




一、说明
DeepSeek R1+蒸馏模型组是基于DeepSeek-R1模型体系,通过知识蒸馏技术优化形成的系列模型,旨在平衡性能与效率。
1、技术路径与核心能力
基础架构与训练方法
- DeepSeek-R1-Zero:通过强化学习(RL)训练,未使用监督微调(SFT),具备初步推理能力5。
- DeepSeek-R1:融合冷启动数据,采用多阶段SFT与RL交替训练,显著提升复杂任务(如科学预测、实验设计)的准确性15。
- 蒸馏模型:以DeepSeek-R1为教师模型,生成推理数据并蒸馏至小规模学生模型(如Qwen系列),降低计算资源需求35。
关键优化能力
- 思维链蒸馏:通过自然语言交互生成思维链数据集,提升模型在分子预测、材料设计等科学领域的逻辑推理能力17。
- 高效推理:蒸馏后的小模型(如1.5B、7B版本)在数学问题、代码生成等场景中,性能接近大模型但运行速度更快67。
2、模型版本与开源生态
主流蒸馏模型版本
- 参数规模覆盖1.5B至70B,包括DeepSeek-R1-Distill-Qwen-1.5B/7B/14B/32B/70B,适配不同算力需求。
- 官方验证显示,32B与70B模型性能对标OpenAI o1-mini,但训练成本仅为十分之一。
开源支持与工具链
- Open-R1项目:提供单卡(如RTX 4090)蒸馏复现方案,支持从数据生成到模型合并的全流程。
- 第三方平台集成:如百度智能云千帆ModelBuilder,支持3小时内完成模型蒸馏,降低开发者门槛。
3、应用场景与实践效果
科学计算与工业设计
- 通过API调用实现科学术语增强、实验方案优化,提升材料预测与分子设计的准确性1。
- 典型案例:中国移动研究院AI4S工作站已部署满血版DeepSeek-R1,支持科研团队进行模型蒸馏1。
教育与竞赛场景
- 数学问题解答场景中,蒸馏模型通过逻辑链数据训练,输出准确性接近教师模型。
- 开源社区中,开发者可基于OrangePi AI Studio等设备部署蒸馏模型,实现低成本AI推理。
4、训练与部署建议
硬件与工具配置
- 单卡训练推荐:NVIDIA TESLA T4 16G或RTX 4090,搭配CUDA 12.4、PyTorch 2.6.0等环境。
- 工具链:HuggingFace Transformers、Weights & Biases(实验跟踪)、Unsloth(加速训练)。
微调注意事项
- 部分实践表明,直接微调蒸馏后的小模型(如Qwen-7B)可能效果有限,建议优先复用官方蒸馏数据集。
- 训练过程需监控损失函数变化,并通过WandB等工具可视化调优。
五、总结
DeepSeek R1+蒸馏模型组通过“大模型生成-小模型学习”路径,实现了高性能与低成本的平衡。其在科学计算、教育等领域的应用已验证其潜力,而开源生态与工具链支持进一步降低了开发者使用门槛。未来,随着蒸馏技术的持续优化,轻量级模型的实际效能有望进一步逼近原版
二、 本文硬件配置
1、蒸馏模型所需显存列表
| DeepSeek R1 蒸馏模型 | 推理性能 | 半精度所需显卡 | 正常所需显卡 |
|---|---|---|---|
| DeepSeek-R1-1.5B(Distill) | GPT4o级 | 1.1G | 4G |
| DeepSeek-R1-7B(Distill) | 超越GPT4o | 4.7G | 14G |
| DeepSeek-R1-8B(Distill) | 超越GPT4o | 4.9G | 14G |
| DeepSeek-R1-14B(Distill) | 超越GPT4o | 9G | 24G |
| DeepSeek-R1-32B(Distill) | o1 mini级别 | 20G | 55G |
| DeepSeek-R1-70B(Distill) | o1 mini级别 | 43G | 120G |
| DeepSeek-R1-671B | o1级别 | 404G | 1000G |
2、部署硬件
Cloud Studio![]() https://ide.cloud.tencent.com/dashboard/gpu-workspace
https://ide.cloud.tencent.com/dashboard/gpu-workspace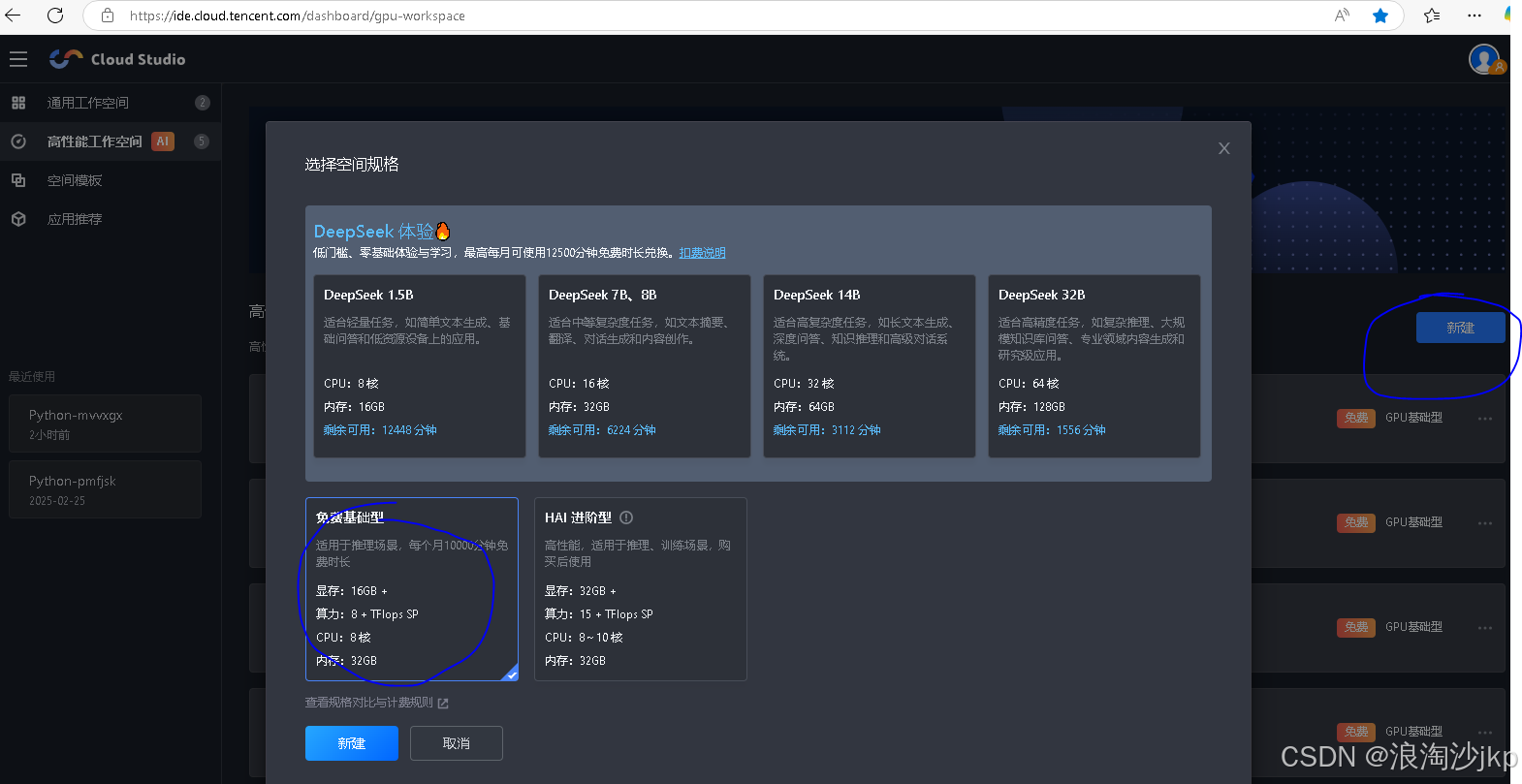

要看时候,现在用的人多,有时候没有资源,有时候进不去,不要钱就这么回事,不过开始用的还是爽,创建会要几分钟 ,我们就选这个,有16g显存

其实系统已经有了模型,但是我们是自己装喔
(base) root@VM-0-80-ubuntu:/# ollama list
NAME ID
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









