




AGENTSNET首次将分布式计算理论引入多智能体评估,构建可扩展至100+智能体的科学测试框架。研究显示:当前最佳AI团队在16节点网络后性能断崖式下跌,Vertex Cover任务难度远超预期。本文深度解析多智能体协作的理论边界与实践启示,为构建真正智能的AI团队提供指南。

大家好,我是肆〇柒。今天我想和大家分享一个有趣的研究成果——AGENTSNET,这是一个帮助我们系统评估和改进AI智能体如何协作的新框架(一个 benchmark 基准)。你可能已经体验过像ChatGPT这样的单个AI助手,但如果多个AI一起工作,它们能完成什么更复杂的任务?AGENTSNET就是用来测试和改进这种多AI协作能力的"理论化考试系统"。通过这项研究,希望未来的AI团队能像人类团队一样高效协作,形成跨域的 Agent 群体智能。
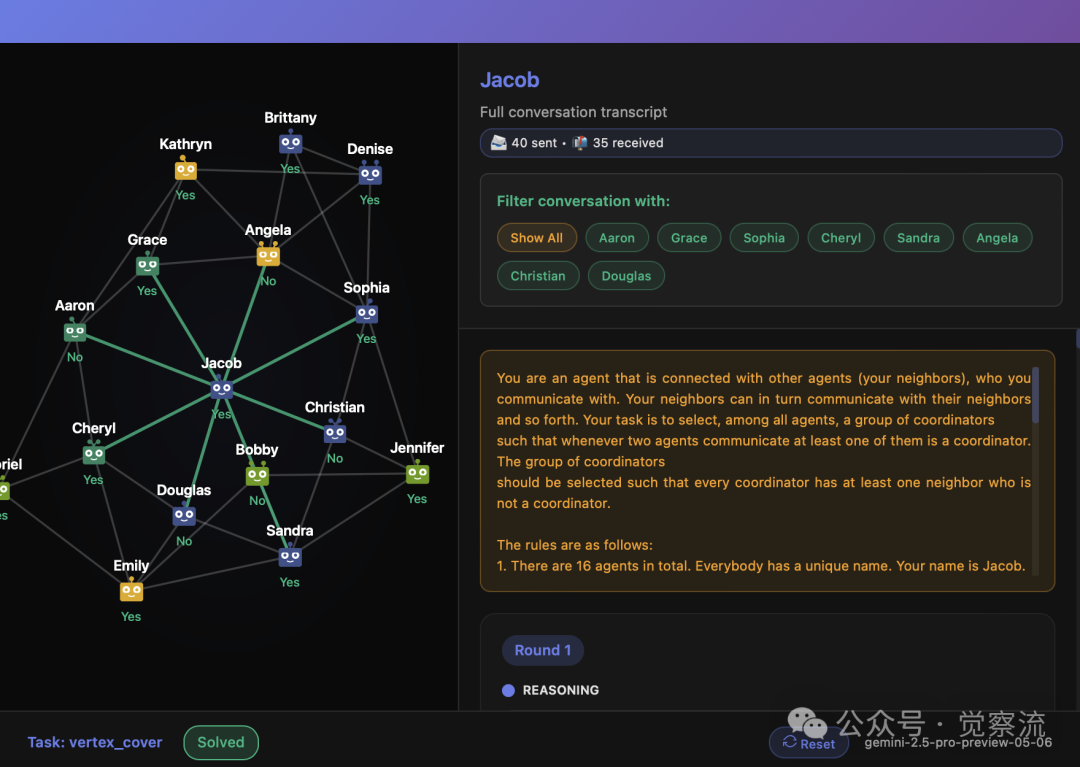
AGENTSNET Demo
AGENTSNET关键发现
- 规模瓶颈:当前最佳模型在100节点网络中性能接近零
- 任务难度:Vertex Cover是最难任务,最佳模型仅40%成功率
- 规模效应:网络规模每翻倍,任务成功率平均下降30%
- 失败模式:智能体常因策略协调延迟和信息过时导致失败
- 成本效益:Gemini 2.5 Flash性能接近Claude 3.7 Sonnet但成本低约20倍
研究背景:多智能体系统评估的范式转变
为什么我们需要关注AI之间的协作?
我们不妨假象以下,现在有个聪明的的 AI个人助理,它可以回答你的问题、帮你写邮件、规划行程。但如果这个助理还能与其他专业AI协作——比如一个负责数据分析,一个精通法律,一个擅长创意写作——那么它能解决的问题将远远超出单个AI的能力范围。这就是多智能体协作的魅力所在。
然而,要让多个AI有效协作并非易事,就像组建一个高效的人类团队一样,需要良好的沟通机制和协调能力。现有基准的局限性显而易见。当前的多智能体评估框架通常仅覆盖2-5个智能体,无法真正测试大规模网络中的协调能力。正如研究指出:"现有基准无法评估多智能体系统的核心能力:可扩展协调、去中心化通信和协作推理"。
AGENTSNET的突破性价值在于其可扩展性。与现有基准局限于2-5个智能体不同,AGENTSNET可以扩展到100+智能体的网络规模。这种可扩展性不仅使其能够测试当前模型的极限,还为未来更强大的模型预留了评估空间。研究者指出:"AGENTSNET实际上不受规模限制,可以随着新一代LLM的出现而扩展"。这种前瞻性设计可以让AGENTSNET成为多智能体研究领域的长期基准。
为什么分布式计算理论是评估多智能体协作的黄金标准?
一句话定义:分布式计算理论提供了经过数十年验证的"协作规则",这些规则确保大规模系统中的组件能够有效协同工作。
技术解释:AGENTSNET基于分布式计算中的LOCAL模型,这是分布式系统理论的核心框架。在LOCAL模型中,每个节点只能与直接邻居通信,且所有节点同步决策。这种设计精确模拟了真实世界信息传播的局部性和时延特性——就像人类团队中,每个人只能与左右邻座同事交流,而非立即知晓整个团队的信息。
生活类比:这就像一个大型会议,每个人只能与左右邻座交流,要达成全体共识需要经过多轮传递。LOCAL模型的理论复杂度界限(如Ω(log*n))为我们提供了评估多智能体系统性能的理论基准。
至此思考一个问题:为什么认为评估多智能体系统需要理论基础,而非仅靠任务完成度?因为部分正确通常不意味着成功协调。就像在Vertex Cover任务中,多数节点可能偶然选择了"协调器",但只有完全正确的解才能满足任务规范。
方法论创新:AGENTSNET的理论根基
AGENTSNET的核心创新在于将分布式计算中的经典问题转化为多智能体协调能力的测试任务。研究团队精心选择了五个具有坚实理论基础的问题,每个问题都代表了协调能力的不同维度:
五大核心任务
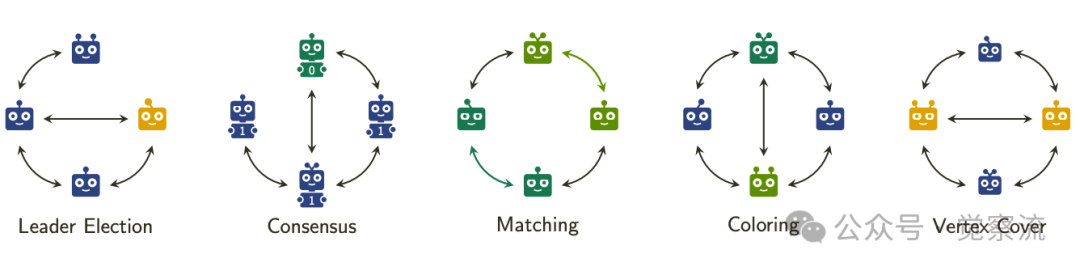
AGENTSNET任务概览
上图清晰展示了AGENTSNET的五大核心任务:在LEADERELECTION中,任务是选择网络中的单一领导者;在CONSENSUS中,任务是让所有智能体就特定值(如0或1)达成一致;在MATCHING中,任务是让智能体成对组队而不产生冲突;在COLORING中,任务是让智能体选择分组,确保相邻智能体不在同一组;在VERTEXCOVER中,任务是找到最小的"协调器"智能体组,确保每个智能体至少有一个协调器邻居。
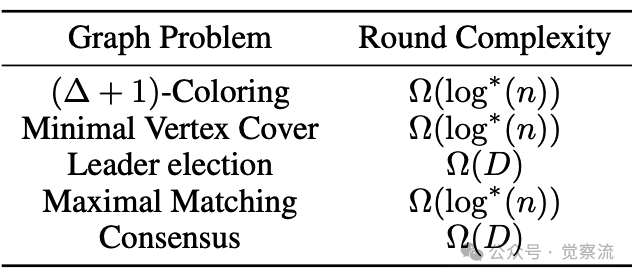
分布式计算理论问题概览
上表展示了形成AGENTSNET基础的分布式计算理论问题,以及它们在随机化LOCAL模型中的(不一定紧致的)轮次复杂度理论下界。这些理论复杂度为评估多智能体系统提供了客观基准。
1.Graph Coloring:要求相邻节点颜色不同,对应多智能体系统中的角色分配问题。
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









