







需要源码请点赞关注收藏后评论区留言私信~~~
K近邻(k-Nearest Neighbor Classification,KNN)算法是机器学习算法中最基础、最简单的算法之一,属于惰性学习法.惰性学习法和其他学习方法的不同之处在于它并不急于获得测试对象之前构造的分类模型,当接收一个训练集时,惰性学习法只是简单的存储或者稍微处理每个训练样本,直到测试对象出现才开始构造分类器,惰性学习法的一个重要优点是它们不在整个对象空间上一次性的估计目标函数,而是针对每个待分类对象做出不同的估计,KNN算法通过测量不同特征值之间的距离进行发呢类,既能用于分类也能用于回归
算法原理
KNN算法基于类比学习,即通过将给定的检验元组与和它相似的元组进行比较来学习。训练元组用n个属性描述,每个元组代表n维空间的一个点。所有的训练元组都存放在n维模式空间中
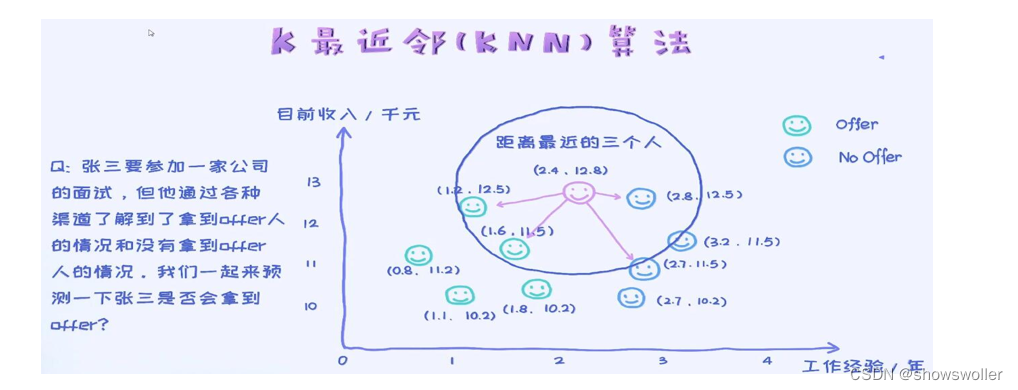
当给定一个未知元组时,KNN搜索模式空间,根据距离函数计算待分类样本X和每个训练样本的距离(作为相似度),选择与待分类样本距离最小的K个样本作为X的K个最近邻,最后以X的K个最近邻中的大多数样本所属的类别作为X的类别
如图7-4所示,有方块和三角形两类数据,它们分布在二维特征空间中。假设有一个新数据(圆点)需要预测其所属的类别,根据“物以类聚”,可以找到离圆点最近的几个点,以它们中的大多数点的类别决定新数据所属的类别。如果k = 3,由于圆点近邻的3个样本中,三角形占比2/3,则认为新数据属于三角形类别。同理,k = 5,则新数据属于正方形类别
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











