






一个Executor对应一个JVM进程。
从Spark的角度看,Executor占用的内存分为两部分:ExecutorMemory和MemoryOverhead
一、ExecutorMemory
ExecutorMemory为JVM进程的Java堆区域。大小通过属性spark.executor.memory设置。也可以在spark-submit命令时用参数--executor-memory设置。
用于缓存RDD数据的memoryStore位于这一区域。
memoryStore占用空间的比例通过属性spark.storage.memoryFraction和spark.storage.safetyFraction控制
相关源码:
-
//core/src/main/scala/org/apache/spark/storage/BlockManager.scala
-
/** Return the total amount of storage memory available. */
-
private def getMaxMemory(conf: SparkConf): Long = {
-
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
-
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
-
(Runtime.getRuntime.maxMemory * memoryFraction * safetyFraction).toLong
-
}
所以,一个Executor用于存储RDD的空间=(ExecutorMemory– MEMORY_USED_BY_RUNTIME)* spark.storage.memoryFraction *spark.storage.safetyFraction
二、MemoryOverhead
MemoryOverhead是JVM进程中除Java堆以外占用的空间大小,包括方法区(永久代)、Java虚拟机栈、本地方法栈、JVM进程本身所用的内存、直接内存(DirectMemory)等。通过spark.yarn.executor.memoryOverhead设置,单位MB。
相关源码:
-
//yarn/common/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
-
val MEMORY_OVERHEAD_FACTOR = 0.07
-
val MEMORY_OVERHEAD_MIN = 384
-
-
//yarn/common/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala
-
protected val memoryOverhead: Int = sparkConf.getInt("spark.yarn.executor.memoryOverhead",
-
math.max((MEMORY_OVERHEAD_FACTOR * executorMemory).toInt, MEMORY_OVERHEAD_MIN))
-
......
-
val totalExecutorMemory = executorMemory + memoryOverhead
-
numPendingAllocate.addAndGet(missing)
-
logInfo(s"Will allocate $missing executor containers, each with $totalExecutorMemory MB " +
-
s"memory including $memoryOverhead MB overhead")
三、相关问题
如果用于存储RDD的空间不足,先存储的RDD的分区会被后存储的覆盖。当需要使用丢失分区的数据时,丢失的数据会被重新计算
如果Java堆或者永久代的内存不足,则会产生各种OOM异常,executor会被结束。spark会重新申请一个Container运行executor。失败executor上的任务和存储的数据会在其他executor上重新计算。
如果实际运行过程中ExecutorMemory+MemoryOverhead之和(JVM进程总内存)超过container的容量。YARN会直接杀死container。executor日志中不会有异常记录。spark同样会重新申请container运行executor。
在Java堆以外的JVM进程内存占用较多的情况下,应该将MemoryOverhead设置为一个足够大的值,应该将MemoryOverhead设置为一个足够大的值,以防JVM进程因实际占用的内存超标而被kill。如果默认值(math.max((MEMORY_OVERHEAD_FACTOR*executorMemory).toInt,MEMORY_OVERHEAD_MIN)不够大,可以通过spark.yarn.executor.memoryOverhead手动设置一个更大的值。
Spark统一内存管理
1.6.0的统一内存管理如下:
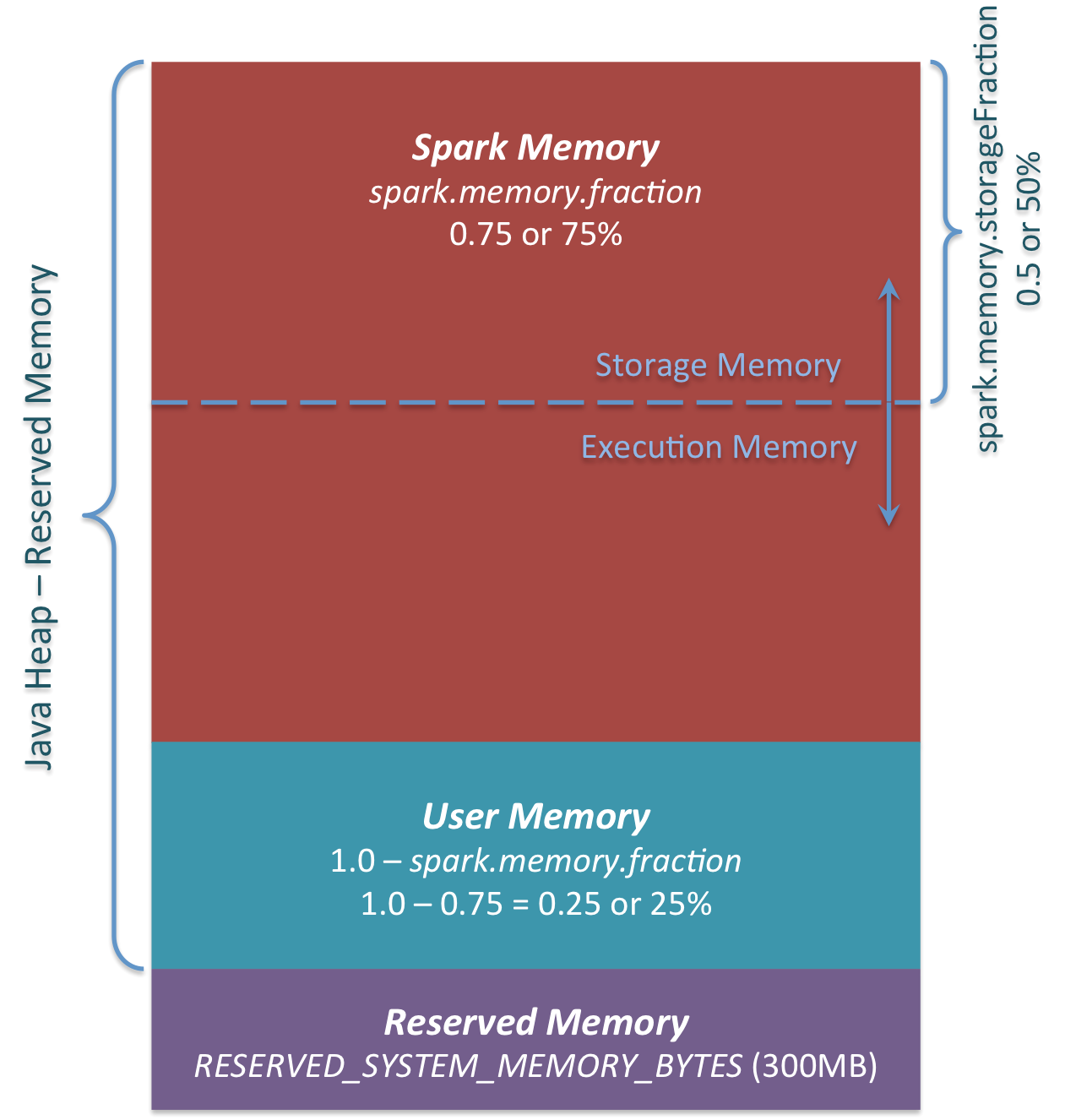
主要有三部分组成:
1 Reserved Memory
这部分内存是预留给系统使用,是固定不变的。在1.6.0默认为300MB(RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 1024),这一部分内存不计算在spark execution和storage中,除了重新编译spark和spark.testing.reservedMemory,Reserved Memory是不可以改变的,spark.testing.reservedMemory不推荐使用在实际运行环境中。是用来存储Spark internal objects,并且限制JVM的大小,如果executor的大小小于1.5 * Reserved Memory = 450MB ,那么就会报 “please use larger heap size”的错误,源码如下。
val minSystemMemory = reservedMemory * 1.5
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please use a larger heap size.")
}2 User Memory
分配Spark Memory剩余的内存,用户可以根据需要使用。可以存储RDD transformations需要的数据结构,例如, 重写spark aggregation,使用mapPartition transformation,通过hash table来实现aggregation,这样使用的就是User Memory。在1.6.0中,计算方法为(“Java Heap” – “Reserved Memory”) * (1.0 – spark.memory.fraction),默认为(“Java Heap” – 300MB) * 0.25,比如4GB的heap大小,那么User Memory的大小为949MB。由用户来决定存储的数据量,因此要遵守这个边界,不然会导致OOM。
3 Spark Memory
计算方式是(“Java Heap” – “Reserved Memory”) * spark.memory.fraction,在1.6.0中,默认为(“Java Heap” – 300MB) * 0.75。例如推的大小为4GB,那么Spark Memory为2847MB。Spark Memory又分为Storage Memory和Execution Memory两部分。两个边界由spark.memory.storageFraction设定,默认为0.5。但是两部分可以动态变化,相互之间可以借用,如果一方使用完,可以向另一方借用。先看看两部分是如何使用的。
-
Storage Memory 用来存储
spark cached data也可作为临时空间存储序列化unroll,broadcast variables作为cached block存储,但是需要注意,这是unroll源码,unrolled block如果内存不够,会存储在driver端。broadcast variables大部分存储级别为MEMORY_AND_DISK。 -
Execution Memory 存储Spark task执行过程中需要的对象,例如,Shuffle中map端中间数据的存储,以及hash aggregation中的hash table。如果内存不足,该空间也容许spill到磁盘。
Execution Memory不可以淘汰block,不然执行的时候就会fail,如果找不到block。Storage Memory中的内容可以淘汰。Execution Memory满足两种情况可以向Storage Memory借用空间:
-
Storage Memory还有free空间 -
Storage Memory大于初始化时的空间("Spark Memory" * spark.memory.storageFraction = (“Java Heap” – “Reserved Memory”) * spark.memory.fraction * spark.memory.storageFraction)
Storage Memory只有在Execution Memory有free空间时,才可以借用

















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









