




梯度计算:
Tensor是这个包的核心类,如果将其属性.requires_grad设置为True,它将开始追踪(track)在其上的所有操作(这样就可以利用链式法则进行梯度传播了)。完成计算后,可以调用.backward()来完成所有梯度计算。此Tensor的梯度将累积到.grad属性中。
生成器生成数据:
#
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batch
yield features.index_select(0, j), labels.index_select(0, j)pytorch定义模块:
首先,导入torch.nn模块。实际上,“nn”是neural networks(神经网络)的缩写。顾名思义,该模块定义了大量神经网络的层。之前我们已经用过了autograd,而nn就是利用autograd来定义模型。nn的核心数据结构是Module,它是一个抽象概念,既可以表示神经网络中的某个层(layer),也可以表示一个包含很多层的神经网络。在实际使用中,最常见的做法是继承nn.Module,撰写自己的网络/层。一个nn.Module实例应该包含一些层以及返回输出的前向传播(forward)方法。
维度添加:torch.nn仅支持输入一个batch的样本不支持单个样本输入,如果只有单个样本,可使用input.unsqueeze(0)来添加一维
使用torchvision包:
它是服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision主要由以下几部分构成:
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;torchvision.utils: 其他的一些有用的方法。-
通过torchvision的
torchvision.datasets来下载这个数据集。第一次调用时会自动从网上获取数据。我们通过参数train来指定获取训练数据集或测试数据集(testing data set)。测试数据集也叫测试集(testing set),只用来评价模型的表现,并不用来训练模型。另外我们还指定了参数
transform = transforms.ToTensor()使所有数据转换为Tensor,如果不进行转换则返回的是PIL图片。transforms.ToTensor()将尺寸为 (H x W x C) 且数据位于[0, 255]的PIL图片或者数据类型为np.uint8的NumPy数组转换为尺寸为(C x H x W)且数据类型为torch.float32且位于[0.0, 1.0]的Tensor。
激活函数:
虽然神经网络引入了隐藏层,却依然等价于一个单层神经网络:设计依然只能与仅含输出层的单层神经网络等价。
上述问题的根源在于全连接层只是对数据做仿射变换(affine transformation),而多个仿射变换的叠加仍然是一个仿射变换。解决问题的一个方法是引入非线性变换,例如对隐藏变量使用按元素运算的非线性函数进行变换,然后再作为下一个全连接层的输入。这个非线性函数被称为激活函数(activation function)。
one_hot编码:
为了将词表示成向量输入到神经网络,一个简单的办法是使用one-hot向量。假设词典中不同字符的数量为NNN(即词典大小vocab_size),每个字符已经同一个从0到N−1N-1N−1的连续整数值索引一一对应。如果一个字符的索引是整数iii, 那么我们创建一个全0的长为NNN的向量,并将其位置为iii的元素设成1。该向量就是对原字符的one-hot向量。下面分别展示了索引为0和2的one-hot向量,向量长度等于词典大小
循环神经网络中较容易出现梯度衰减或梯度爆炸。我们会在6.6节(通过时间反向传播)中解释原因。为了应对梯度爆炸,我们可以裁剪梯度(clip gradient)。假设我们把所有模型参数梯度的元素拼接成一个向量 g\boldsymbol{g}g,并设裁剪的阈值是θ\thetaθ。裁剪后的梯度: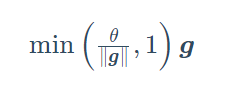
的L2L_2L2范数不超过θ\thetaθ。
困惑度:
通常使用困惑度(perplexity)来评价语言模型的好坏。回忆一下3.4节(softmax回归)中交叉熵损失函数的定义。困惑度是对交叉熵损失函数做指数运算后得到的值。特别地,
- 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
- 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
- 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在本例中,困惑度必须小于词典大小vocab_size。
定义,模型:
PyTorch中的nn模块提供了循环神经网络的实现。下面构造一个含单隐藏层、隐藏单元个数为256的循环神经网络层rnn_layer。
num_hiddens = 256
# rnn_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens) # 已测试
rnn_layer = nn.RNN(input_size=vocab_size, hidden_size=num_hiddens)Copy to clipboardErrorCopied与上一节中实现的循环神经网络不同,这里rnn_layer的输入形状为(时间步数, 批量大小, 输入个数)。其中输入个数即one-hot向量长度(词典大小)。此外,rnn_layer作为nn.RNN实例,在前向计算后会分别返回输出和隐藏状态h,其中输出指的是隐藏层在各个时间步上计算并输出的隐藏状态,它们通常作为后续输出层的输入。需要强调的是,该“输出”本身并不涉及输出层计算,形状为(时间步数, 批量大小, 隐藏单元个数)。而nn.RNN实例在前向计算返回的隐藏状态指的是隐藏层在最后时间步的隐藏状态:当隐藏层有多层时,每一层的隐藏状态都会记录在该变量中;对于像长短期记忆(LSTM),隐藏状态是一个元组(h, c),即hidden state和cell state。我们会在本章的后面介绍长短期记忆和深度循环神经网络。关于循环神经网络(以LSTM为例)的输出,可以参考下图(图片来源)。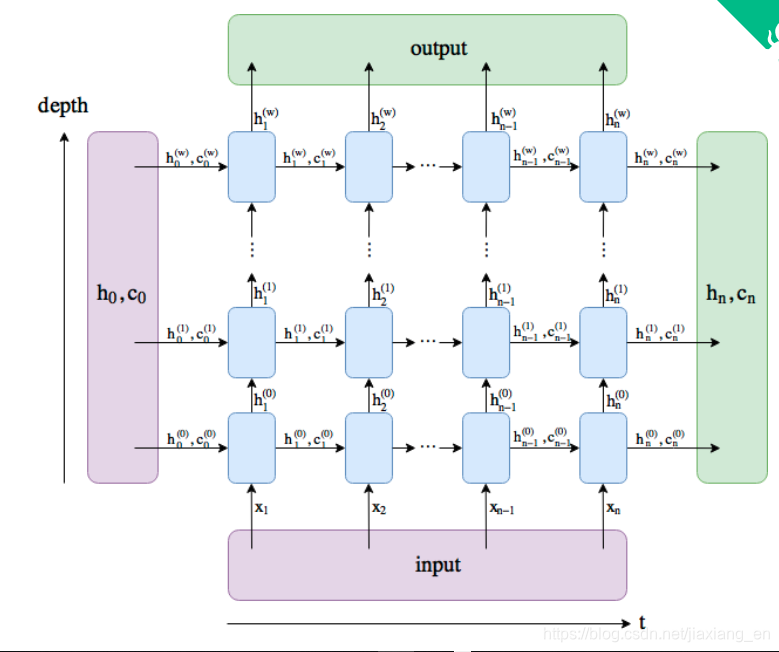
循环神经网络(以LSTM为例)的输出
输出形状为(时间步数, 批量大小, 隐藏单元个数),隐藏状态h的形状为(层数, 批量大小, 隐藏单元个数)。


















 1987
1987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









