



保持forward方法的纯净性,确保所有操作基于张量计算。避免使用.item()方法和Python端的条件分支逻辑。根据需要启用动态形状支持功能。构建单一的大型计算图是后端优化系统实现最佳性能的关键前提。
PyTorch 2.0+引入的torch.compile功能通过图捕获和优化技术显著提升模型执行性能。该功能将模型转换为计算图形式,并对其进行深度优化。
PyTorch采用eager execution作为默认执行模式,即每个操作在Python中逐行立即执行。这种模式提供了出色的灵活性和调试便利性,但在性能表现上存在优化空间。
PyTorch 2.0引入的torch.compile实现了即时编译(Just-In-Time, JIT)的图捕获和优化机制。该系统的底层架构采用TorchDynamo进行模型跟踪,生成FX图表示,随后将图传递给AOTAutograd和Inductor等后端系统执行内核融合和代码生成优化。
本文将深入分析TorchDynamo的工作机制,而非全面探讨所有后端实现。我们将从,模式的下一层次入手,详细阐述TorchDynamo的功能特性。同时我们将深入探讨图中断(graph breaks)和多图问题对性能的负面影响,并分析PyTorch模型开发中应当避免的常见错误模式。
TorchDynamo的核心价值
PyTorch的默认eager模式采用即时执行策略,每个操作在Python环境中立即执行。torch.compile通过TorchDynamo实现程序到FX图的捕获转换。
FX图是一种中间表示形式,包含一系列操作序列,如线性层执行、ReLU激活函数应用、矩阵乘法等,采用低级别的中间表示格式。Inductor等后端系统接收此图结构,并将其优化为高效的融合内核实现。
可通过以下代码查看捕获过程的详细信息:
import torch
import torch.nn as nn
import torch._dynamo as dynamo
class Simple(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(4, 2)
def forward(self, x):
return torch.relu(self.fc(x))
model = torch.compile(Simple())
x = torch.randn(1, 4)
print(dynamo.explain(model, x))
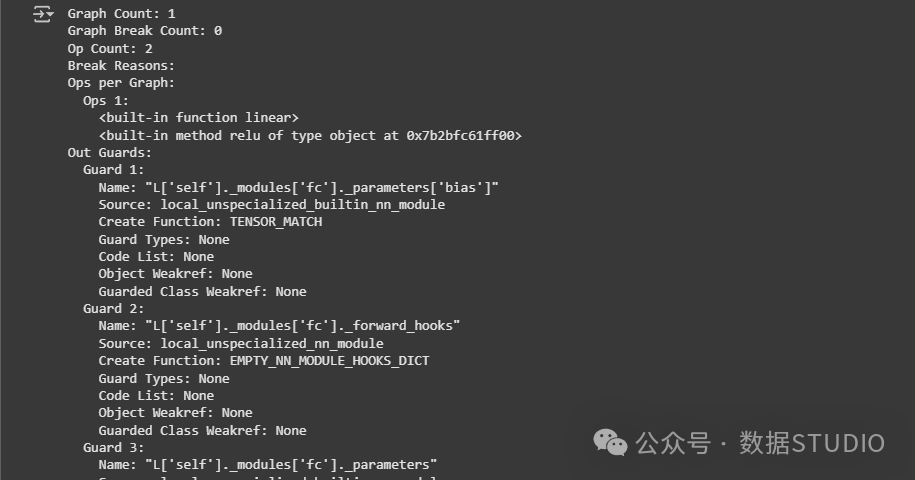
图中断机制分析
图中断发生于TorchDynamo遇到不受支持的Python代码结构时,典型情况包括.item()调用、print()语句或列表修改操作。图中断触发时会产生以下行为:
Dynamo终止当前跟踪过程,切换至eager模式执行不支持的代码段。中断点之后重新开始新的图构建过程。
理想执行状态(高性能):
Graph Count: 1
Graph Break Count: 0
问题执行状态(性能受损):
Graph Count: 2
Graph Break Count: 1
多图问题对性能影响
即便未出现显式图中断,某些情况下仍可能产生多个独立图。当模型包含基于张量值的条件分支时,Dynamo会为每个执行路径生成独立的计算图。
多图架构导致性能问题的根本原因包括:每个图需要独立编译过程,产生额外的计算开销。较小规模的图限制了内核融合优化的范围和效果。图数量增加直接导致保护机制、重编译过程增多,降低性能可预测性。图中断的影响更为严重,因为通常涉及GPU到CPU的强制同步操作(如.item()调用),而无论是中断还是分支都会破坏执行流程的连续性。
优化目标是构建单一的大型计算图,避免不必要的中断。
常见问题模式与解决方案
以下分析几种典型的初学者易犯错误,每个示例包含问题代码和相应的torch._dynamo.explain输出结果。
1、张量条件判断的Python实现
import torch
import torch.nn as nn
import torch._dynamo as dynamo
class BadIf(nn.Module):
def __init__(self):
super().__init__()
self.h = nn.Linear(16, 16)
def forward(self, x):
if torch.rand(1) > 0.5: # Python if on tensor
return self.h(x) + 1
else:
return self.h(x) - 1
x = torch.randn(4, 16)
print(dynamo.explain(BadIf(), x))
执行结果:
Graph Count: 2
Graph Break Count: 0
优化实现 — 张量原生操作
class GoodWhere(nn.Module):
def __init__(self):
super().__init__()
self.h = nn.Linear(16, 16)
def forward(self, x):
y = self.h(x)
return torch.where(torch.rand(1) > 0.5, y + 1, y - 1)
x = torch.randn(4, 16)
print(dynamo.explain(GoodWhere(), x))
执行结果:
Graph Count: 1
Graph Break Count: 0
2、 .item()方法的性能陷阱
比如forward方法内日志记录
class LogInsideForward(nn.Module):
def __init__(self):
super().__init__()
self.h = nn.Linear(16, 1)
def forward(self, x):
y = self.h(x)
m = y.mean().item() # 强制GPU→CPU同步
return y
x = torch.randn(8, 16)
print(dynamo.explain(LogInsideForward(), x))
执行结果:
Graph Count: 1
Graph Break Count: 1
优化:外部日志处理
class ReturnTensorForLog(nn.Module):
def __init__(self):
super().__init__()
self.h = nn.Linear(16, 1)
def forward(self, x):
y = self.h(x)
return y, y.mean().detach()
x = torch.randn(8, 16)
print(dynamo.explain(ReturnTensorForLog(), x))
执行结果:
Graph Count: 1
Graph Break Count: 0
- 1.
- 2.
3、Python循环结构优化
class BadLoop(nn.Module):
def forward(self, x):
out = x
for i in range(5): # Python loop
out = out + i
return out
x = torch.randn(32, 16)
print(dynamo.explain(BadLoop(), x))
TorchDynamo需要对每次迭代进行独立跟踪。
向量化计算优化
class GoodVectorized(nn.Module):
def forward(self, x):
return x + torch.arange(5, device=x.device).sum()
x = torch.randn(32, 16)
print(dynamo.explain(GoodVectorized(), x))
执行结果:
Graph Count: 1
Graph Break Count: 0
4、形状依赖分支处理
class BadShapeBranch(nn.Module):
def __init__(self):
super().__init__()
self.a = nn.Linear(16, 16)
self.b = nn.Linear(32, 16)
def forward(self, x):
if x.shape[1] == 16: # Python check
return self.a(x)
else:
return self.b(x)
x1 = torch.randn(8, 16)
print(dynamo.explain(BadShapeBranch(), x1))
x2 = torch.randn(8, 32)
print(dynamo.explain(BadShapeBranch(), x2))
不同输入形状会触发新的图生成过程。
动态形状支持优化
class GoodDynamic(nn.Module):
def __init__(self):
super().__init__()
self.h = nn.Linear(16, 16)
def forward(self, x):
return self.h(x)
model = GoodDynamic()
compiled = torch.compile(model, dynamic=True)
x1 = torch.randn(8, 16)
x2 = torch.randn(16, 16)
print(dynamo.explain(model, x1))
print(dynamo.explain(model, x2))
执行结果:
Graph Count: 1
Graph Break Count: 0
总结
图中断的触发条件是Dynamo遇到不受支持的Python代码结构。张量上的条件分支虽然不会产生图中断,但仍会导致多个小规模图的生成。图数量的增加直接降低了内核融合效率并增加了系统开销。.item()方法调用的性能代价特别高昂,因为它强制执行GPU到CPU的数据同步操作。
优化建议:保持forward方法的纯净性,确保所有操作基于张量计算。避免使用.item()方法和Python端的条件分支逻辑。根据需要启用动态形状支持功能。构建单一的大型计算图是后端优化系统实现最佳性能的关键前提。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量


















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









