



静态线程池隔离能解决大部分问题,但遇到“快接口临时变慢”(如下游DB慢查询导致下单接口从50ms变5s),还是会占用核心线程池。这时候需要更智能的方案。
前几天凌晨,某电商平台突发故障:用户下单、支付接口响应超时,大量订单卡在“待支付”状态,而后台监控显示——线程池活跃线程数100%,队列等待任务超2000个。
排查后发现:运营同学在高峰期导出“近30天销售报表”,这个慢接口单次执行要20分钟,直接占满了所有业务线程,导致支付、下单等快接口“抢不到线程”,整个核心业务链路瘫痪。
这种“快慢接口共用线程池”的资源竞争问题,几乎是分布式服务的“通病”。今天就从应急止损、架构优化、长效治理三个维度,分享一套可落地的立体化解决方案,帮你彻底杜绝这类故障。
一、核心矛盾:为什么快慢接口不能共用线程池?
在聊解决方案前,先搞懂问题根源:传统“单一线程池”模型的致命缺陷。
当所有接口(快如支付、慢如报表)共用一个线程池时,会出现“劣币驱逐良币”的现象:
- 快接口:支付、下单这类核心接口,单次执行仅50-100ms,本应快速完成并释放线程;
- 慢接口:报表导出、数据统计这类接口,依赖复杂查询或外部调用,单次执行可能10分钟甚至更久;
- 冲突结果:慢接口一旦占用线程,会“霸占”资源长达数分钟,导致线程池无空闲线程处理快接口,最终核心业务排队超时,用户体验崩溃。
这就像“高速公路上,货车占用快车道缓慢行驶,导致小轿车全被堵在后面”——不是资源不够,而是资源被错配了。
二、三层解决方案:从应急止损到长效治理
解决这个问题,不能只靠“拆分线程池”的单一手段,需要一套“隔离+优化+监控”的组合拳,分阶段落地。
第一层:应急止损——用“舱壁模式”快速切断资源竞争
这是解决线上故障的第一步,也是最关键的一步。核心思路是“物理隔离线程池”,就像轮船用密封舱防止漏水扩散一样,让慢接口的问题只局限在自己的“舱室”里。
1. 两种隔离策略(按业务优先级更推荐)
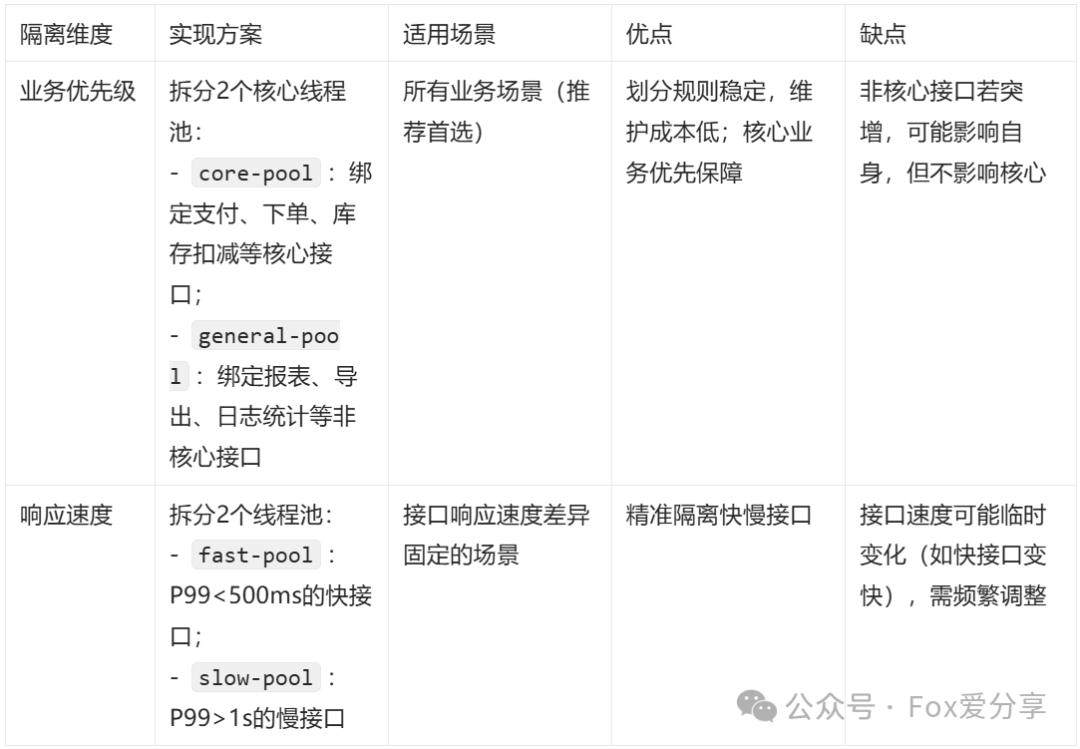
2. 线程池配置技巧(关键参数)
隔离后,线程池的配置直接影响效果,核心是“核心池给核心业务倾斜资源”:
// 1. 核心业务线程池(core-pool):优先保障响应速度
ThreadPoolExecutor corePool = new ThreadPoolExecutor(
10, // 核心线程数:根据核心接口QPS设置(如每秒100请求,设10)
20, // 最大线程数:核心线程不够时的扩容上限(避免线程过多占用CPU)
60, // 空闲线程存活时间:60秒(核心线程不回收,非核心60秒后回收)
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(50), // 阻塞队列:容量50(队列满了触发拒绝策略,避免排队过长)
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略:直接拒绝(核心业务宁可不处理,也不排队超时)
);
// 2. 非核心业务线程池(general-pool):容忍排队,不占用核心资源
ThreadPoolExecutor generalPool = new ThreadPoolExecutor(
5, // 核心线程数:非核心接口QPS低,设5足够
10, // 最大线程数:扩容上限10
30, // 空闲线程存活时间:30秒(非核心接口用得少,快速回收)
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(200), // 阻塞队列:容量200(非核心接口可容忍排队)
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略:让调用者线程执行(避免任务丢失,不影响核心)
);
3. 落地方式(Spring Boot为例)
用“自定义注解+AOP”实现接口与线程池的绑定,无需手动指定线程池:
// 1. 自定义注解:标记接口所属线程池
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ThreadPoolBind {
String value(); // 线程池名称:如"core-pool"、"general-pool"
}
// 2. AOP切面:拦截带注解的接口,用指定线程池执行
@Aspect
@Component
public class ThreadPoolAop {
// 注入两个线程池(Spring中配置为Bean)
@Autowired
private ThreadPoolExecutor corePool;
@Autowired
private ThreadPoolExecutor generalPool;
@Around("@annotation(threadPoolBind)")
public Object executeWithThreadPool(ProceedingJoinPoint joinPoint, ThreadPoolBind threadPoolBind) throws Throwable {
// 根据注解值选择线程池
ThreadPoolExecutor targetPool = "core-pool".equals(threadPoolBind.value()) ? corePool : generalPool;
// 提交任务到线程池执行
return CompletableFuture.supplyAsync(() -> {
try {
return joinPoint.proceed();
} catch (Throwable e) {
throw new RuntimeException(e);
}
}, targetPool).get(); // 若需要同步返回,用get();允许异步则直接返回Future
}
// 3. 接口使用:加注解绑定线程池
@RestController
@RequestMapping("/order")
public class OrderController {
// 核心接口:绑定core-pool
@ThreadPoolBind("core-pool")
@PostMapping("/create")
public String createOrder() {
// 下单逻辑(快接口,50ms内完成)
return "order created";
}
}
@RestController
@RequestMapping("/report")
public class ReportController {
// 非核心接口:绑定general-pool
@ThreadPoolBind("general-pool")
@GetMapping("/export")
public String exportReport() {
// 报表导出逻辑(慢接口,5分钟完成)
return "report exported";
}
}
}
第二层:架构优化——从“静态隔离”到“弹性应对”
静态线程池隔离能解决大部分问题,但遇到“快接口临时变慢”(如下游DB慢查询导致下单接口从50ms变5s),还是会占用核心线程池。这时候需要更智能的方案。
1. 动态自适应隔离(应对“临时慢接口”)
核心逻辑:用监控数据触发线程池动态切换,让临时变慢的快接口“暂时去慢接口池”,避免影响核心池。
- 步骤1:监控接口响应时间用Prometheus采集每个接口的P99响应时间(99%请求的耗时,更能反映慢请求),例如:
下单接口正常P99是100ms,阈值设为300ms(超过则判定为“临时变慢”)。
- 步骤2:配置中心动态下发规则用Nacos/Apollo配置中心维护“接口-线程池”映射规则,例如:
{
"interfaceThreadPools": [
{"interface": "/order/create", "pool": "core-pool", "p99Threshold": 300},
{"interface": "/report/export", "pool": "general-pool", "p99Threshold": 3000}
]
}
- 步骤3:应用层动态切换在AOP切面中加入“响应时间判断”,若接口连续3次P99超过阈值,自动切换到general-pool:
// AOP切面中新增逻辑
private Map<String, AtomicInteger> slowCountMap = new ConcurrentHashMap<>(); // 慢请求计数器
@Around("@annotation(threadPoolBind)")
public Object executeWithThreadPool(ProceedingJoinPoint joinPoint, ThreadPoolBind threadPoolBind) throws Throwable {
String interfaceName = joinPoint.getSignature().getDeclaringTypeName() + "." + joinPoint.getSignature().getName();
long startTime = System.currentTimeMillis();
Object result = null;
try {
// 1. 先按默认规则选择线程池
ThreadPoolExecutor targetPool = getDefaultPool(threadPoolBind.value());
// 2. 检查是否需要动态切换(从配置中心获取阈值)
Integer p99Threshold = getThresholdFromConfig(interfaceName);
AtomicInteger slowCount = slowCountMap.computeIfAbsent(interfaceName, k -> new AtomicInteger(0));
if (p99Threshold != null) {
// 3. 若历史3次都是慢请求,切换到general-pool
if (slowCount.get() >= 3) {
targetPool = generalPool;
log.warn("接口{}连续3次慢请求,切换到general-pool", interfaceName);
}
}
// 4. 执行任务
result = CompletableFuture.supplyAsync(() -> {
try {
return joinPoint.proceed();
} catch (Throwable e) {
throw new RuntimeException(e);
}
}, targetPool).get();
return result;
} finally {
// 5. 计算耗时,更新慢请求计数器
long cost = System.currentTimeMillis() - startTime;
Integer p99Threshold = getThresholdFromConfig(interfaceName);
if (p99Threshold != null && cost > p99Threshold) {
slowCountMap.get(interfaceName).incrementAndGet();
} else {
slowCountMap.get(interfaceName).set(0); // 正常请求重置计数器
}
}
}
2. 终极方案:响应式编程(从架构层面消除线程占用)
静态/动态隔离都是“被动防御”,而响应式编程能从根本上解决“线程被慢接口占用”的问题——它跳出了“1个请求对应1个线程”的阻塞模型,用“非阻塞I/O+事件循环”让线程在等待时释放资源。
- 核心原理
当接口需要等待(如DB查询、RPC调用)时,线程不会被阻塞,而是立即返回去处理其他请求;当等待结果返回后,再由空闲线程继续处理后续逻辑。例如:
下单接口调用DB查询库存(耗时200ms),线程在发起DB请求后立即释放,去处理下一个下单请求;
200ms后DB返回结果,再由某个空闲线程继续执行“扣减库存”逻辑。
- 技术栈落地(Spring WebFlux)
// 1. 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>io.r2dbc</groupId>
<artifactId>r2dbc-h2</artifactId> <!-- 非阻塞DB驱动,替代传统JDBC -->
</dependency>
// 2. 响应式接口实现(下单接口)
@RestController
@RequestMapping("/order")
public class ReactiveOrderController {
@Autowired
private ReactiveStockRepository stockRepository; // 响应式Repository
@PostMapping("/create")
public Mono<String> createOrder(@RequestBody OrderRequest request) {
// 非阻塞流程:查询库存 → 扣减库存 → 返回结果
return stockRepository.findByProductId(request.getProductId()) // 非阻塞查库,不占用线程
.flatMap(stock -> {
if (stock.getCount() < request.getNum()) {
return Mono.error(new RuntimeException("库存不足"));
}
// 扣减库存(非阻塞更新)
stock.setCount(stock.getCount() - request.getNum());
return stockRepository.save(stock)
.thenReturn("订单创建成功:" + request.getOrderId());
});
}
}
- 优势用极少数线程(如CPU核心数4,线程数4)就能支撑每秒数千请求,慢接口的“等待时间”不会占用线程,快接口完全不受影响。
第三层:长效治理——从“被动解决”到“主动优化”
隔离和架构优化能减少慢接口的影响,但最好的方案是“让慢接口变快”,并建立监控体系提前预警。
1. 慢接口主动优化(从根源减少问题)
- 强制超时控制所有慢调用(DB、RPC)必须设超时,避免线程无限等待:
// DB查询超时(MyBatis为例)
<select id="queryStock" timeout="500"> <!-- 超时500ms,超过则中断 -->
select count from stock where product_id = #{productId}
</select>
// RPC调用超时(Dubbo为例)
@Reference(timeout = 1000) // 超时1秒
private StockService stockService;
- 异步化改造非实时接口彻底异步,不占用业务线程池:
// 报表导出接口:投递任务到MQ,立即返回
@GetMapping("/export")
public String exportReport() {
String taskId = UUID.randomUUID().toString();
// 投递任务到Kafka/RabbitMQ
kafkaTemplate.send("report-export-topic", new ExportTask(taskId, "202405"));
return "导出任务已发起,任务ID:" + taskId(用户可通过任务ID查询进度);
}
// 消费者服务:独立线程池处理导出(完全不占用业务线程)
@KafkaListener(topics = "report-export-topic")
public void handleExportTask(ExportTask task) {
// 报表导出逻辑(耗时10分钟也没关系)
reportService.export(task.getDate(), task.getTaskId());
}
- 根源性能优化
DB层面:慢查询加索引(如ALTER TABLE stock ADD INDEX idx_product_id (product_id))、拆分大表、用分页替代全量查询;
缓存层面:热点数据用Redis缓存(如商品库存),减少DB查询;
外部依赖:第三方接口慢则加本地缓存或降级(如天气接口超时返回默认值)。
2. 监控告警体系(提前发现风险)
- 核心监控指标(每个线程池独立监控):

- 落地工具:Prometheus + Grafana + AlertManager:
用micrometer采集线程池指标,暴露给Prometheus;
Grafana创建“线程池监控面板”,直观展示每个池的活跃线程、队列等待数;
AlertManager配置告警规则,当指标超过阈值时,通过企业微信/钉钉通知工程师。
三、总结:分阶段落地建议
面对“快慢接口资源竞争”问题,不用追求一步到位,可按以下阶段落地:
- 紧急阶段(1-2天)用舱壁模式拆分线程池,按业务优先级绑定核心/非核心接口,快速止损,保证核心业务稳定。
- 优化阶段(1-2周)为慢接口加超时、异步化改造,引入动态隔离(监控+配置中心),应对“临时慢接口”问题。
- 长期阶段(1-3个月)试点响应式编程(如非核心接口先迁移),建立完善的监控告警体系,定期优化慢接口,从根源杜绝问题。
通过这套“隔离+优化+监控”的方案,不仅能解决眼前的线程池资源竞争问题,还能让系统架构更弹性、更健壮,从容应对高并发场景下的各种挑战。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 1748
1748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









