



本文通过使用OmniDocBench提供的评测数据集和方法对TextIn xParse进行了客观且全面的评测,综合最终的评测结果来看,TextIn xParse确实是一款能力较强且较为全面的文档解析工具。

在RAG系统的建设中,文档预处理是一个非常关键的环节,因为只有将文档中的图表、表格、公式以及手写批注等信息按阅读顺序还原出来,并最终解析为Markdown格式,这样才能够构建高质量的知识库和高效的信息检索系统,让LLM更好的读懂文档,最终给到用户更准确更全面的回答。
目前的文档解析工具算是百花齐放了,有很多优秀的开源工具(MinerU、Docling、Unstructured等等),在我之前的文章也有讲过。
今天给大家测评一款优秀的文档解析工具 - TextIn xParse[1] ,看下它的文档解析能力到底如何,希望通过我的测评能够给大家带来更多更好的选择。
为使本次测评能真正作为大家的选择参考,本次测评使用的数据集是由上海人工智能实验室开源的一个针对真实场景下多样性文档解析评测集 - OmniDocBench[2]。
OmniDocBench评测集涉及981个PDF页面,涵盖9种文档类型、4种排版类型和3种语言类型,文档覆盖面广,包含学术文献、财报、报纸、教材、手写笔记等,而且所有的标注都经过人工筛选,智能标注,人工标注及全量专家质检和大模型质检,数据质量较高,评测结果有很高的可信度。
TextIn xParse 简介
TextIn xParse是一个专为LLM下游任务设计的通用文档解析服务,具有解析速度快、稳定性高,特别是在表格识别上进行了专项优化。

识别能力覆盖全面,具有各类常见文档的识别解析能力,支持标准的金融报告、国家标准、论文、企业招投标文件、合同、文书、工程图纸、电子书、试卷等文档内容。

TextIn xParse 测评
是否真如宣传的那样优秀,我们通过客观的测评来验证。
首先通过TextIn xParse对OmniDocBench评测集中的981个PDF页面进行解析,整体耗时1177s,平均一页的解析速度为1.2s,这个解析速度相比于开源工具(如MinerU)提供的线上服务快了将近8倍,解析速度非常的快,这个数据仅供参考,大家可以自行去体验。
接下来我们将TextIn xParse解析出来的981个Markdown文档,给到OmniDocBench提供的评测方法进行测评。
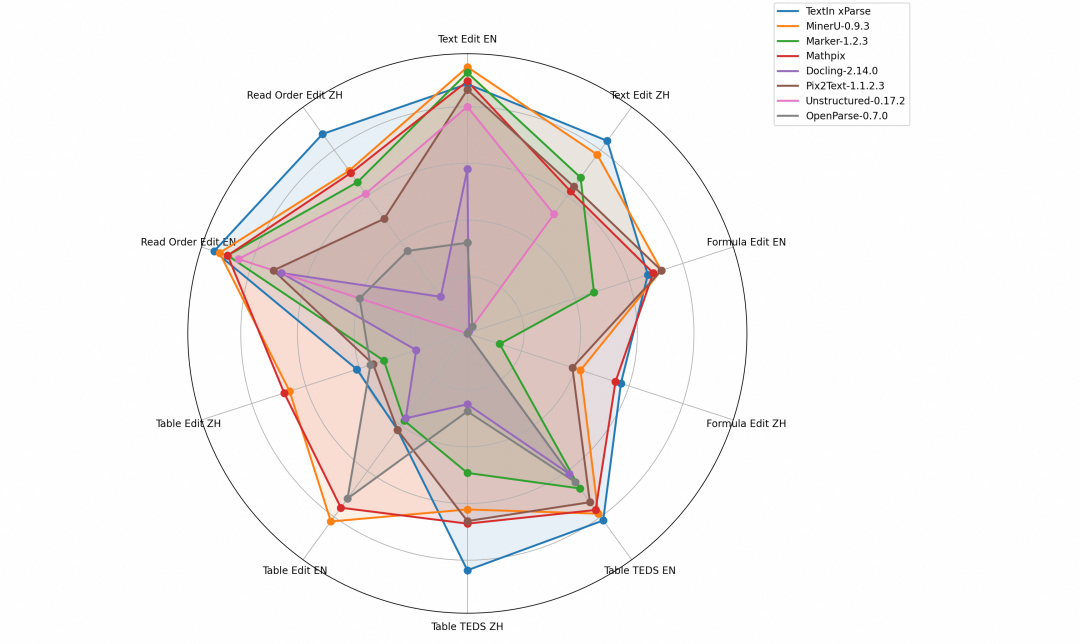
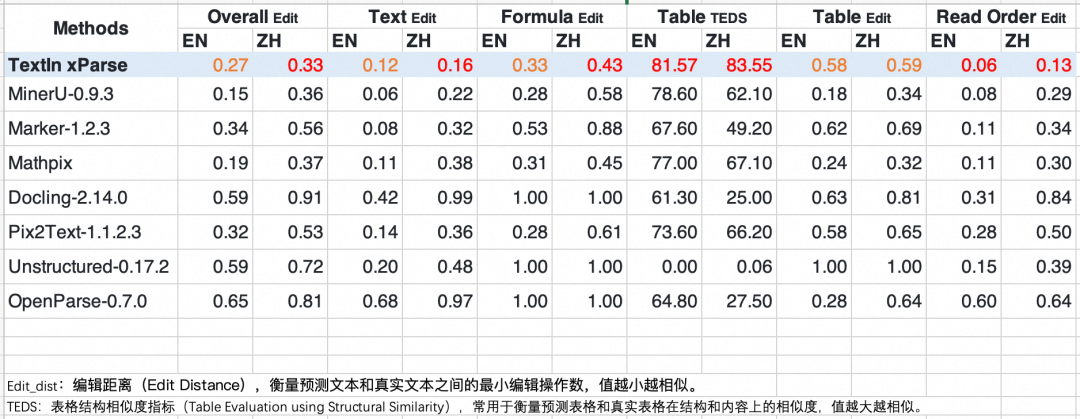
下图就是TextIn xParse和其它开源工具在文本、公式、表格以及阅读顺序这四大模块的具体表现:
指标说明:
1. Edit Dist(编辑距离):,衡量预测文本和真实文本之间的最小编辑操作数,值越小越相似;
2. TEDS(表格结构相似度):衡量预测表格和真实表格在结构和内容上的相似度,值越大越相似。
从整体(Overall Edit)来看,TextIn xParse不管是对英文文档(0.27)还是中文文档(0.33),都比大多数开源工具表现出色,由此可表明,TextIn xParse是一款能力较强且较为全面的文档解析工具。
下面我们看下TextIn xParse在不同模块的表现:
- 文本(Text Edit):TextIn xParse不管是对英文文档(0.12)还是中文文档(0.16)都表现出色,尤其是对于中文文档表现得最好,表明其在处理纯文本内容时具有较高的准确性;

- 公式(Formula Edit):TextIn xParse不管是对英文文档(0.33)还是中文文档(0.43)都表现出色,尤其是对于中文文档表现依然是最好的,表明其在识别和解析公式时具有较高的准确性;

- 表格(Table TEDS/Edit):TextIn xParse表现优秀,其中在表格结构相似度上,无论是对英文文档(81.57)还是中文文档(83.55)都表现得最好,表明其在处理表格内容时能够很好地保持原始结构和内容,这也表明了TextIn xParse确实在表格识别上进行了专项优化;
- 阅读顺序:(Read Order Edit):TextIn xParse表现优秀,无论是对英文文档(0.06)还是中文文档(0.13)都表现得最好,表明其在保持文本阅读顺序方面具有很高的准确性。
TextIn xParse 集成
TextIn xParse提供了多种集成方式,支持在线预览与导出、实时API调用、离线调用以及私有化部署等方式,可根据您的需求灵活选择。

在线预览与导出
最轻量级的使用方式,支持识别结果的在线预览和编辑,支持批量导入与导出,对非开发者友好。
实时 API 调用
最常见的调用方式,所有请求均实时返回,支持丰富的参数设置,适合在线类应用和时效要求高的开发者。
一个接口,支持PDF、Word(doc/docx)、常见图片(jpg/png/webp/tiff)、HTML等多种文件格式。一次请求,即可获取文字、表格、标题层级、公式、手写字符、图片信息。

实时API调用示例代码:
复制
import requests
import json
def get_file_content(filePath):
withopen(filePath, 'rb') as fp:
return fp.read()
class TextinOcr(object):
def __init__(self, app_id, app_secret):
self._app_id = app_id
self._app_secret = app_secret
self.host = 'https://api.textin.com'
def recognize_pdf2md(self, image_path, options, is_url=False):
url = self.host + '/ai/service/v1/pdf_to_markdown'
headers = {
'x-ti-app-id': self._app_id,
'x-ti-secret-code': self._app_secret
}
if is_url:
image = image_path
headers['Content-Type'] = 'text/plain'
else:
image = get_file_content(image_path)
headers['Content-Type'] = 'application/octet-stream'
return requests.post(url, data=image, headers=headers, params=options)
if __name__ == "__main__":
# 请登录后前往 “工作台-账号设置-开发者信息” 查看 app-id/app-secret
textin = TextinOcr('#####c07db002663f3b085#####', '######1b1b11a9f9bcd7cc7b######')
# 示例 1:传输文件
image = 'file/example.pdf'
resp = textin.recognize_pdf2md(image)
# 示例 2:传输 URL
image = 'https://example.com/example.pdf'
resp = textin.recognize_pdf2md(image, True)
离线调用
支持全流程域内服务器处理,提供10万次起订的预付费套餐包,使用门槛更低,支持快速集成至现有业务系统。
私有化部署
提供按年付费和买断机制,支持国产化显卡适配,让你放心处理企业内部数据,无惧数据流失。
提交私有化部署需求后,会有专属服务人员与您联系和对接。
结语
本文通过使用OmniDocBench提供的评测数据集和方法对TextIn xParse进行了客观且全面的评测,综合最终的评测结果来看,TextIn xParse确实是一款能力较强且较为全面的文档解析工具。而TextIn xParse也考虑到了不同的用户和场景,提供了多种灵活的集成方式,您可根据具体需求来灵活选择,非常的友好。

















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









