







文章目录
http 协议是 第七层协议,其在前、后端、移动端都很常用,通常都用 json 传递,但其实也有很多传递方式,本文将对 Content-Type 一探究竟。
一、协议
HTTP 标准由 IETF 组织制定,跟它相关的标准主要有两份:
- HTTP1.1 https://tools.ietf.org/html/rfc2616
- HTTP1.1 https://tools.ietf.org/html/rfc7234
HTTP 协议是基于 TCP 协议出现的,对 TCP 协议来说,TCP 协议是一条双向的通讯通道,HTTP 在 TCP 的基础上,规定了 Request-Response 的模式。这个模式决定了通讯必定是由浏览器端首先发起的。
大部分情况下,浏览器的实现者只需要用一个 TCP 库,甚至一个现成的 HTTP 库就可以搞定浏览器的网络通讯部分。HTTP 是纯粹的文本协议,它是规定了使用 TCP 协议来传输文本格式的一个应用层协议。
下面,我们试着用一个纯粹的 TCP 客户端来手工实现 HTTP 一下:
首先我们运行 telnet,连接到极客时间主机,在命令行里输入以下内容:
telnet www.baidu.com 80
Trying 220.181.38.150...
Connected to www.a.shifen.com.
Escape character is '^]'.
这个时候,TCP 连接已经建立,我们输入以下字符作为请求:
GET / HTTP/1.1
Host: www.baidu.com
按下两次回车,我们收到了服务端的回复:
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: no-cache
Connection: keep-alive
Content-Length: 9508
Content-Security-Policy: frame-ancestors 'self' https://chat.baidu.com http://mirror-chat.baidu.com https://fj-chat.baidu.com https://hba-chat.baidu.com https://hbe-chat.baidu.com https://njjs-chat.baidu.com https://nj-chat.baidu.com https://hna-chat.baidu.com https://hnb-chat.baidu.com http://debug.baidu-int.com;
Content-Type: text/html
Date: Fri, 28 Jul 2023 15:06:19 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Pragma: no-cache
Server: BWS/1.1
Set-Cookie: BAIDUID=679ACD7CD7920A1E015E8A75FDA518DC:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BIDUPSID=679ACD7CD7920A1E015E8A75FDA518DC; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: PSTM=1690556779; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BAIDUID=679ACD7CD7920A1E71930DACD7E8B6C6:FG=1; max-age=31536000; expires=Sat, 27-Jul-24 15:06:19 GMT; domain=.baidu.com; path=/; version=1; comment=bd
Traceid: 1690556779278206132211758362479569606702
Vary: Accept-Encoding
X-Ua-Compatible: IE=Edge,chrome=1
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="description" content=" 全球领先的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜 索结果。">
这就是一次完整的 HTTP 请求的过程了,我们可以看到,在 TCP 通道中传输的,完全是文本。
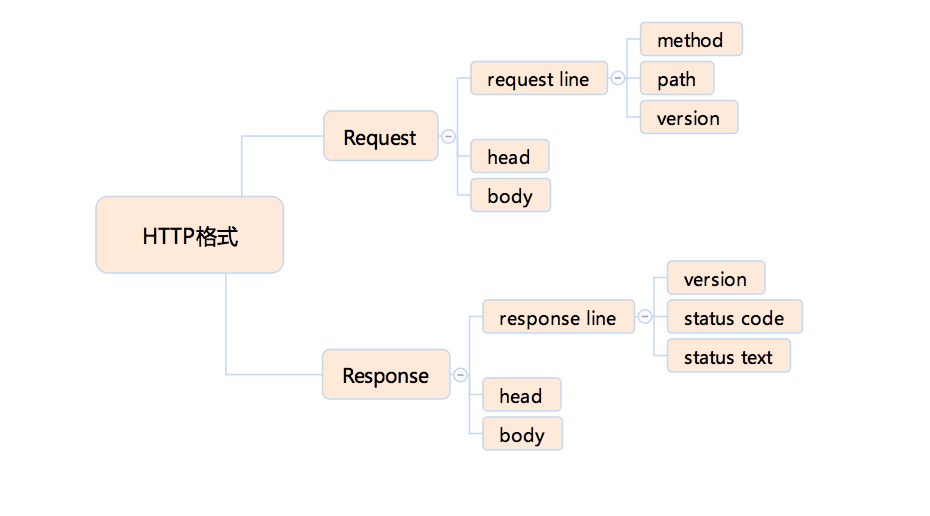
在请求部分,第一行被称作 request line,它分为三个部分,HTTP Method,也就是请求的“方法”,请求的路径和请求的协议和版本。
在响应部分
- 第一行被称作 response line,它也分为三个部分,协议和版本、状态码和状态文本。
- 紧随在 request line 或者 response line 之后,是请求头 / 响应头,这些头由若干行组成,每行是用冒号分隔的名称和值。
- 在头之后,以一个空行(两个换行符)为分隔,是请求体 / 响应体,请求体可能包含文件或者表单数据,响应体则是 html 代码。
HTTP 协议格式如下:
1.1 Method
常有的有GET、POST、PUT(全量编辑)、PATCH(增量编辑)、DELETE、HEAD(仅头部)、OPTIONS等。CONNECT 现在多用于 HTTPS 和 WebSocket。OPTIONS 和 TRACE 一般用于调试,多数线上服务都不支持。
1.1.1 HEAD
HEAD 类似 GET,但因为只返回 header 所以速度更快。 浏览器常用此方式检查资源是否变化,若未变化则复用缓存,否则用 GET 重新请求资源。
1.2 Status
- 1xx:临时回应,表示客户端请继续。对前端来说,1xx 系列的状态码是非常陌生的,原因是 1xx 的状态被浏览器 http 库直接处理掉了,不会让上层应用知晓。
- 2xx:请求成功。
- 200:请求成功。
- 3xx: 表示请求的目标有变化,希望客户端进一步处理。
- 301&302:永久性与临时性跳转。即实际上 301 更接近于一种报错,提示客户端下次别来了。
- 304:跟客户端缓存没有更新。即客户端本地已经有缓存的版本,并且在 Request 中告诉了服务端,当服务端通过时间或者 tag,发现没有更新的时候,就会返回一个不含 body 的 304 状态。
- 4xx:客户端请求错误。
- 403:无权限。
- 404:表示请求的页面不存在。
- 418:It’s a teapot. 这是一个彩蛋,来自 ietf 的一个愚人节玩笑。(超文本咖啡壶控制协议)
- 5xx:服务端请求错误。
- 500:服务端错误。
- 503:服务端暂时性错误,可以一会再试。
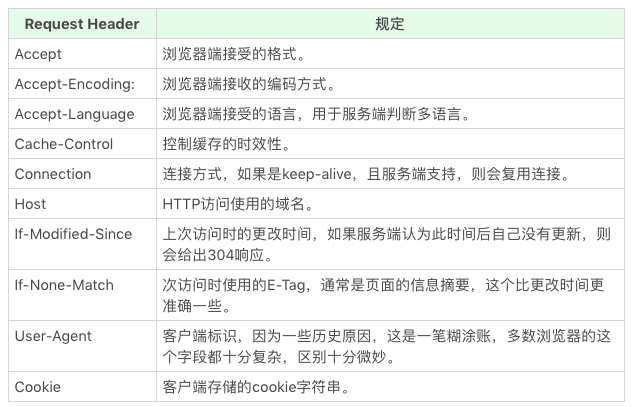
1.3 Http Head(Http 头)
HTTP 头可以看作一个键值对。原则上,HTTP 头也是一种数据,我们可以自由定义 HTTP 头和值。不过在 HTTP 规范中,规定了一些特殊的 HTTP 头,我们现在就来了解一下其中几个重要的。(完整列表请参考 rfc2616 标准)
Request Header 如下:
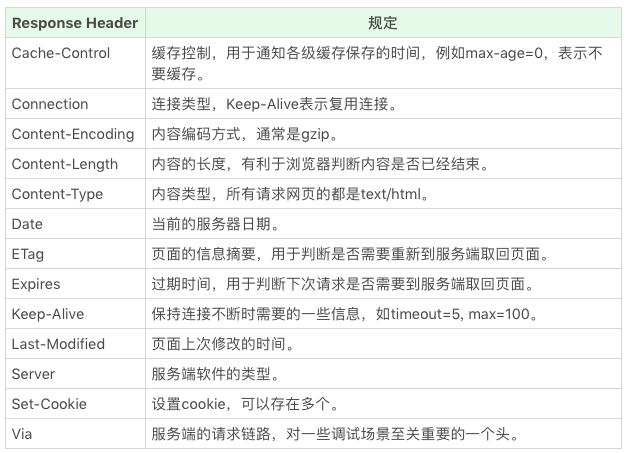
Response Header 如下:
1.3.1 Http Request Body
HTTP 请求的 body 主要用于提交表单场景。实际上,http 请求的 body 是比较自由的,只要浏览器端发送的 body 服务端认可就可以了。一些常见的 body 格式是:
- application/json
- application/x-www-form-urlencoded
- multipart/form-data
- text/xml
我们使用 html 的 form 标签提交产生的 html 请求,默认会产生 application/x-www-form-urlencoded 的数据格式,当有文件上传时,则会使用 multipart/form-data。
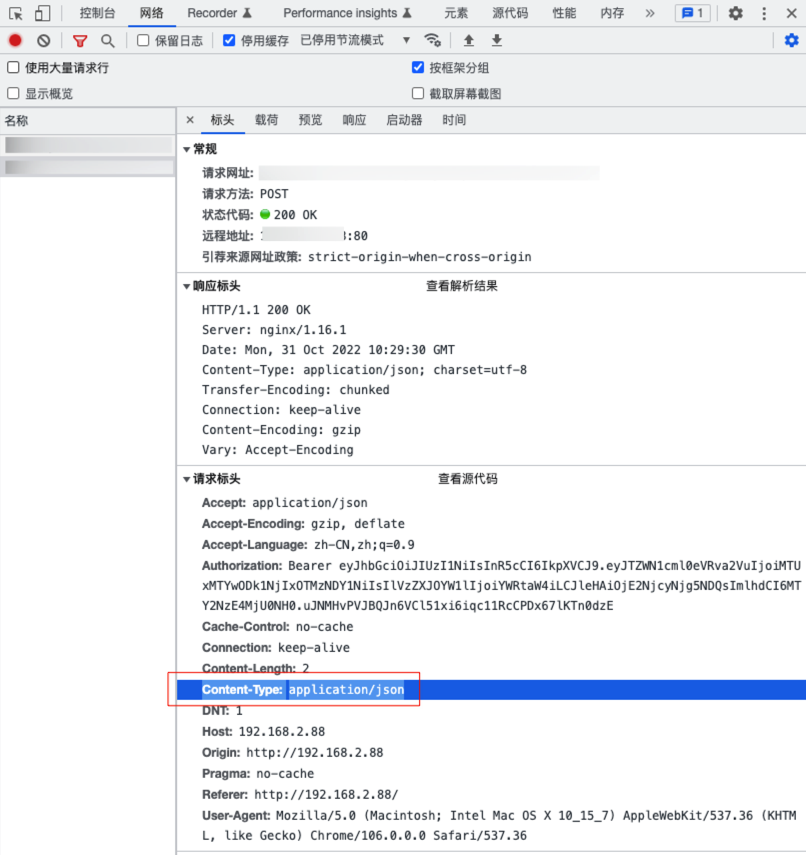
1.3.1.1 Content-Type
Content-Type 用于指明 http 协议的媒体类型(传文本,文件,图片,还是视频等),在 chrome 的 F12 开发者工具可以看到 Content-Type,如下图所示:
其由三部分组成:
- media type:媒体类型(如 application/json),接收方根据 media type 来处理不同的数据内容(如文件、图片或视频等)
- charset:字符类型(如 utf-8)
- boundary:分隔符(是唯一的一个字符串,用来将较长的内容分隔开,如-----------------------------340073633417401055292887335273)
其中 media type 有如下值域:
# Application
application/EDI-X12
application/EDIFACT
application/javascript
application/octet-stream
application/ogg
application/pdf
application/xhtml+xml
application/x-shockwave-flash
application/json
application/ld+json
application/xml
application/zip
application/x-www-form-urlencoded
# Audio
audio/mpeg
audio/x-ms-wma
audio/vnd.rn-realaudio
audio/x-wav
# Image
image/gif
image/jpeg
image/png
image/tiff
image/vnd.microsoft.icon
image/x-icon
image/vnd.djvu
image/svg+xml
# Multipart
multipart/mixed
multipart/alternative
multipart/related (using by MHTML (HTML mail).)
multipart/form-data
# Text
text/css
text/csv
text/html
text/javascript (obsolete)
text/plain
text/xml
# Video
video/mpeg
video/mp4
video/quicktime
video/x-ms-wmv
video/x-msvideo
video/x-flv
video/webm
1.3.1.2 miultipart/form-data
在 postman 中即可选 multipart/form-data 类型,其中可同时传图片、文件和文本,示例如下:
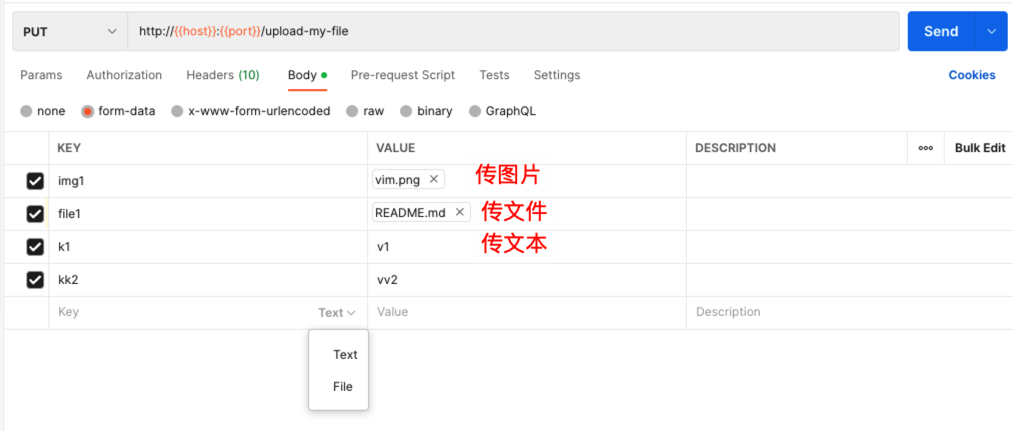
我们来看一个简单的 form 表单:
<form action="/submit" method="POST" enctype="multipart/form-data">
<input type="text" name="username"><br>
<input type="text" name="password"><br>
<button>提交</button>
</form>
当提交的时候,查看浏览器的网络请求:
请求头:
POST /submit HTTP/1.1
Host: localhost:3000
Accept-Encoding: gzip, deflate
Content-Type: multipart/form-data; boundary=---------------------------340073633417401055292887335273
Content-Length: 303
请求体:
-----------------------------340073633417401055292887335273
Content-Disposition: form-data; name="username"
张三
-----------------------------340073633417401055292887335273
Content-Disposition: form-data; name="password"
123456
-----------------------------340073633417401055292887335273--
具体格式是这样的:
...
Content-Type: multipart/form-data; boundary=${boundary}
--${boundary}
...
...
--${boundary}--
这就是 multipart/form-data 的传输过程了,但是这里面有三个大坑:
请求头 Content-Type 里面的 boundary 分隔符比请求体用的分隔符少了两个杠(-)
从请求头中取分隔符之后,一定要在之前加两个 - 再对请求体进行分割
请求头 Content-Length 的换行用的是 \r\n 而不是 \n
请求体的真实面目是下面的字符串:
“-----------------------------340073633417401055292887335273\r\nContent-Disposition: form-data; name=“username”\r\n\r\n张三\r\n-----------------------------340073633417401055292887335273\r\nContent-Disposition: form-data; name=“password”\r\n\r\n123456\r\n-----------------------------340073633417401055292887335273–\r\n”
请求头 Content-Length 的值表示字节的长度,而不是字符串的长度
因为字节的长度跟编码无关,而字符串的长度往往跟编码有关,举个例子,在 utf8 编码下:
console.log('a1'.length) // 2
console.log(Buffer.from('a1').length) // 2
console.log('张三'.length) // 2
console.log(Buffer.from('张三').length) // 6
如果仅仅是基本的字符串类型,完全可以用 www-form-urlencoded 来进行传输,multipart/form-data 强大的地方是其能够传输二进制文件的能力,我们看一下如果包含二进制文件的话应该如何处理。我们增加一个 file 类型的 input,上传一张图片作为头像,发现请求体多出了一部分:
-----------------------------114007818631328932362459060915
Content-Disposition: form-data; name="avatar"; filename="1.jpg"
Content-Type: image/jpeg
xxxxxx文件的二进制数据xxxxx
可以发现,文件类型的 part 跟之前字符串的格式有所不同了,head 部分有两个头字段,多出一个 Content-Type 头,而且 Content-Disposition 头多出来 filename 字段,body 部分是文件的二进制数据。
了解这这些规律之后,接下来就可以在服务端对 multipart/form-data 进行解码了:
const http = require('http')
const fs = require('fs')
http
.createServer(function (req, res) {
// 获取 content-type 头,格式为: multipart/form-data; boundary=--------------------------754404743474233185974315
const contentType = req.headers['content-type']
const headBoundary = contentType.slice(contentType.lastIndexOf('=') + 1) // 截取 header 里面的 boundary 部分
const bodyBoundary = '--' + headBoundary // 前面加两个 - 才是 body 里面真实的分隔符
const arr = [], obj = {}
req.on('data', (chunk) => arr.push(chunk))
req.on('end', function () {
const parts = Buffer.concat(arr).split(bodyBoundary).slice(1, -1) // 根据分隔符进行分割
for (let i = 0; i < parts.length; i++) {
const { key, value } = handlePart(parts[i])
obj[key] = value
}
res.end(JSON.stringify(obj))
})
})
.listen(3000)
// 对分隔出来的每一部分单独处理,如果是二进制的就保存到文件,是字符串就返回键值对:
function handlePart(part) {
const [head, body] = part.split('\r\n\r\n') // buffer 分割
const headStr = head.toString()
const key = headStr.match(/name="(.+?)"/)[1]
const match = headStr.match(/filename="(.+?)"/)
if (!match) {
const value = body.toString().slice(0, -2) // 把末尾的 \r\n 去掉
return { key, value }
}
const filename = match[1]
const content = part.slice(head.length + 4, -2) // 文件二进制部分是 head + \r\n\r\n 再去掉最后的 \r\n
fs.writeFileSync(filename, content)
return { key, value: filename }
}
// 这里面涉及到 buffer 的分割,nodejs 中并没有提供 split 方法,可根据 slice 方法自己实现
Buffer.prototype.split = function (sep) {
let sepLength = sep.length, arr = [], offset = 0, currentIndex = 0
while ((currentIndex = this.indexOf(sep, offset)) !== -1) {
arr.push(this.slice(offset, currentIndex))
offset = currentIndex + sepLength
}
arr.push(this.slice(offset))
return arr
}
1.3.1.3 x-www-form-urlencoded
Get 方法通常用 Content-Type = application/x-www-form-urlencoded 方式,而在 url 中有两种方式:
- query:即在 url 尾部用
www.ppp.com/qqq/?a=x&b=y&c=z使用,其语义是参数,且可传递多个参数 - path:即在 url 中间用
www.ppp.com/qq q使用,其语义是 RESTful 来表示资源,通常放置 id、name 这些信息等
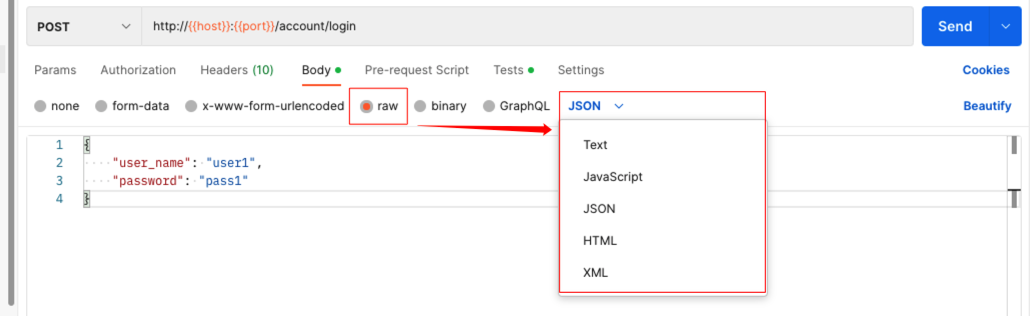
1.3.1.4 application/json
在 postman 软件,即可设置为 application/json 方式,这是 web 端文本常用的消息格式,示例如下:
1.4 HTTP 2
HTTP 2 是 HTTP 1.1 的升级版本,你可以查看它的详情链接
HTTP 2.0 最大的改进有两点
- 支持服务端推送:服务端推送能够在客户端发送第一个请求到服务端时,提前把一部分内容推送给客户端,放入缓存当中,这可以避免客户端请求顺序带来的并行度不高,从而导致的性能问题。
- 支持 TCP 连接复用:使用同一个 TCP 连接来传输多个 HTTP 请求,避免了 TCP 连接建立时的三次握手开销,和初建 TCP 连接时传输窗口小的问题。(PS: 其实很多优化涉及更下层的协议。IP 层的分包情况,和物理层的建连时间是需要被考虑的。)
二、HTTPS
在 HTTP 协议的基础上,HTTPS 和 HTTP2 规定了更复杂的内容,但是它基本保持了 HTTP 的设计思想,即:使用上的 Request-Response 模式。
我们首先来了解下 HTTPS。HTTPS 有两个作用,一是确定请求的目标服务端身份,二是保证传输的数据不会被网络中间节点窃听或者篡改。
HTTPS 的标准也是由 RFC 规定的,你可以查看它的详情链接
HTTPS 是使用加密通道来传输 HTTP 的内容:HTTPS 首先与服务端建立一条 TLS 加密通道。TLS 构建于 TCP 协议之上,它实际上是对传输的内容做一次加密,所以从传输内容上看,HTTPS 跟 HTTP 没有任何区别。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











