




总是“死记硬背”“知其然不知其所以然”?奖励模型训练也形成了学生选择标准答案的学习模式,陷入诸如“长回答=好回答”“好格式=好答案”等错误规律之中。北京大学知识计算实验室联合腾讯微信模式识别中心、William&Mary、西湖大学等机构提出的RewardAnything突破了这一瓶颈——通过让奖励模型直接理解自然语言描述的评判原则,实现了从”死记硬背”到”融会贯通”的范式跃迁。RewardAnyt
总是“死记硬背”“知其然不知其所以然”?
奖励模型训练也形成了学生选择标准答案的学习模式,陷入诸如“长回答=好回答”“好格式=好答案”等错误规律之中。
北京大学知识计算实验室联合腾讯微信模式识别中心、William&Mary、西湖大学等机构提出的RewardAnything突破了这一瓶颈——通过让奖励模型直接理解自然语言描述的评判原则,实现了从”死记硬背”到”融会贯通”的范式跃迁。
图片
RewardAnything降低了传统模式针对不同场景需要收集偏好数据训练奖励模型再进行RL的高昂成本,能够直接利用自然语言作为RLHF的标准。
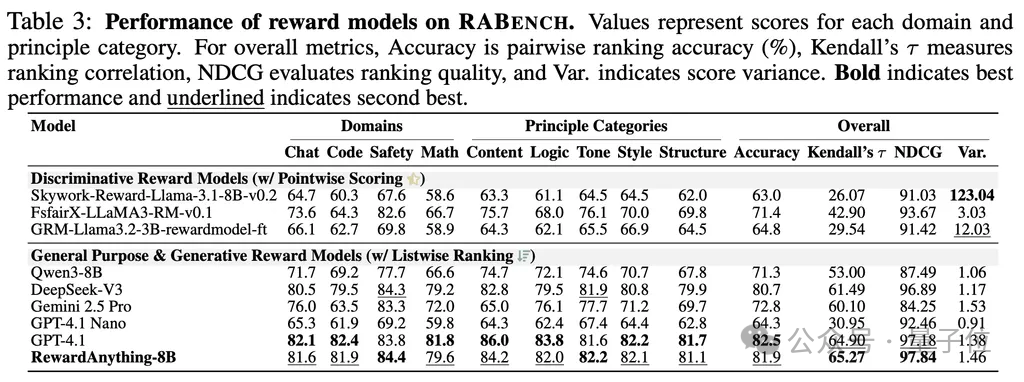
其作为奖励模型,仅需一句话描述的准则即可刷新传统Benchmark的SOTA,在RABench上展示出了与GPT-4.1等顶尖模型相媲美的原则跟随能力与泛化能力。
图片
奖励模型与偏好优化
尽管LLM展现出强大的性能,一个核心挑战始终存在:如何让LLM的行为和输出精准契合人类多样化而细腻的偏好、多元的价值观以及特定任务场景下的复杂需求?
奖励模型(Reward Model)就是LLM对齐与RL训练的关键组件——实现AI对齐(Alignment),让AI的行为和输出符合人类期望与价值观。它通过学习海量的偏好数据建模人类的偏好,学会“什么是好的回答”。
但是,传统奖励模型存在致命缺陷:在学习过程中形成了严重的偏见,它们通常在固定的、针对特定偏好标准收集的数据集上进行训练。这导致它们学习到的偏好分布是静态的,难以适应真实世界中多样化、动态变化的需求。
清华大学团队在ICLR‘25提出的RM-Bench评测基准揭露了一个现状:当前最先进的奖励模型在抵抗格式偏见测试中,准确率仅为46.6%——甚至不如随机猜测!
看2个例子,大家就明白了。
△问答Prompt和Response均来自RewardBench数据集
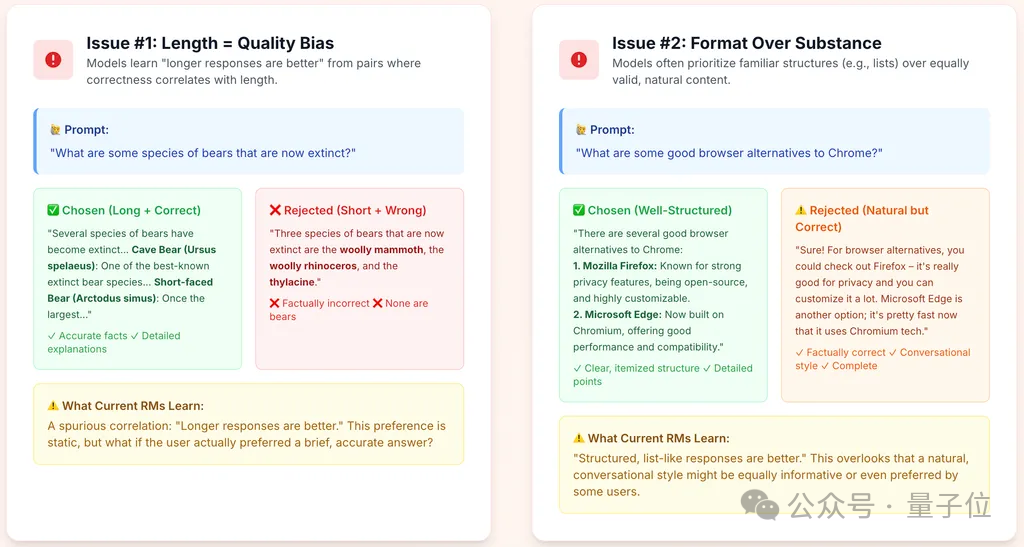
案例一:Length = Quality Bias问题:哪些熊类已经灭绝了?回答A(事实正确,丰富且格式化),回答B(事实错误,简洁)。人类判断:A更好。
上述案例是来自奖励模型的常用基准测试集RewardBench的常见情况,尽管其数据和标签均无事实性错误,但使用类似的数据训练奖励模型,会隐含一种偏见:模型在训练数据中观察到“正确的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









