



今天我想把这块魔术板拆开来给你看个究竟:如何把单头注意力改成多头注意力,让每个头能学会自己的注意力分布。

大家好,我是写代码的中年人!
自注意力(Self-Attention)是大模型里最常让人“眼花”的魔术道具:看起来只是一堆矩阵乘法和 softmax,可是组合起来就能学到“句子里谁重要、谁次要”的规则,甚至能学到某些头只盯标点、某些头专盯主谓关系。
今天我想把这块魔术板拆开来给你看个究竟:如何把单头注意力改成多头注意力,让每个头能学会自己的注意力分布。
01、回顾单头自注意力机制
假设你在开会,桌上有一堆文件,你想找跟“项目进度”相关的内容。
你心里有个问题(Query):“项目进度在哪儿?
”每份文件上有个标签(Key),写着它的主题,比如“预算”“进度”“人员”。
你会先挑出标签里跟“进度”相关的文件(匹配),然后重点看这些文件的内容(Value),最后把这些内容总结成你的理解。
自注意力就像是给每个词都做了一次这样的“信息筛选和总结”,让每个词都能根据上下文更好地表达自己。
02、理解多头自注意力机制
继续用开会的场景:
桌上还是那堆文件(代表句子里的词),但现在你不是一个人干活,而是找了3个助手(假设3头注意力)。每个助手都有自己的“专长”,他们会从不同的角度问问题、匹配标签和提取内容。
每个头独立工作(多视角筛选):
头1(进度专家):他的问题(Query)是“进度怎么样?”他只关注标签里跟“进度”“时间表”相关的文件,忽略其他。挑出匹配的文件后,他总结出一份“进度报告”。
头2(预算专家):他的问题是“预算超支了吗?”他匹配标签里的“预算”“开销”,然后从那些文件的内容里提炼“预算分析”。
头3(风险专家):问题是“有什么隐患?”他找“风险”“问题”相关的标签,输出一份“风险评估”。
每个头都像单头注意力一样:生成自己的问题、钥匙和内容,计算匹配度,加权总结。但他们用的“眼镜”不同(在机器里,这通过不同的线性变换实现),所以捕捉的信息侧重点不一样。
把多头结果合起来(综合决策):
一旦每个头都给出自己的总结,你就把这些报告拼在一起(或简单平均一下),形成一份完整的“项目概览”。现在,你的理解不只是“进度”,而是进度+预算+风险的全方位视图。万一某个头漏了什么,其他头能补上,确保没死角。
03、用代码实现多头自注意力机制
# ONE
我们使用水浒传的内容进行演示,使用前三回各 100 字的文本,并按“字”切分成模型可用的格式。
复制
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# ====== 准备水浒传真实语料 ======
raw_texts = [
"話說大宋仁宗天子在位,嘉祐三年三月三日五更三點,天子駕坐紫宸殿,受百官朝賀。但見:祥雲迷鳳閣,瑞氣罩龍樓。含煙御柳拂旌旗,帶露宮花迎劍戟。天香影裏,玉簪珠履聚丹墀。仙樂聲中,繡襖錦衣扶御駕。珍珠廉卷,黃金殿上現金輿。鳳尾扇開,白玉階前停寶輦。隱隱凈鞭三下響,層層文武兩班齊。",
"那高俅在臨淮州,因得了赦宥罪犯,思鄉要回東京。這柳世權卻和東京城里金梁橋下開生藥鋪的董將士是親戚,寫了一封書札,收拾些人事盤纏,赍發高俅回東京,投奔董將士家過活。",
"話說當時史進道:「卻怎生是好?」朱武等三個頭領跪下答道:「哥哥,你是乾淨的人,休為我等連累了大郎。可把索來綁縛我三個,出去請賞,免得負累了你不好看。」"
]
# ====== 按字切分 ======
def char_tokenize(text):
return [ch for ch in text if ch.strip()] # 去掉空格、换行
sentences = [char_tokenize(t) for t in raw_texts]
# 构建词表
vocab = {}
for sent in sentences:
for ch in sent:
if ch not in vocab:
vocab[ch] = len(vocab)
# ====== 转成索引形式并做 padding ======
max_len = max(len(s) for s in sentences)
PAD_TOKEN = "<PAD>"
vocab[PAD_TOKEN] = len(vocab)
input_ids = []
for sent in sentences:
ids = [vocab[ch] for ch in sent]
# padding
ids += [vocab[PAD_TOKEN]] * (max_len - len(ids))
input_ids.append(ids)
input_ids = torch.tensor(input_ids) # (batch_size, seq_len)
# ====== 多头自注意力模块 ======
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.1):
super().__init__()
assert embed_dim % num_heads == 0, "embed_dim 必须能整除 num_heads"
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
self.dropout = dropout
self.last_attn_weights = None # 保存最后一次注意力权重 (batch, heads, seq, seq)
def forward(self, x):
B, T, C = x.size()
Q = self.q_proj(x).view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
K = self.k_proj(x).view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
V = self.v_proj(x).view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn_weights = F.softmax(scores, dim=-1)
attn_weights = F.dropout(attn_weights, p=self.dropout, training=self.training)
self.last_attn_weights = attn_weights.detach() # (B, heads, T, T)
out = torch.matmul(attn_weights, V)
out = out.transpose(1, 2).contiguous().view(B, T, C)
out = self.out_proj(out)
return out
# ====== 模型训练 ======
embed_dim = 32
num_heads = 4
vocab_size = len(vocab)
embedding = nn.Embedding(vocab_size, embed_dim)
model = MultiHeadSelfAttention(embed_dim, num_heads)
criterion = nn.MSELoss()
optimizer = optim.Adam(list(model.parameters()) + list(embedding.parameters()), lr=1e-3)
epochs = 200
for epoch in range(epochs):
model.train()
x = embedding(input_ids)
target = x.clone()
out = model(x)
loss = criterion(out, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f"Epoch {epoch+1:3d}, Loss: {loss.item():.6f}")
# ====== 可视化注意力热图 ======
for idx, sent in enumerate(sentences):
attn = model.last_attn_weights[idx] # (heads, seq, seq)
sent_len = len(sent)
for head in range(num_heads):
plt.figure(figsize=(8, 6))
plt.imshow(attn[head, :sent_len, :sent_len].numpy(), cmap='viridis')
plt.title(f"第{idx+1}句 第{head+1}头 注意力矩阵")
plt.xticks(ticks=np.arange(sent_len), labels=sent, rotatinotallow=90)
plt.yticks(ticks=np.arange(sent_len), labels=sent)
plt.xlabel("Key (字)")
plt.ylabel("Query (字)")
plt.colorbar(label="Attention Strength")
for i in range(sent_len):
for j in range(sent_len):
plt.text(j, i, f"{attn[head, i, j]:.2f}", ha="center", va="center", color="white", fnotallow=6)
plt.tight_layout()
plt.savefig(f"attention_sentence{idx+1}_head{head+1}.png")
plt.close()
print("注意力热图已保存。")
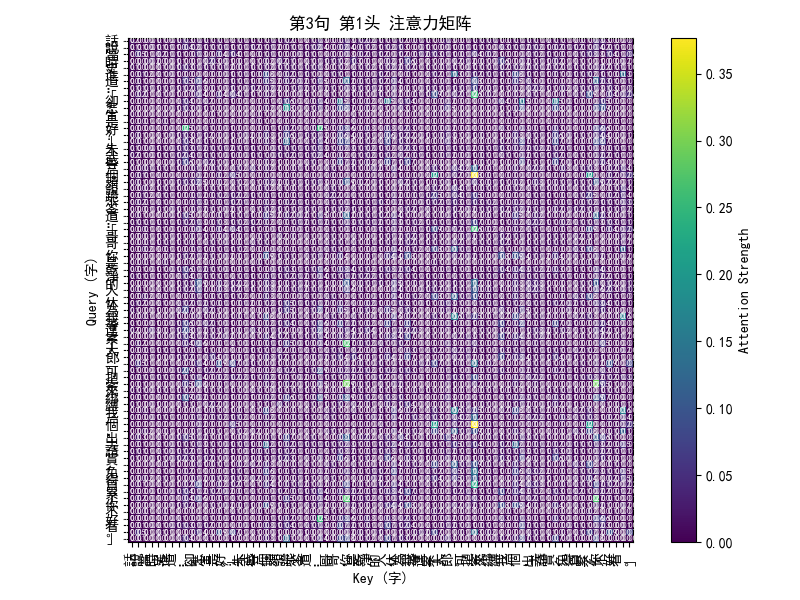
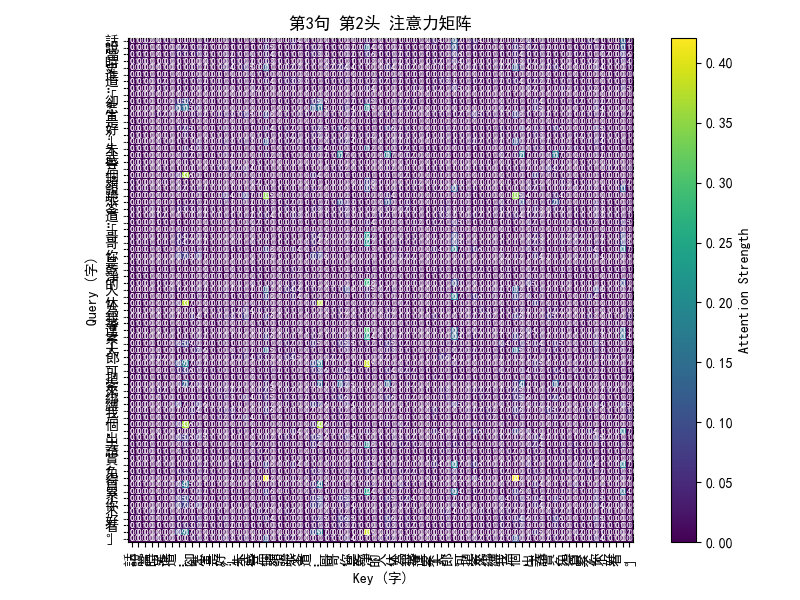
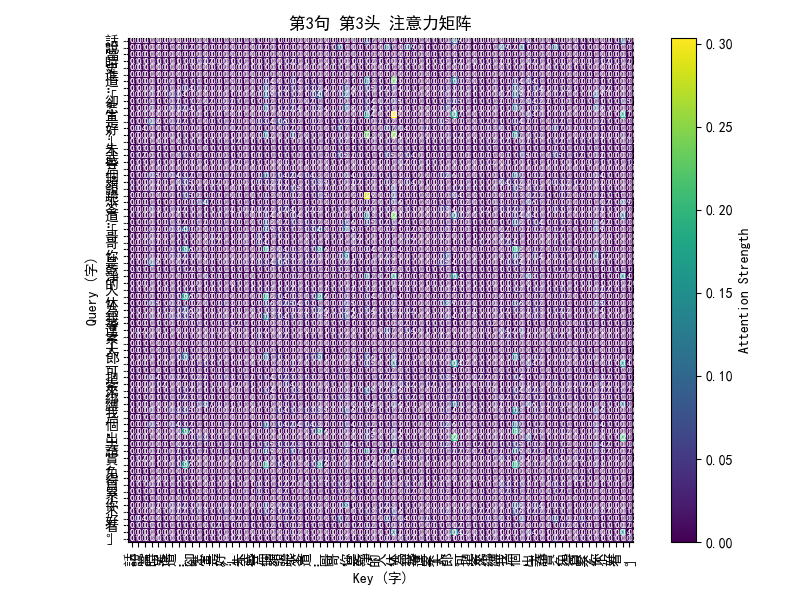
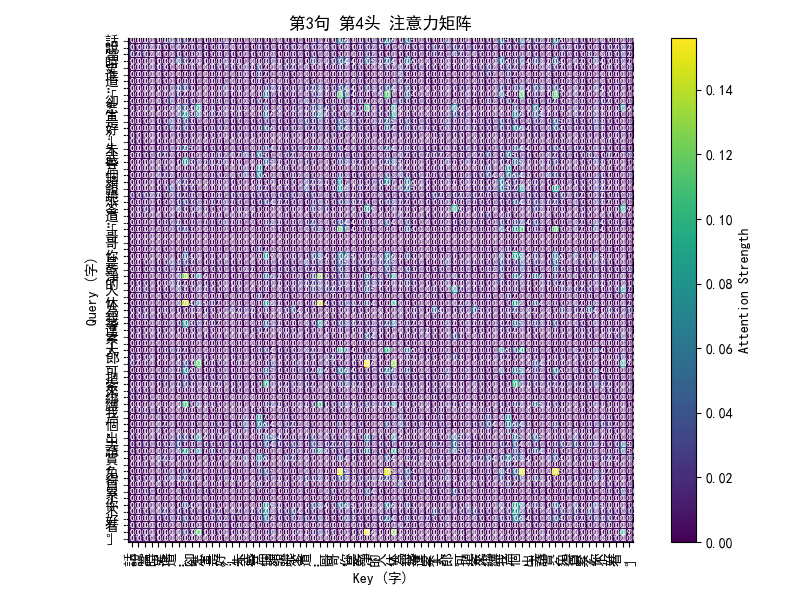
这些多头自注意力(Multi-Head Self-Attention)的热图,其实是一个“谁在关注谁”的可视化工具,用来直观展示模型在处理文本时的注意力分布。
热图上的颜色:
横轴(Key):表示句子中被关注的字,
纵轴(Query):表示当前在思考的字,
颜色深浅:表示注意力强度,越亮的地方代表这个 Query 在计算时更关注这个 Key。
例如,如果“宋”字在看“天”字时颜色很亮,说明模型觉得“天”这个字对理解“宋”有重要信息。因为是古文,有时模型会捕捉到常见的修辞搭配,比如“天子”“鳳閣”,这时候相邻的字之间注意力会很高。
为什么会有多张图:
每一行热图对应一句文本(水浒前三回的一个片段)
每句话会画多个头的热图:
多头机制的设计就是让不同的头学习到不同的关注模式
举个例子:
Head 1 可能更多关注相邻的字(局部模式)
Head 2 可能更关注句首或特定关键词(全局模式)
Head 3 可能专注某个语法结构
Head 4 可能专注韵律、排比等古文特性
多头机制就像多双眼睛,从不同角度观察同一句话。
举个大家都能理解的例子:
学生(Query):举手发言
老师(Attention):环顾四周,看看应该关注哪个学生(Key)
不同的老师(Head)关注点不同:一个老师喜欢看前排学生(局部依赖)一个老师总是看坐在角落的安静同学(远距离依赖)还有老师会特别注意那些名字里有“天”“龙”这些关键字的学生
(关键触发词)颜色越亮,表示老师对这个学生说的话越感兴趣。
结束语
回到开头我们的问题:多头自注意力到底在看什么?通过水浒传这样真实、结构独特的古文片段,我们不仅看到了模型如何在字与字之间建立联系,还直观感受了不同“注意力头”各自的关注模式。有人关注近邻字,有人专注关键字,有人把目光投向整句的节奏与意境。
这就像课堂上不同的老师一样——他们的视角不同,但共同构成了对整篇文章的完整理解。这种可视化,不只是为了“看个热闹”,而是把模型内部的决策过程摊开给人看,让深度学习的“黑箱”多了一点可解释性。
至此,我们用水浒的诗意古文,让多头自注意力的数学公式“活”了起来。接下来,我们将整合所有已学过的文章,去实现一个生成模型。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









