




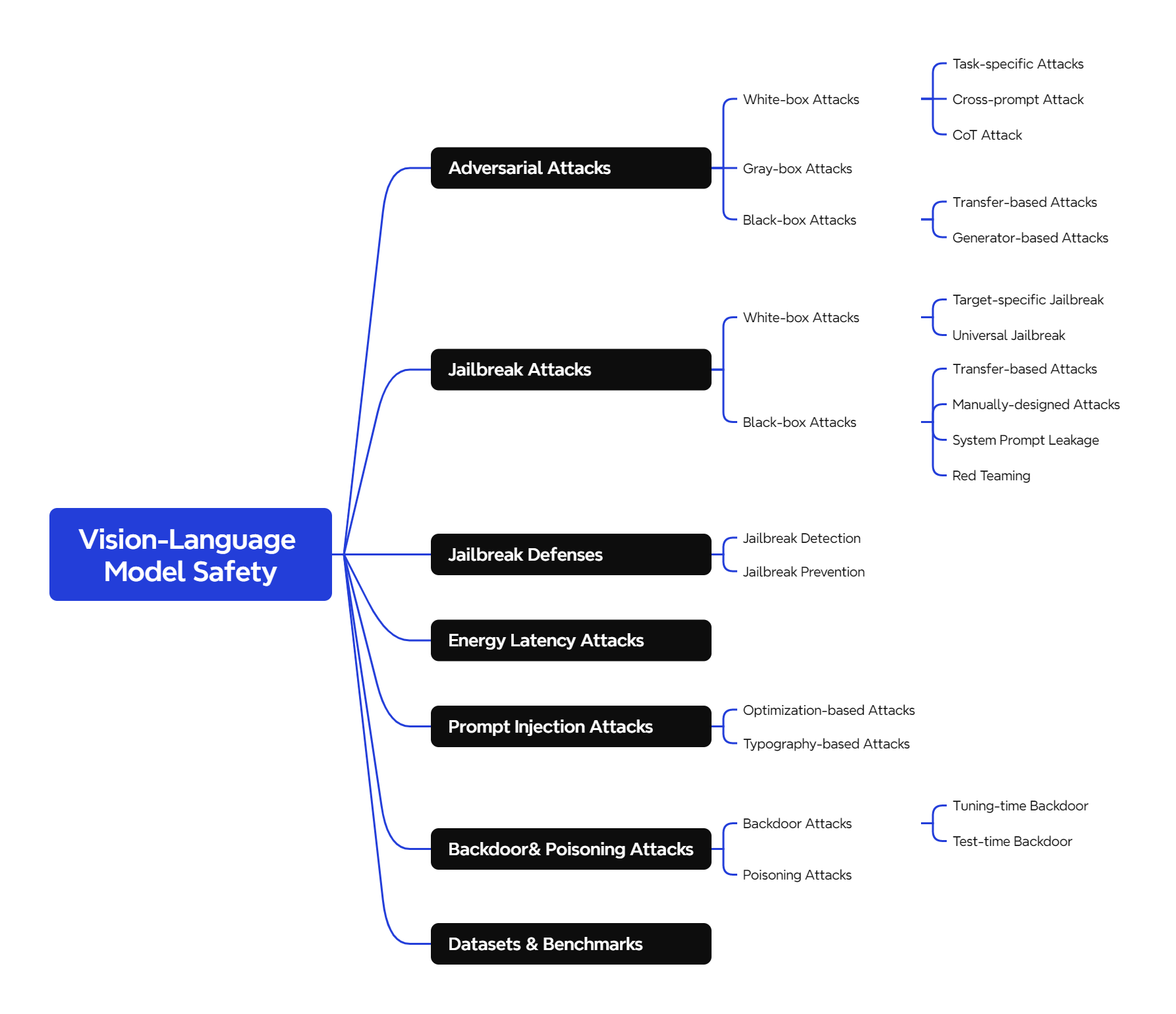
Adversarial Attacks
White-box Attacks
Task-specific Attacks 的目标是针对某个具体的任务(如图像描述生成、指代表达理解等),通过精心设计的对抗样本,使得模型在该任务上产生错误的输出。例如,攻击者可能希望模型生成错误的图像描述,或者在对图像进行指代表达理解(根据给定的自然语言描述(指代表达),在图像中定位并识别出与之对应的特定目标物体或区域)时给出错误的答案。Gao et al.提出了针对指代表达理解任务的攻击范式,展示了如何通过对抗样本误导模型在该任务上的表现。
Cross-prompt Attack 的目标是生成一个对抗样本(例如一张对抗图像),使得这个样本在多种不同的提示(prompts)下都能误导模型。换句话说,攻击者希望生成的对抗样本具有通用性,能够在不同的任务或上下文中都有效。CroPA 的研究探索了对抗图像在多个提示下的可迁移性。他们研究了是否可以通过生成一个对抗图像,使得这个图像在不同的文本提示下都能误导模型的预测。
CoT Attack 的目标是干扰模型的思维链推理过程,使得模型在生成中间步骤或最终答案时出错。攻击者可以通过生成对抗样本(如图像或文本),使得模型在推理过程中产生错误的中间结果,从而导致最终答案错误。Stop-reasoning Attack 研究了思维链推理对模型对抗鲁棒性的影响。尽管研究发现思维链推理可以提高模型的鲁棒性,但作者提出了一种新的攻击方法,能够绕过这些防御机制,干扰模型的推理过程。
Z. Wang, Z. Han, S. Chen, F. Xue, Z. Ding, X. Xiao, V. Tresp, P. Torr, and J. Gu, “Stop reasoning! when multimodal LLM with chain-ofthought reasoning meets adversarial image,” in COLM, 2024.
Abstract:我们首先通过攻击两个主要组件,即基本原理和答案,将现有的攻击推广到基于CoT的推理。我们发现,CoT确实通过利用多步推理过程提高了MLLMs对现有攻击方法的对抗性鲁棒性,但不是实质性的。基于我们的发现,我们进一步提出了一种新的攻击方法,称为停止推理攻击,它在绕过CoT推理过程的同时攻击模型。

由于基于CoT的推理由两部分组成,即基本原理和最终答案,我们通过攻击这两部分来研究MLLM的对抗性鲁棒性。首先,将现有的两种攻击推广到具有CoT的MLLMs,即回答攻击和基本原理攻击。答案攻击仅攻击答案中提取的选择字母,例如图1中的“B”字符,这适用于有或没有CoT的MLLM。另一种攻击,基本原理攻击,不仅攻击答案中的选择字母,还攻击前面的基本原理(图1基本原理攻击)。我们发现,与没有CoT的模型相比,采用CoT的模型在答案和基本原理攻击下往往表现出相当高的鲁棒性。Answer Attack 使用交叉熵损失函数来衡量对抗输出的答案与原始答案之间的差异。通过迭代优化,调整输入图像的像素值,使得损失函数最大化。具体来说,在每次迭代中,计算当前对抗图像的输出,然后根据损失函数计算梯度,最后更新图像的像素值。这个过程可以使用如Projected Gradient Descent(PGD)等优化算法来实现。Rationale Attack 使用Kullback-Leibler(KL)散度来衡量对抗输出的推理依据与原始输出的推理依据之间的差异,同时结合交叉熵损失来确保最终答案的改变,与仅针对最终答案的Answer Attack不同,Rationale Attack同时针对推理依据和答案,因此在某些情况下可以更有效地降低模型的鲁棒性。
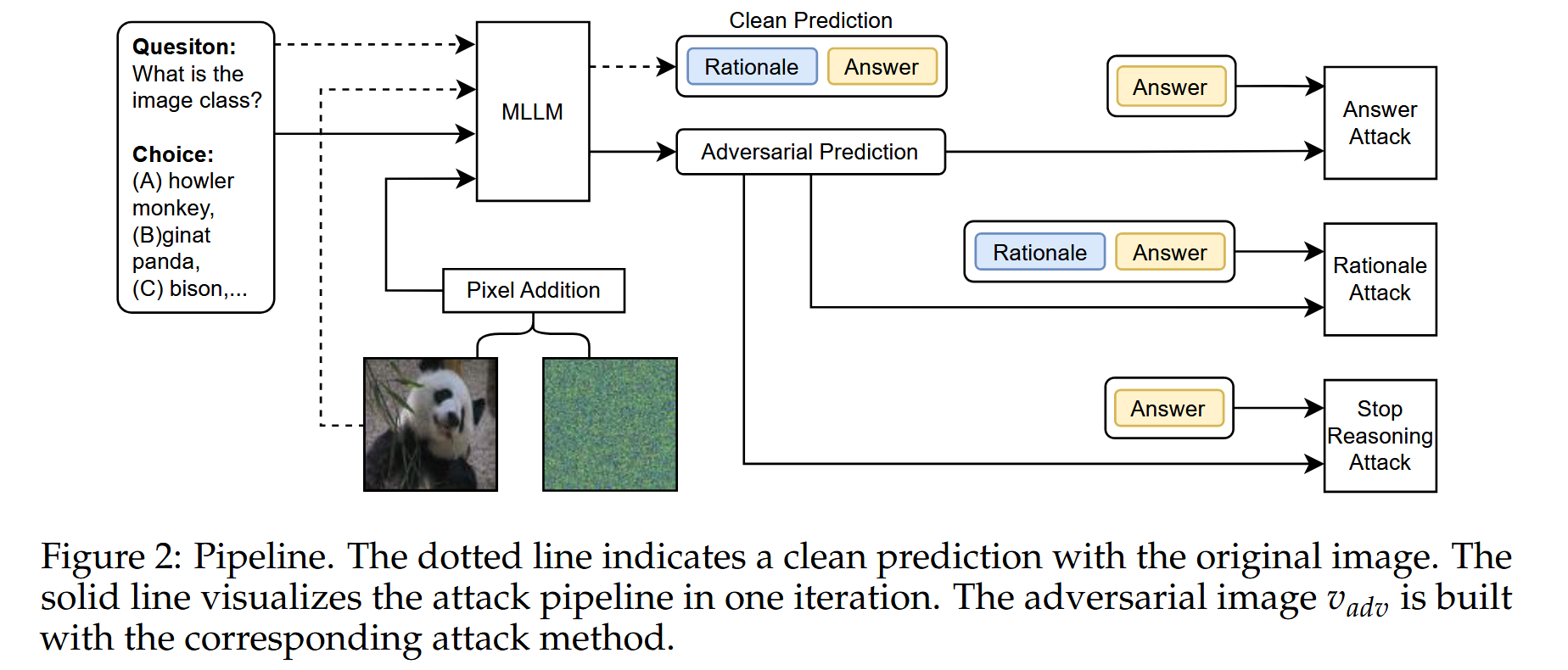
在文本输入中,我们预定义了一个特定的答案模板,表示为ttar,以提示模型以统一的格式输出答案。因此,当初始令牌与答案格式ttar对齐时,即使明确提示模型利用CoT,模型也会被迫以预定义的格式直接输出答案并绕过推理过程。停止推理攻击制定了交叉熵损失,以驱动模型在没有推理过程的情况下直接推断答案:
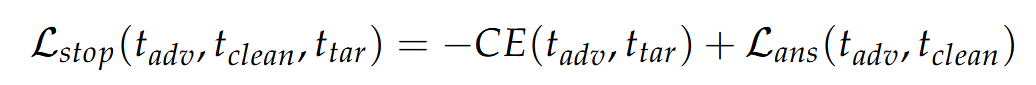
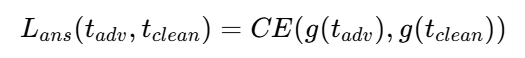
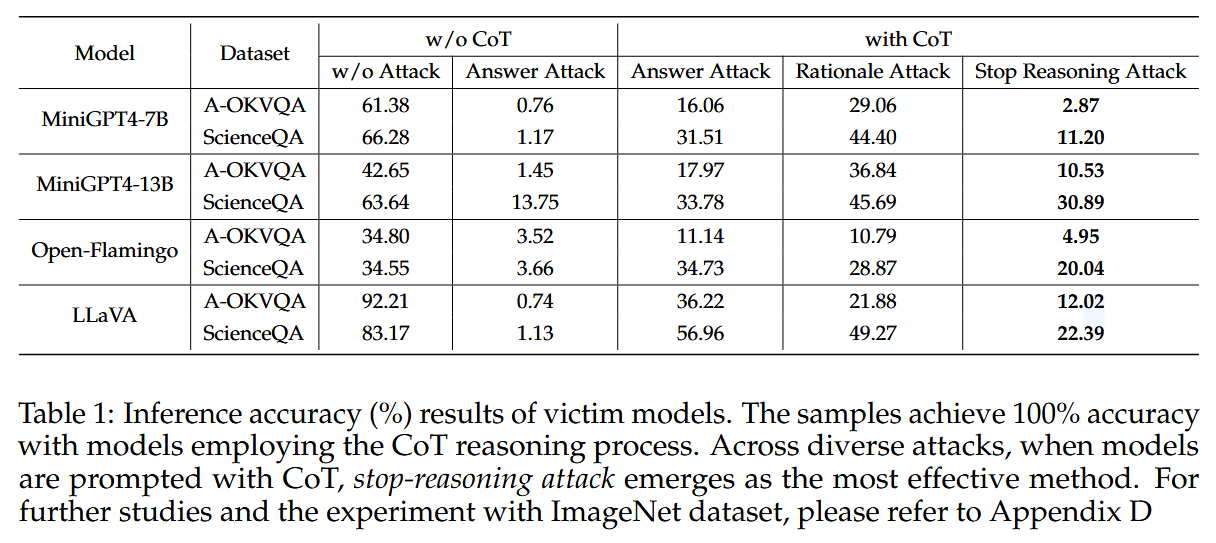
其中ttar是预定义的答案模板,例如,“答案是()。[EOS]”。通过增加损失,MLLMs通过将初始令牌与指定的答案格式对齐来直接输出答案,并将答案更改为错误的答案。这种方法绕过了推理过程,因此,它消除了CoT引入的鲁棒性提升。所有模型和数据集的结果都揭示了它的有效性。停止推理攻击远远优于两种现有方法,并且可以接近没有CoT的MLLMs的结果。tadv是对抗输出,tclean 是原始输出,CE 是交叉熵函数。g(⋅) 是答案提取函数,用于从模型的输出中提取答案部分。
如果测试的目的是评估模型在面对Stop-reasoning attack时的鲁棒性,即模型在被攻击时是否能够保持正常的推理能力,那么在测试阶段的prompt中不需要添加“预定义的答案模板”。此时,模型的输入prompt应保持自然和正常,以便观察模型在被攻击时的行为。例如,在测试阶段,你可以使用正常的prompt,如:
"请根据图片内容回答问题:图片中有什么?"
如果测试的目的是验证Stop-reasoning attack的效果,即是否能够成功中断模型的推理过程并迫使其直接输出答案,那么在测试阶段的prompt中需要包含“预定义的答案模板”。此时,prompt的格式应与训练阶段一致,以便模型能够识别并按照模板输出答案。例如,在测试阶段,你可以使用如下prompt:
"请根据图片内容回答问题,并按照以下模板输出答案:The answer is ().[EOS]"
这种情况下,模型会根据prompt中的模板要求,直接输出答案,而不进行推理过程。
Gray-box Attacks
Black-box Attacks
Transfer-based Attacks的核心思想是利用替代模型(surrogate model)生成的对抗样本,来攻击目标模型。攻击者首先在一个替代模型(通常是与目标模型结构相似的模型)上生成对抗样本。许多视觉-语言模型(VLMs)使用相似的架构或组件(如 CLIP 视觉编码器),这使得在一个模型上生成的对抗样本,可能对其他模型也有效。然后,将这些对抗样本直接输入到目标模型中,利用对抗样本的跨模型可迁移性,使得目标模型也产生错误的输出。AttackVLM:该方法针对 CLIP 和 BLIP 等模型生成目标对抗图像,并成功将这些对抗样本迁移到其他视觉-语言模型上。此外,研究还发现,通过黑盒查询(black-box queries)可以进一步提高生成目标响应的成功率。
Generator-based Attacks 是一种对抗攻击方法,其核心思想是利用生成模型(如 GANs、扩散模型等)来生成具有更高可迁移性和语义一致性的对抗样本。与传统的基于梯度优化的对抗攻击不同,Generator-based Attacks 通过生成模型直接生成对抗样本,这些样本通常更自然、更难以检测,并且在攻击不同模型时具有更强的可迁移性。**AdvDiffVLM **:利用扩散模型生成具有目标导向的对抗图像,这些图像具有更高的可迁移性。
Jailbreak Attacks
White-box Attacks
Target-specific Jailbreak 侧重于从模型中诱导特定类型的有害输出,这种攻击方法的核心是利用模型的梯度信息,对输入进行微小的扰动,从而绕过模型的安全措施,使其执行攻击者期望的特定行为。例如攻击者设计一张对抗图像,使得模型在描述这张图片时,错误地将其识别为“狗”而不是“猫”。这种攻击只对这张图片有效,不会影响其他图片的描述。Image Hijack 通过引入对抗图像来操纵 VLM 的输出。这些对抗图像可以在训练过程中使用通用数据集进行优化,从而有效地迫使模型产生攻击者期望的有害输出。Adversarial
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









