



无论是Gemini、Perplexity还是OpenAI,现有的DRTs主要采用僵化的研究策略,除研究提示词外几乎不留用户定制空间;而在具有LLM代理的DRTs中,往往存在底层模型选择单一、或仅使用训练后行为特征相同的同系列模型的问题。
英伟达也做深度研究智能体了。
最新论文介绍了英伟达的通用深度研究(UDR)系统,该系统支持个人定制,可接入任何大语言模型(LLM)。

这意味着它能够围绕任何语言模型运行,用户可以完全自定义深度研究策略,并交给智能体实现。
为展示其通用性,英伟达还为UDR配备了带用户界面的研究演示原型,可在GitHub上下载。
网友认为,它使智能体的自主性得到了突破,非常适合企业工作。

自带模型和策略
论文介绍,以往推出的所有深度研究智能体,都采用硬编码方式,仅能通过固定的工具选择来执行特定研究策略。
而英伟达的UDR系统能够围绕任何LLM运行。
还能使用户能够在无需额外训练或微调的情况下,创建、编辑和优化他们完全自定义的深度研究策略。
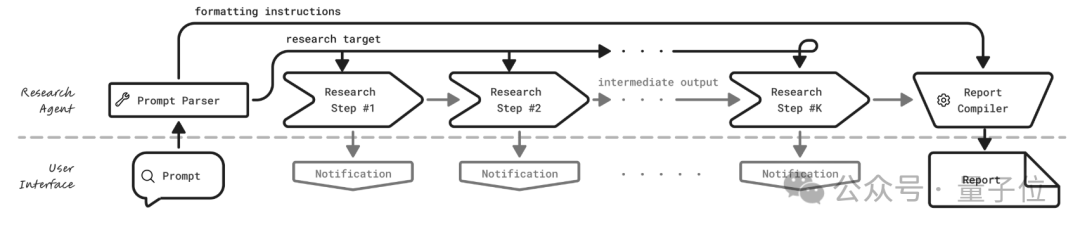
上图呈现的是一个典型深度研究工具(DRT)的组成部分,与普通的对话式LLMs不同,DRTs在生成报告之前倾向于持续向用户更新其进度。
一个DRT由两部分组成:
- 一个简单的用户界面:用于接收研究提示,持续向用户更新研究进度,并显示研究报告;
- 代理逻辑:代码代理(通过代码协调大语言模型与工具的组合运用)或LLM代理(直接利用模型自身的推理和工具调用能力)。
无论是Gemini、Perplexity还是OpenAI,现有的DRTs主要采用僵化的研究策略,除研究提示词外几乎不留用户定制空间;而在具有LLM代理的DRTs中,往往存在底层模型选择单一、或仅使用训练后行为特征相同的同系列模型的问题。
虽然这个问题并不是阻碍DRTs广泛流行的障碍,但它从三个方面限制了它们的实用性:
- 用户既不能自主设置资源优先级,也无法自动验证信息的权威性,更无法控制搜索成本。
- 现有的DRTs做不出高价值行业需要的专业文档分析方案。
- 现有的DRTs使用的模型是不可换的——用户不能随意将最新或最强大的模型与深度研究智能体组合起来,以产生一个更强大的DRT。
而英伟达的UDR系统提出了一种通用的解决方案来解决上述问题。
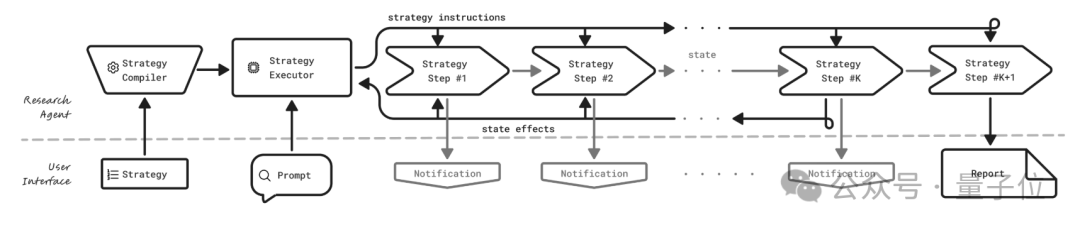
简单地说,与专门的DRT不同,UDR从用户那里接收研究策略和研究提示,允许更高的定制程度。
UDR能够将策略从自然语言编译成可执行的研究编排代码片段,然后执行策略,并将最终报告交付给用户。
其最显著的创新特性包括:
- 通过自然语言定制研究策略。UDR支持用户用自然语言定义和编程自己的研究工作流,系统会将其转换为可执行、可审计的代码。
这意味着用户自己设计的智能操作流程,不需要重新训练AI模型或进行复杂调试,就能直接投入实际使用。
- 与模型无关的研究工具架构。UDR将研究逻辑与语言模型解耦,使开发者能够将任何大语言模型——无论供应商或架构如何——封装成功能完整的深度研究工具。
这样一来,产品设计就有了更大发挥空间:既能选用最先进的AI模型,又能搭配量身定制的研究方案,实现灵活组合的创新应用。
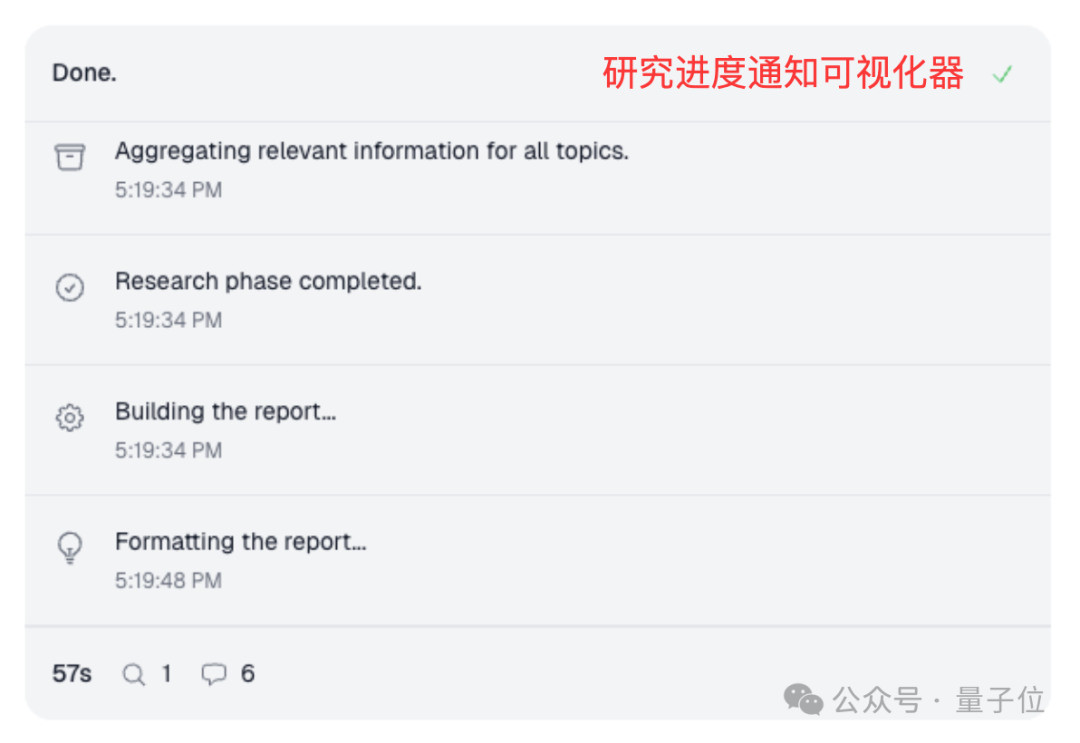
- 用户可控的策略驱动研究界面。下图的原型展示了四大实用功能:实时修改研究策略、选择预设策略库、接收进度通知、查看分析报告。


UDR通过区分控制逻辑和语言模型推理来提升计算效率:整个深度研究流程的调度由生成的代码全权负责,这些代码直接在CPU上运行,避免了成本高出数十倍的语言模型推理开销。
系统仅在用户自定义研究策略明确要求时才会调用LLM,且每次调用仅处理代码变量中存储的精简定向文本片段。
这种双重高效设计——将流程调度交给CPU执行逻辑,同时将LLM的使用严格限定在精准高效的调用中——不仅能够降低GPU资源消耗,还可以显著减少深度研究任务的总体执行延迟和成本。
仍需进一步探索
不过,这项工作目前还存在一定的局限性。
一方面,UDR系统执行研究策略的准确度,完全取决于底层AI模型生成代码的质量。虽然研究人员通过强制要求代码添加注释来减少错误,但当策略表述模糊或不够具体时,系统偶尔还是会产生理解偏差或逻辑错误。
另一方面,UDR默认用户设计的研究策略本身是合理且可执行的。系统只会做基础检查,不会判断策略步骤是否真正有效。如果策略设计得不好,最终生成的报告可能质量低下、内容不全,或者根本生成不出报告。
此外, 还有一点在于,虽然UDR会实时显示研究进度,但当前版本在执行过程中不支持用户干预(只能停止任务),也无法根据实时反馈调整研究方向。
所有决策都需要在研究开始前就预先设定好,这使得长时间或探索性的研究任务缺乏灵活性。
针对上述问题,研究人员也提出了进一步的解决方案——或者说改进方案:
比如配备可修改定制的研究策略库、进一步探索如何让用户控制语言模型的自由推理过程、将大量用户提示自动转化为确定性控制的智能体等。

目前英伟达的UDR系统还只是原型阶段,并未正式推出,但或许可以期待一下。
期待一个功能完整的正式版本。
参考链接
[1]https://x.com/rohanpaul_ai/status/1964689864244203596
[2]https://research.nvidia.com/labs/lpr/udr/
[3]https://github.com/NVlabs/UniversalDeepResearch
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 1979
1979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









