



刚刚,OpenAI 发布了 GPT‑5。这次它不再主打多模态或速度,而是回归语言模型的核心:更强的理解力、推理能力和执行力。
刚刚,OpenAI 发布了 GPT‑5。这次它不再主打多模态或速度,而是回归语言模型的核心:更强的理解力、推理能力和执行力。
它不再只是一个更强的模型,而是一个真正会“动脑子”的智能系统。
不是单个模型,而是一整个系统
GPT‑5 最大的升级,不在于参数量的堆叠,而在于架构的彻底变化:它从一个模型,变成了一个多个子模型协作的系统。你看到的还是一个 ChatGPT,但背后其实是多个模型在分工配合:
- 快速模型:响应迅速,用于处理大多数日常提问;
- 推理模型:专门负责复杂逻辑、数学计算和编程任务;
- 智能路由:会根据提问的类型、难度,甚至用户语气,自动决定该切换哪个模型。
比如你在对话中加一句「认真想一想」,它就能识别并启用“深度推理”模式。对用户来说一切无感,但背后早已完成一次智能切换。
目前面向普通用户,GPT-5提供免费、Plus和Pro三种模式。
性能提升,测试成绩几乎屠榜
GPT‑5 在多个评测中全面刷新成绩:
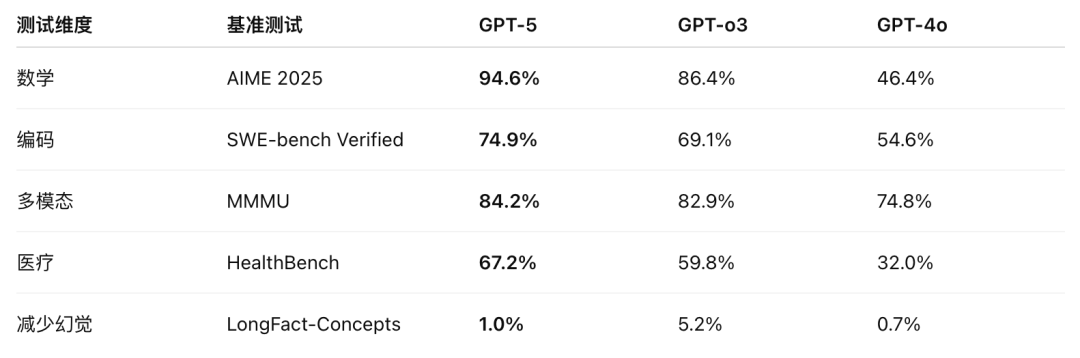
在编程方面,GPT-5 的编码性能超越了 Claude Opus 4.1,成为全球“最强”的编码模型。它在 SWE-Bench 上的准确率达到了 74.9%,略高于 Claude 的 74.5%。
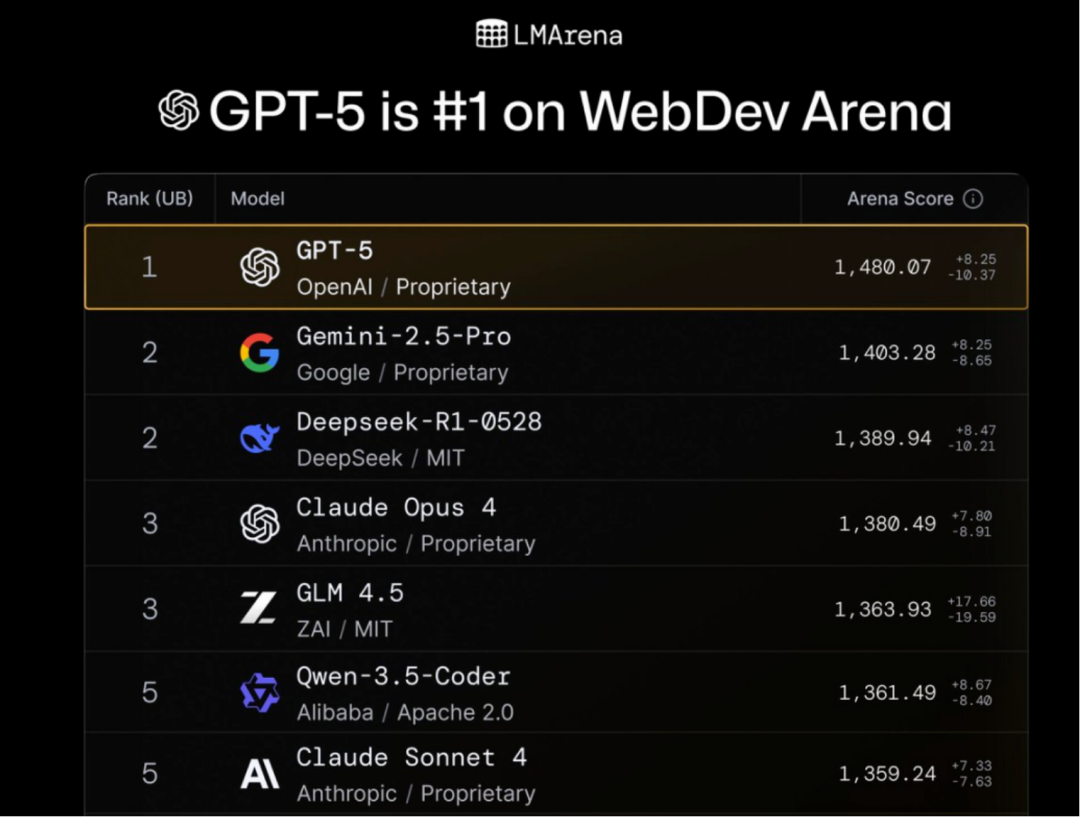
支持超长记忆,还能调节推理风格
GPT‑5 的上下文窗口再次突破,支持最多 40 万个 token(含输入与输出):最多可处理 272k 输入 + 128k 输出。
另外,新模型加入了多个可控参数,让生成行为更可控:
- reasoning_effort:控制推理深度(minimal / low / medium / high);
- verbosity:控制回答长度(简洁 / 中等 / 详细);
- 执行长任务时,会自动播报进度,更像一个条理清晰、可靠的执行者。
多个版本,按需选择
GPT‑5 并不是一个单一模型,而是一整个产品族,适配不同场景需求:
- gpt-5:标准主力版,适合深度推理、多步骤任务;
- gpt-5-mini:轻量版,适合对成本更敏感的用例;
- gpt-5-nano:速度极快,适用于对延迟要求极高的系统;
API 性价比超预期
GPT‑5 的定价策略相较 GPT‑4o 更具吸引力:
- 输入 token 单价是 GPT‑4o 的一半,输出价格基本持平;
- 输出中包含用于推理的“不可见 token”,也就是说相同内容可能会用更多 token;
- 短时间内重复使用相同输入 token 可享受 90% 折扣 —— 聊天类产品非常适合;
- 支持 token 缓存、精细控制,甚至可以选择不同的“推理等级”以控制成本和效果。

写在最后
GPT‑5,不只是更强了,而是更“像个会思考的人”。
如果说 GPT‑4o 是那个反应敏捷、表达清晰的聪明助手,GPT‑5 更像是你值得信赖的搭档。你问一句「这事能搞定吗?」
它会默默点头,然后开始分析、分步骤推进,直到把事情办妥。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









