由定义式可以知道, 信源编码的核心问题: 信源的熵H(S) 信息速率Rb 其中,RS是符号速率,单位是(符号/s)或者是(Baud) 信源编码的主要问题: 信源的符号数L、概率场{Si}已知,如何选择划分的符号数J,使得Jlog2L≤n1log2D,即位数n1 满足 然后n1log2D尽可能小,来提高编码效率ηC=H(S)/n1log2D? 解决方法: (1)均匀编码(等长编码): 将原本“信源的符号数为L,每J个符号一组来编码”产生的序列集数目L
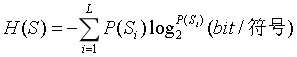
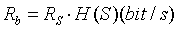
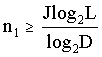


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











 本文探讨信源编码的核心问题,包括等长编码和不等长编码。等长编码通过典型序列减少编码长度,提高效率,但可能导致译码错误。不等长编码利用符号概率差异,减少码字长度,适用于实际系统,通过异字头码避免接收时的混淆。两者在编码速率和平均码长上有显著区别。
本文探讨信源编码的核心问题,包括等长编码和不等长编码。等长编码通过典型序列减少编码长度,提高效率,但可能导致译码错误。不等长编码利用符号概率差异,减少码字长度,适用于实际系统,通过异字头码避免接收时的混淆。两者在编码速率和平均码长上有显著区别。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























