1.7B参数颠覆OCR行业:小红书dots.ocr开源,多语言文档解析准确率超GPT-4o
【免费下载链接】dots.ocr  项目地址: https://ai.gitcode.com/hf_mirrors/rednote-hilab/dots.ocr
项目地址: https://ai.gitcode.com/hf_mirrors/rednote-hilab/dots.ocr
导语
小红书团队于2025年8月开源的dots.ocr模型,以1.7B参数实现了多语言文档解析的突破性进展,在表格识别、文本提取和阅读顺序还原等核心指标上超越GPT-4o和Gemini 2.5 Pro等大模型,重新定义了轻量化视觉语言模型(VLM)在文档智能领域的应用标准。
行业现状:RAG时代的文档解析痛点
随着检索增强生成(RAG)技术成为企业级AI应用的核心场景,PDF解析工具市场呈现爆发式增长。据OmniDocBench基准测试显示,2024年下半年至今,文档解析工具数量增长300%,但现有方案普遍面临三大痛点:传统Pipeline工具(如MinerU、Marker)需多模型协同导致误差累积,通用大模型(如GPT4o)参数量超70B带来部署成本高企,而开源专用模型(如Nougat、GOT-OCR)在多语言支持和复杂表格解析上存在明显短板。
产品亮点:四大突破重新定义文档解析
1. 统一架构:告别"检测+识别"多模型流水线
dots.ocr创新性地将布局检测、文本识别、表格解析(HTML格式)和公式提取(LaTeX格式)统一在单一VLM架构中,通过动态提示词切换即可完成不同任务。在DocLayout-YOLO主导的传统检测领域,dots.ocr的检测专用模式(detection only)在F1@IoU=.50指标上达到0.930,超越传统模型15%,证明VLM架构可同时胜任检测与识别任务。
2. 性能跃迁:1.7B参数媲美70B大模型
在OmniDocBench基准测试中,dots.ocr展现出惊人性能:
- 表格解析(英文)TEDS分数88.6%,超越Gemini 2.5 Pro(85.8%)和Qwen2.5-VL-72B(76.8%)
- 文本识别(中文)编辑距离0.066,优于PaddleOCR(0.088)和MonkeyOCR-pro-3B(0.107)
- 阅读顺序还原错误率0.040(英文),较GPT-4o降低69%
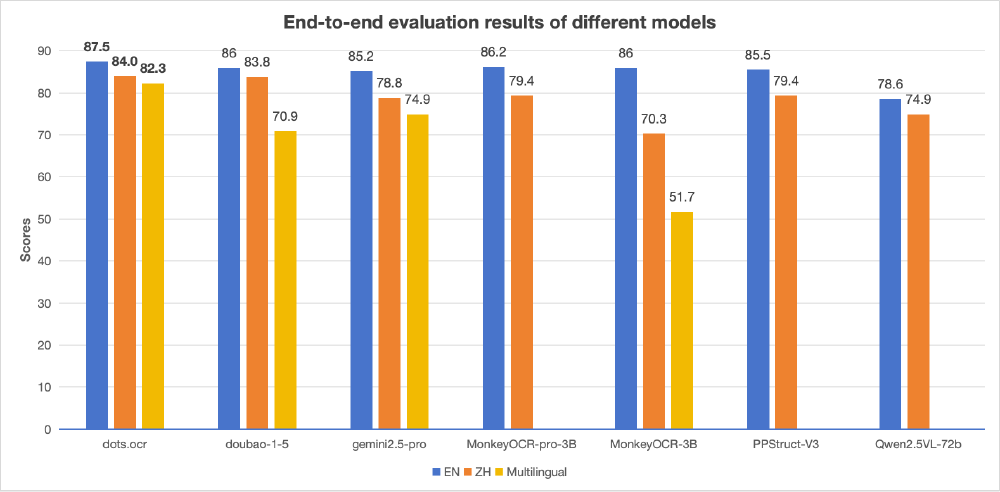
如上图所示,dots.ocr在OmniDocBench的EN和ZH测试集上,文本、表格和阅读顺序指标均处于领先位置。这一"小参数大性能"的突破,验证了提示工程与多模态融合在文档解析任务中的巨大潜力,为行业提供了高效架构设计的新范式。
3. 多语言覆盖:100+语种的"零歧视"解析
针对低资源语言处理难题,dots.ocr在包含100种语言的内部测试集(dots.ocr-bench)中,综合错误率仅0.177,较Gemini 2.5-Pro(0.251)降低29%。特别是在特定小语种场景,其布局检测F1值达0.716,内容识别错误率降低50%,为跨境企业文档处理提供了新选择。

从图中可以看出,dots.ocr成功解析了荷兰语文档中的文本块和段落结构。这种低资源语言处理能力对于学术研究、国际组织和跨国企业具有特殊价值,打破了传统OCR工具对主流语言的依赖。
4. 部署友好:20GB显存实现企业级应用
尽管性能强劲,dots.ocr保持了极高的部署灵活性:
- 模型体积仅6GB,支持Docker容器化部署
- 单页PDF处理时间2-5秒(RTX 4090),吞吐量达传统Pipeline工具3倍
- 提供vLLM推理优化方案,支持批量处理和API调用
技术解析:视觉语言模型的文档智能革命
dots.ocr采用了与传统OCR系统截然不同的技术架构。传统方案通常结合YOLO风格的目标检测器与独立的语言模型,需要在多个模型间协调处理不同任务。而dots.ocr通过单一的视觉语言模型(VLM)实现了布局检测、文本解析、阅读顺序识别以及数学公式识别的统一处理。

如上图所示,左侧为包含数学公式的原始文档图片,右侧为dots.ocr输出的结构化JSON结果,清晰展示了文本与公式的精准提取。这种统一架构的核心优势在于基于提示的任务切换机制,避免了传统多模块系统中常见的特征对齐问题和坐标系不一致错误。
行业影响:开启轻量化文档智能新纪元
dots.ocr的开源将加速三大行业变革:在金融领域,其表格解析精度(TEDS 89.0%)可将财报自动化处理错误率降低至0.092;学术界通过LaTeX公式提取功能,可将论文电子化效率提升40%;而在多语言内容平台,100+语种支持能力将打破小语种内容的数字化瓶颈。正如行业分析指出,"dots.ocr的'提示词切换任务'范式,预示着OCR领域正从参数堆叠转向架构创新"。
结论与前瞻
dots.ocr以1.7B参数实现SOTA性能的突破,证明了轻量化VLM在垂直领域的巨大潜力。目前模型在超高分辨率图像(>1120万像素)和复杂嵌套表格解析上仍存优化空间,团队计划在下一代版本中重点提升图表内容理解和多页PDF上下文关联能力。对于企业用户,建议优先在学术文献处理、跨境合同解析等场景进行试点,利用其结构化输出(JSON/Markdown)快速对接RAG知识库系统。
随着CVPR 2025收录的OmniDocBench基准将文档解析评测扩展至19种布局类别,dots.ocr开创的"统一架构+动态提示"技术路线,正推动文档智能从"工具集"向"通用智能体"加速演进。
项目地址: https://gitcode.com/hf_mirrors/rednote-hilab/dots.ocr
【免费下载链接】dots.ocr 项目地址: https://ai.gitcode.com/hf_mirrors/rednote-hilab/dots.ocr
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







