 谷歌发布Gemini:原生多模态大模型挑战AI新纪元,
谷歌发布Gemini:原生多模态大模型挑战AI新纪元,





 谷歌CEO宣布推出Gemini,一个强大的原生多模态大模型,可在文本、代码等多种模态下高效处理。Gemini在复杂推理和多模态理解方面表现出色,但其实际效果和安全性受到部分测评质疑。
谷歌CEO宣布推出Gemini,一个强大的原生多模态大模型,可在文本、代码等多种模态下高效处理。Gemini在复杂推理和多模态理解方面表现出色,但其实际效果和安全性受到部分测评质疑。
Gemini来了,谷歌CEO皮猜和哈萨比斯在谷歌官网联名发文,宣布推出这一万众瞩目的多模态大模型。
引子
谷歌自2015年将围棋界人工智能程序AlphaGo正式发布,正式对外展示AI的实力,一直在潜心研究AI领域,2017年Google IO 大会更是将Mobile First TO AI First的决心对外公布,至今走过了近八年的旅程,并且一直在不断加速进步。
谷歌也是摩拳擦掌了许久,今天谷歌CEO皮猜对外发布了杀手锏的最新多模态大模型Gemini 1.0版本正式上线。
Gemini
Gemini 是Google迄今为止最强大、最通用的模型,它在许多领先的基准测试中都展现出了最先进的性能,它是 Google 各团队间共同努力的成果,它可以通过文本、代码、音频、图像和视频等进行推理和处理。
目前Gemini有三个版本:
-
Gemini Ultra —我们规模最大且功能最强大的模型,适用于高度复杂的任务。
-
Gemini Pro — 我们适用于各种任务的最佳模型。
-
Gemini Nano — 我们端侧设备上最高效的模型。
杀手锏--原生多模态大模型
现有的多模态模型的标准是分别训练不同模态的组件,然后将对应的组件通过粗略的逻辑进行模拟推断功能,但这些模型有时可以很好地完成描述图像等特定任务,但在专业性更强、更复杂的推理方面却显得捉襟见肘。
而谷歌最开始就Gemini 设计为原生多模态,在开始的预训练上就利用不同模态,然后再利用额外的多模态数据进行微调,进一步提高模型效果。
谷歌对此表示:这有助于 Gemini 从最初就能对输入的各种内容高效地进行理解和推理,远优于现有的多模态模型。
基准数据
多模态-MMMU
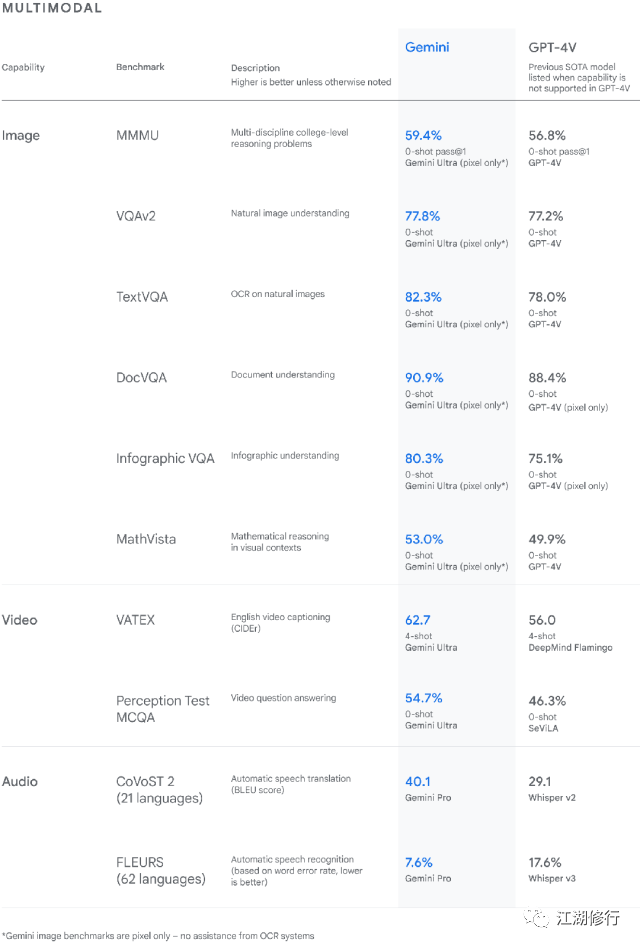
大语言--MMLU
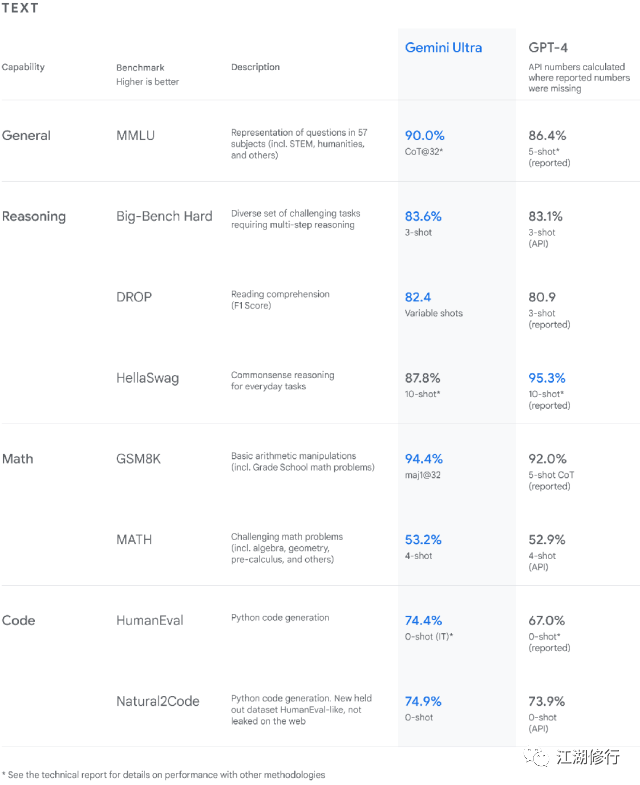
下一代能力--复杂推理&&多模态方向
据谷歌介绍Gemini在复杂推理方向,具有多模态的复杂推理能力,可帮助理解复杂的书面和视觉信息,进而可以在海量的数据中发掘难以辨别的知识内容。Gemini拥有通过阅读、过滤以及理解信息,从数十万份文件中提取见解的卓越能力。
Gemini可以同时识别并理解文本、图像、音频等多模态信息输入,所以它能更好地理解具有细微差别的信息,回答与复杂主题相关的问题。这就让它尤其擅长解释数学和物理等复杂科目中的推理。
致力于全球普及
谷歌强调:Gemini将通过谷歌产品推向数十亿用户。谷歌率先启用的是Gemini Pro版本,从今天起谷歌的聊天机器人Bard将由Gemini Pro微调版本驱动,谷歌认为这是Bard最大的一次升级。
谷歌还打算把Gemini引入手机:Pixel 8 Pro将是第一款运行Gemini Nano的智能手机。它可以支持录音应用中的“总结”等新功能,并在 Gboard 中推出“智能回复”功能,从 WhatsApp 开始,明年还将推出更多信息应用。
同时谷歌也即将开放Gemini能力,开发者和企业客户可以通过 Google AI Studio 或 Google Cloud Vertex AI 中的 Gemini API 获取 Gemini Pro。
针对近期频发的大模型安全和种族歧视等安全风险上,谷歌也表示Google AI 原则上和我们所有产品都应建立在强大的安全政策的基础上,谷歌正在增加新的保护措施,以满足 Gemini 的多模态能力。据了解Gemini 拥有迄今为止 Google 所有 AI 模型中最全面的安全评估,包括偏见和毒性评估。谷歌也在不断完善和推动大规模的信任和安全检查,包括向部分客户、开发者、合作伙伴以及安全和责任专家提供 Gemini共同评测。
结语
谷歌爆炸性且高调地发布了Gemini,并声称这是Google 迈进新纪元的开始,我们将继续快速创新,并以负责任的方式不断提升我们模型的能力。
谷哥今天的发布会也是一石激起千层浪,从谷哥发布会声势和基准性能数据可以看出,谷哥上下对Gemini抱有非常高的期待和赞许,这也是针对open ai一次强有力的反击,如果这次谷哥能成功,将有可能撼动目前open ai统治大模型领域地位的。但经一些发烧友和专家的测评,比如bard升级后能力并没有明显的提升,还有针对披露的技术报告中的细节和谷哥对外公布的基准测试数据,视频等内容也是出现了不少质疑的声音,不知道此刻的你有什么看法呢,认为是谷哥对AI技术一次重大突破,还是昙花一现的Demo技术,或是有其他观点,欢迎交流。
我自己也非常期待Gemini Ultra这个版本,目前它还没有落地应用,还在完善中。
感谢一键三连,给努力前行的你加油。


















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









