减少重复调用。
- 重复影响极小:即使因异常导致审批单重复提交,后续业务流程可通过 “人工校验” 或 “状态判断” 修正,或者驳回流程(或者删除申请流程)再重新发起~
当然,并不是说这类型接口一定不做幂等处理,这个是结合你实际业务场景评估的,有些场景,幂等可以简单处理的,比如:
一个状态同步的接口,如 “将审批单状态同步到 OA 系统”,即使重复同步,目标系统可通过 “审批单 ID + 当前状态” 判断是否需要更新,重复调用不会产生异常状态。(这种方案就是状态机幂等处理)
4. 通用方案:如何设计幂等接口?
对于重要接口的幂等处理,比如转账接口,跟大家分享一种比较通用的幂等方案哈~~
日常开发中,为了实现交易接口幂等,我是这样实现的:
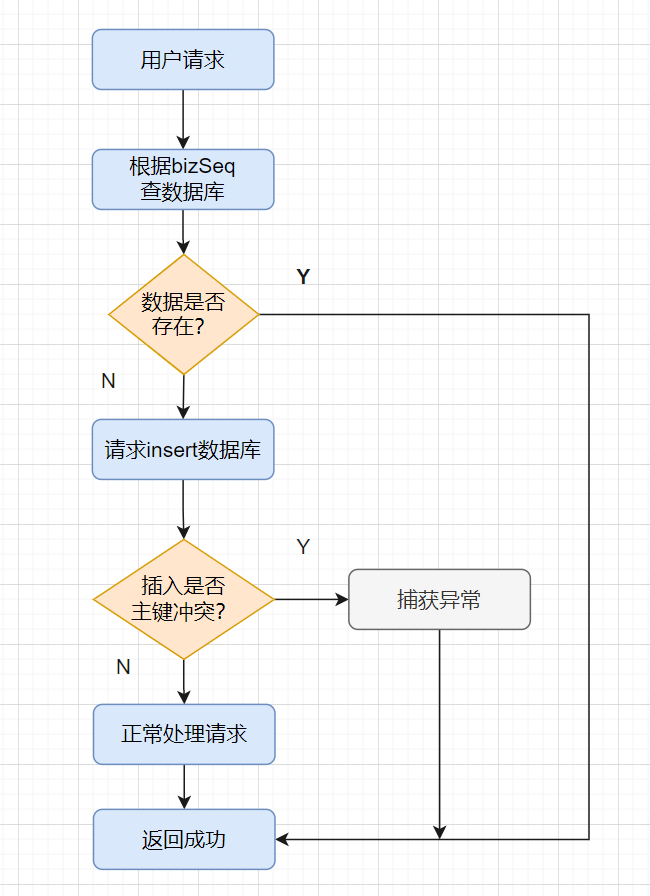
交易请求过来,我会先根据请求的唯一流水号bizSeq字段,先select一下数据库的流水表
- 如果数据已经存在,就拦截是重复请求,直接返回成功;
- 如果数据不存在,就执行
insert插入,如果insert成功,则直接返回成功,如果insert产生主键冲突异常,则捕获异常,接着直接返回成功。
流程图如下:
图片
伪代码如下:
/**
* 幂等处理
*/
Rsp idempotent(Request req){
Object requestRecord =selectByBizSeq(bizSeq);
if(requestRecord !=null){
//拦截是重复请求
log.info("重复请求,直接返回成功,流水号:{}",bizSeq);
return rsp;
}
try{
insert(req);
}catch(DuplicateKeyException e){
//拦截是重复请求,直接返回成功
log.info("主键冲突,是重复请求,直接返回成功,流水号:{}",bizSeq);
return rsp;
}
//正常处理请求
dealRequest(req);
return rsp;
}
为什么前面已经select查询了,还需要try...catch...捕获重复异常呢?
是因为高并发场景下,两个请求去
select的时候,可能都没查到,然后都走到insert的地方啦。
当然,一般都是用唯一索引代替数据库主键的哈,主要都是全局唯一的ID即可。我们之前的转账流水,幂等就是基于业务流水号作为唯一索引~~
5. 幂等涉及的分布式唯一ID如何生成
我们处理幂等的时候,就需要分布式的全局唯一ID,我们该如何去生成呢?你可以回想下,数据库主键Id怎么生成的呢?
是的,我们可以使用UUID,但是UUID的缺点比较明显,它字符串占用的空间比较大,生成的ID过于随机,可读性差,而且没有递增。
我们还可以使用雪花算法(Snowflake) 生成唯一性ID。
雪花算法是一种生成分布式全局唯一ID的算法,生成的ID称为
Snowflake IDs。这种算法由Twitter创建,并用于推文的ID。
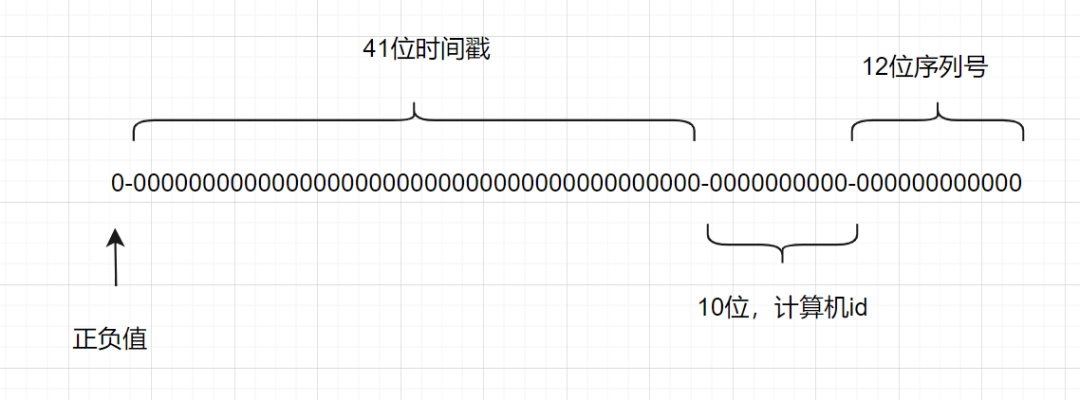
一个Snowflake ID有64位。
- 第1位:Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
- 接下来前41位是时间戳,表示了自选定的时期以来的毫秒数。
- 接下来的10位代表计算机ID,防止冲突。
- 其余12位代表每台机器上生成ID的序列号,这允许在同一毫秒内创建多个Snowflake ID。
雪花算法
当然,全局唯一性的ID,还可以使用百度的Uidgenerator,或者美团的Leaf。
6. 幂等设计的核心原则
所以,并不是所有的接口都要做幂等处理。本质是 “业务影响” 与 “成本开销” 的权衡。
- 如果是核心交易、资金相关接口,必须实现幂等,而且最好是基于流水表这种实现,用流水表去跟踪数据、数据状态的流转变化。
- 对于内部系统的一些简单接口,如审批单,幂等则可以简单处理,或者综合评估可能影响后,不做幂等处理。在 “风险控制” 与 “成本” 之间找到平衡。
我还是想强调一句:幂等设计的最终目标不是 “所有接口都实现幂等”,而是 “让关键接口安全,让简单接口高效”,以合理的设计保障系统稳定,同时避免不必要的开销。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









