



当前预训练语言大模型(LLM)虽具备通用能力,但适应专业领域需高昂的指令微调成本;稀疏混合专家(SMoE)架构作为可扩展的性能-效率平衡框架,虽能提升推理效率并灵活扩展模型容量,但其从头训练消耗巨大资源,因此复用密集大模型参数的升级改造(LLM Upcycling)成为更具成本效益的替代方案。
只需一次指令微调,即可让普通大模型变身“全能专家天团”?
- 改造位置自动定位
- 专家协作动态平衡
- 8B模型性能反超全微调基线1.6%,安全指标暴涨10%,推理内存直降30%!
图片
当前预训练语言大模型(LLM)虽具备通用能力,但适应专业领域需高昂的指令微调成本;稀疏混合专家(SMoE)架构作为可扩展的性能-效率平衡框架,虽能提升推理效率并灵活扩展模型容量,但其从头训练消耗巨大资源,因此复用密集大模型参数的升级改造(LLM Upcycling)成为更具成本效益的替代方案。
图片
然而现有升级方法存在两大局限:一是依赖人工经验选择可扩展的专家位置(如固定替换FFN层),忽视模型层间动态差异与任务特性;二是缺乏系统机制平衡专家专业化与协作,导致冗余或知识碎片化。
为此,来自浙江大学与Thomson Reuters的研究团队提出全新解决方案稀疏插值混合专家(SIMoE),只需单阶段指令微调,即可将普通大模型自动升级为高性能稀疏专家模型。SIMoE通过结构化稀疏优化自动发现神经元级专家参数子集,创新性地结合专家共享增量参数与掩码正交惩罚在多项基准测试中实现性能、效率的双重突破。
目前相关研究论文已被ICML 2024、ACL 2025 Oral接收,代码及项目网址也已在GitHub上公开。

图片
△ICML2024接收

图片
△ACL 2025 Oral接收
传统改造为何失灵?
当前大模型升级改造方法用于大模型专业领域适配面临双重困境:
局限性一:升级改造位置依赖经验性设计,缺乏自适应机制。
现有方法在决定大模型参数中”何处升级”(where-to-upcycle)时,普遍采用启发式规则,例如固定选择FFN层或Attention模块进行升级,扩展成为SMoE模组。这种静态升级策略忽视了两个关键因素:
1、模型特异性:同一预训练大模型中不同层/参数对模型整体功能的重要性存在显著差异;2、领域适配需求:不同领域任务会要求特定最优升级位置。
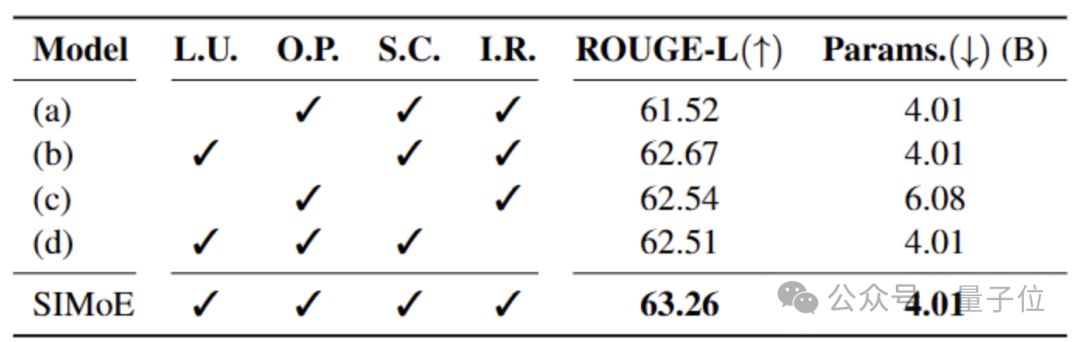
这种算法-模型-数据的脱节导致升级策略僵化,无法自适应特定任务场景,最终导致领域适配性差。如下表所示,传统经验性固定升级策略(i.e.,Learnable Upcycling)—例如升级所有FFN层—对比SIMoE的动态升级策略,其ROUGE-L分数低于SIMoE 1.6–2.5%。
图片
局限性二:专家专业化与协作机制缺失
现有方法缺乏系统化机制平衡专家专业化与协同合作:
1、专业化不足:为促进知识共享,传统SMoE框架常采用固定共享专家强制协作机制。然而,此类设计会抑制领域专家的专业化能力,极端情况下甚至引发模型崩溃(model collapse)——表现为专家间参数趋同。
2、协作低效:为促进专家专业化,部分升级方法[1]采用独立微调策略——先针对不同领域数据训练多个领域专家,再通过额外训练阶段将其合并为统一SMoE模型。然而,独立训练阻碍了知识迁移,导致专家参数冗余。
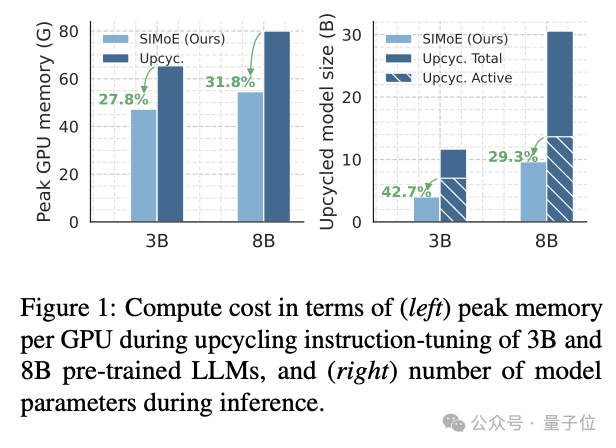
专业化与协作失衡导致泛化性能次优及资源浪费。如图表所示,当前升级方法[1]相较于SIMoE存在性能与参数效率上的双重差距。
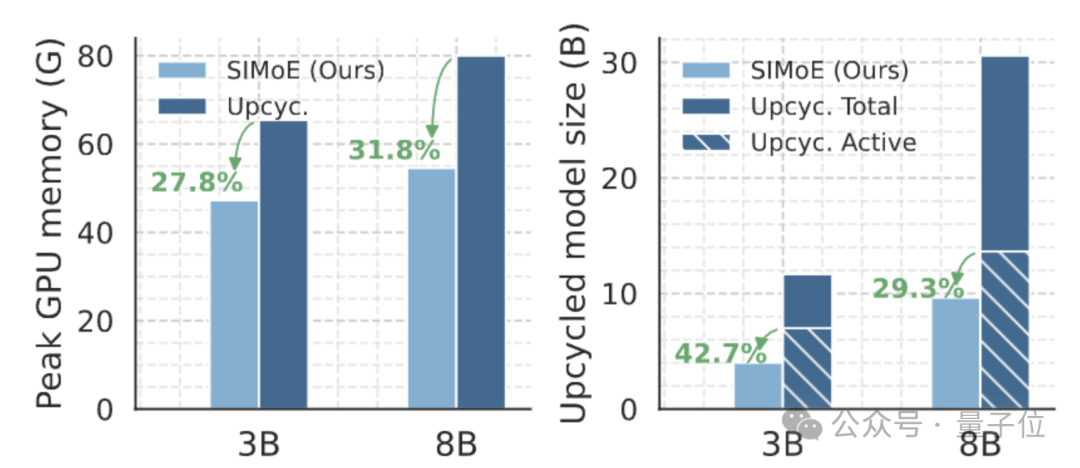
图片

全新升级改造框架:稀疏插值专家
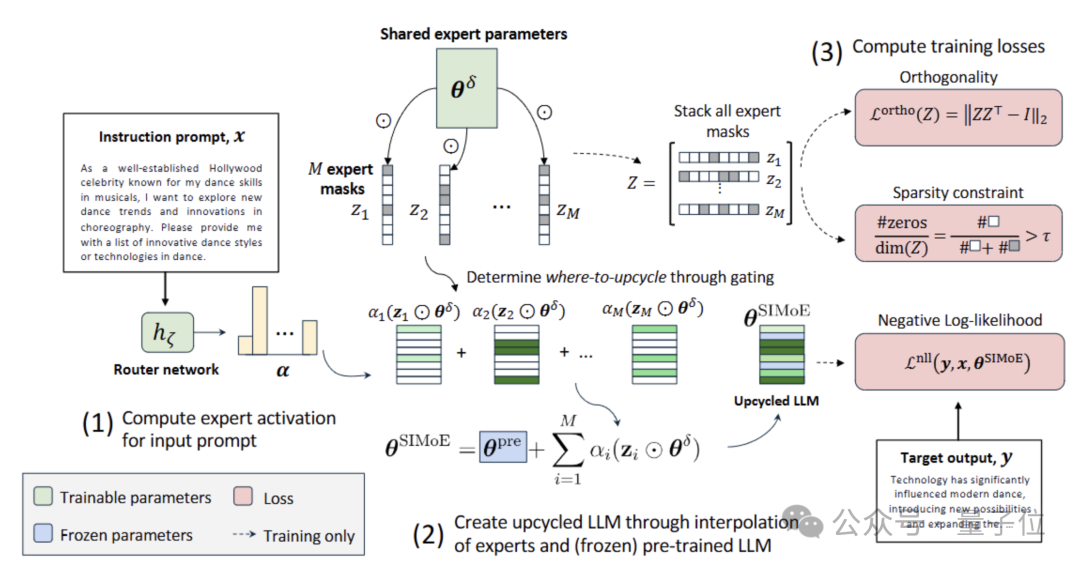
图片
稀疏插值专家(SIMoE)在概念上类似于MoE原理,通过软合并来路由和组合特定专家参数,但在实现上与传统MoE架构不同。SIMoE将每个「插值专家」定义为共享网络中稀疏参数的特定子集。
具体而言,SIMoE包括可训练的共享的专家参数集θδ(shared expert parameters)和M个可训练的独立专家掩码集
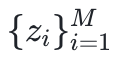
(expert masks)。在前向计算中,SIMoE(1)通过由路由网络hζ生成的加权系数α合并专家,(2)然后与冻结的预训练大型语言模型参数θpre结合。(3)在指令微调阶段,同步施加化稀疏约束(sparsity constraint)与正交惩罚(orthogonality)于可训练掩码,在优化标准NLL损失的同时自动化确定升级位置(where-to-upcycle),促进专家专业化与协同合作。
创新1:结构化稀疏升级——将专家定位转化为可学习的稀疏优化问题
面对传统LLM升级中人工选择升级层位的局限,提出一种根本性解法:将”何处升级”转化为结构化稀疏优化问题。通过在基座模型的每个线性层引入可学习二进制掩码
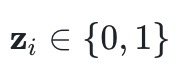
,构建SIMoE参数更新机制:
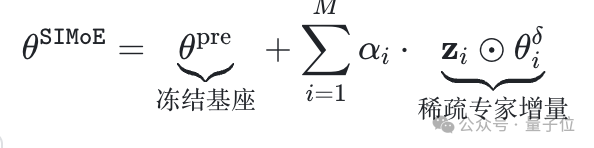
这一设计可带来三重优势:
首先,神经元级升级定位实现全局优化。通过引入L0稀疏约束构建可控优化目标:
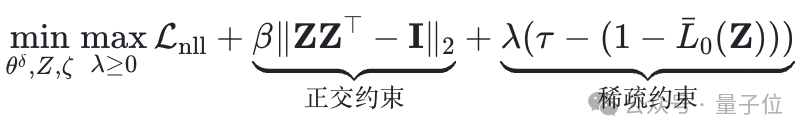
其中
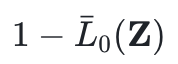
表示掩码的期望稀疏度,τ为目标稀疏度。该拉格朗日对偶优化框架通过动态调整λ值,驱使掩码稀疏度收敛至目标值τ,从而自动筛选基座模型中(1-τ)比例的参数进行升级改造。
其次,结构化稀疏设计攻克硬件瓶颈。当传统专家参数量级掩码
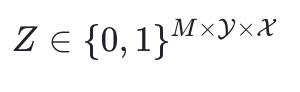
导致模型所需训练参数暴涨M倍时,提出将掩码维度压缩至输入神经元数
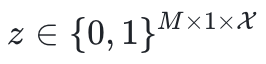
。这种硬件友好型稀疏产生连续内存块,直接匹配GPU存取模式,使训练峰值内存降低30%,同时维持神经元级控制粒度——这是实现8B基座模型可扩展性的关键。
最终,冻结基座与稀疏增量协同守护知识完整性。式中θpre的冻结设计确保预训练知识不受扰动,避免指令微调时的灾难性遗忘。配合75%稀疏约束τ=0.75,推理时自动剪枝零值神经元级专家,最终模型尺寸较BTX [1] 缩减66%(10.4B vs 30.58B)。
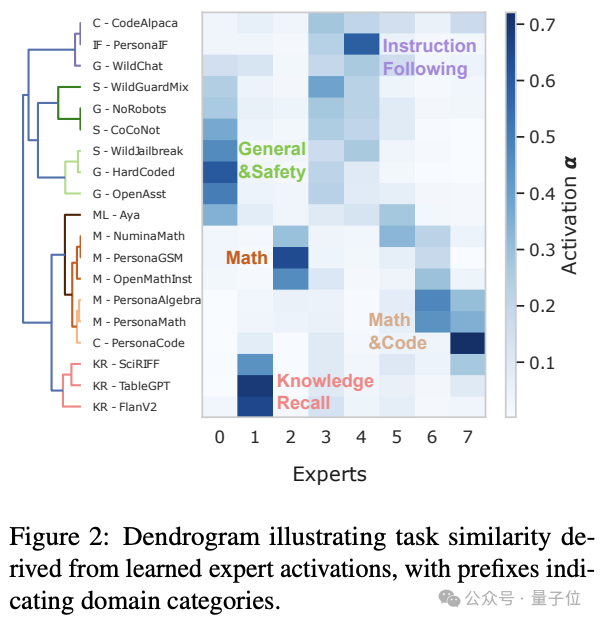
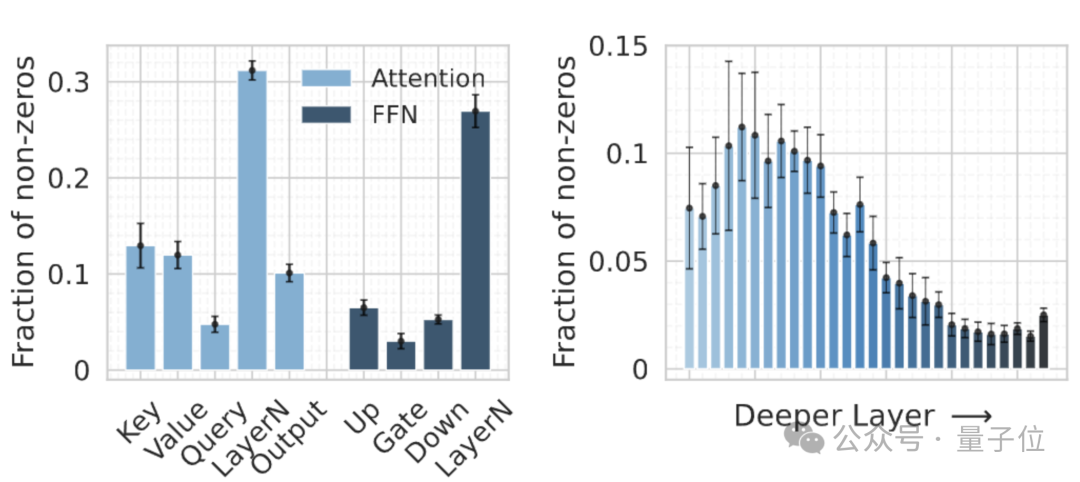
实验发现
- LayerNorm层改造强度超30% - 传统方法忽视的关键区域
- 注意力门控层仅需不到10%改造 - 颠覆”注意力层最重要”的固有认知
- 多种类别层参与学习的改造方案 - 实现最佳性能,告别手动改造次优解
图片
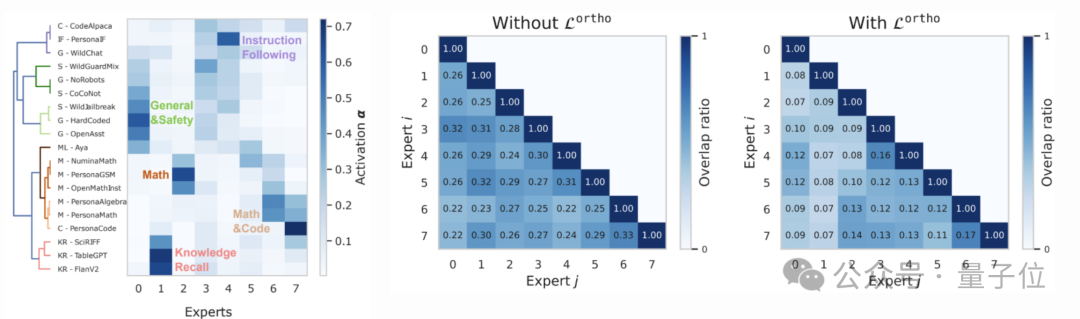
创新2:专家团队内的”防内卷协议”-协作,独立的完美平衡
区别于传统SMoE,通过参数共享降低冗余与正交约束保证专家专业化的协同的平衡,其数学本质是鼓励学习一组正交掩码
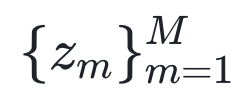
对共享参数进行结构化调制,使各专家在共享知识基座θδ上形成互补的专业化能力

。
- 参数高效:仅需存储一份θδ,避免参数冗余,大大节约训练开销
- 知识迁移:梯度更新
聚合所有专家信号,促进跨任务泛化
- 专家专业化:每个专家独享可学习的神经元二进制掩码→通过对掩码的正交惩罚 → 自动筛选适领域特定专业化参数
应用场景多适配:
小样本视觉任务:给定少量任务样本→动态训练特定任务的教师模型→通过知识蒸馏引导「插值专家」模型的组合泛化能力,训练效率提升43%。
零样本指令遵循:通过对「插值专家」二进制掩码的正交约束→鼓励「插值专家」参数专业化→通过训练,达到知识共享于领域专业化的黄金平衡。
图片
实验验证
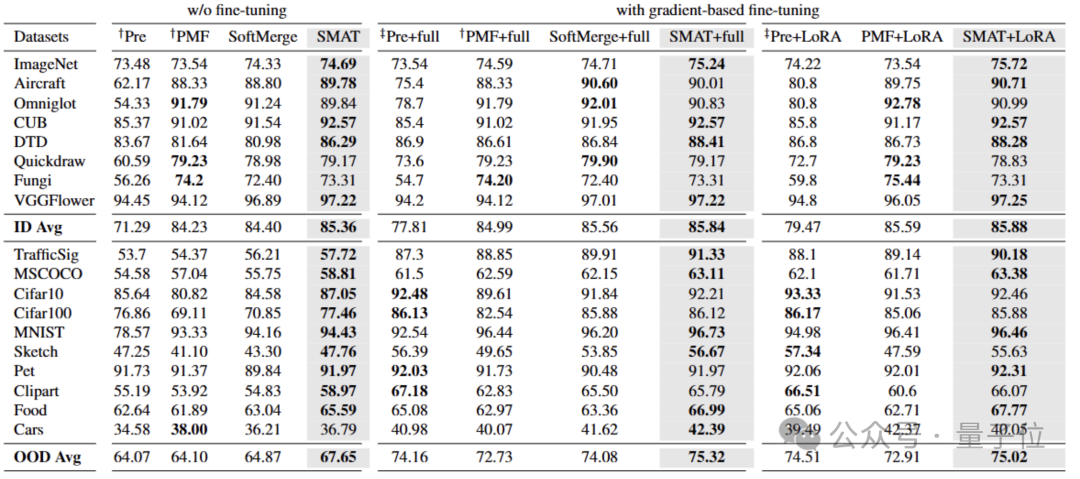
视觉基座模型验证:Meta-Dataset大规模视觉小样本学习基准测试。
图片
SMAT(SIMoE的视觉版本)在零样本和小样本迁移场景中全面超越基线模型,OOD任务表现尤为惊艳:在零样本设置下,SMAT平均准确率达67.65%,较最佳基线提升2.8%;在小样本场景(few-shot, with gradient-based fine-tuning)中,SMAT以75.02%的准确率刷新SOTA纪录。
自然语言基座模型验证:SuperNaturalInstruction跨任务泛化能力基准测试。
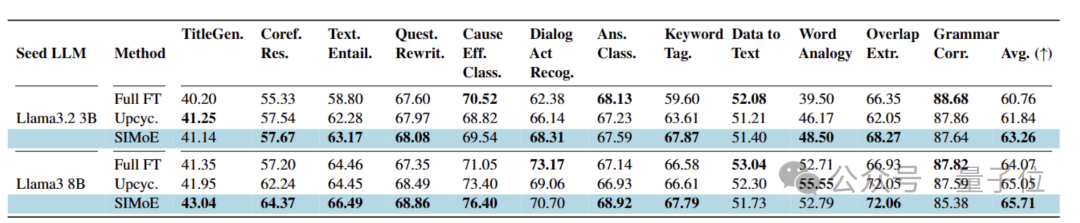
图片
SIMoE在跨任务泛化能力上展现统治级表现。在12类未见任务中,SIMoE在9类任务上显著领先:3B模型较全微调基线提升2.5%,8B模型提升1.6%。
自然语言基座模型验证:Tulu-v3 SFT Mixture多领域泛化能力基准测。

图片
SIMoE在大规模场景仍保持性能统治力。面对8B参数基座模型和百万级指令数据,SIMoE在MMLU、GSM8K等12项核心基准平均得分61.1%,以0.6%优势超越当前SOTA模型Tülu-v3-8B-SFT,在指令遵循(IFEval +1.3%)和安全测试(Safety +1.7%)等任务中展现明显优势。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









