



 这篇博客介绍了在TensorFlow中如何使用`tf.nn.sparse_softmax_cross_entropy_with_logits`来计算损失,涉及Softmax函数的原理和Cross-Entropy损失函数的计算过程,以及稀疏标签的应用。
这篇博客介绍了在TensorFlow中如何使用`tf.nn.sparse_softmax_cross_entropy_with_logits`来计算损失,涉及Softmax函数的原理和Cross-Entropy损失函数的计算过程,以及稀疏标签的应用。
##c3d代码
原文链接:https://blog.youkuaiyun.com/ZJRN1027/article/details/80199248
cross_entropy_mean = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels,logits=logit)
)
tf.summary.scalar(
name_scope + ‘_cross_entropy’,
cross_entropy_mean
)
tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels,logits=logit)
logits为神经网络输出层的输出,shape为[batch_size,num_classes],
label为一个一维的vector,长度等于batch_size,每一个值的取值区间必须是[0,num_classes),其实每一个值就是代表了batch中对应样本的类别
tf.nn.sparse_softmax_cross_entropy_with_logits()首先来说,这个函数的具体实现分为了两个步骤,我们一步一步依次来看。
第一步:Softmax
不管是在进行文本分类还是图像识别等任务时,神经网络的输出层个神经元个数通常都是我们要分类的类别数量,也可以说,神经网络output vector的dimension通常为类别数量,而我们的Softmax函数的作用就是将每个类别所对应的输出分量归一化,使各个分量的和为1,这样可以理解为将output vector的输出分量值,转化为了将input data分类为每个类别的概率。举一个例子来说:
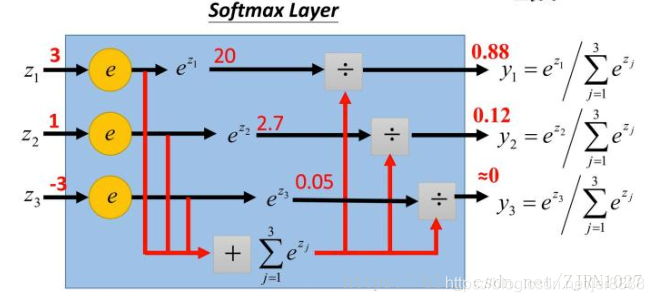
假设上面这个图中的Z1,Z2,Z3为一个三分类模型的output vector,为[3,1,-3],3代表类别1所对应的分量,1为类别2对应的分量,-3为类别3对应的分量。经过Softmax函数作用后,将其转化为了[0.88,0.12,0],这就代表了输入的这个样本被分到类别1的概率为0.88,分到类别2的概率为0.12,分到类别3的概率几乎为0。这就是Softmax函数的作用,Softmax函数的公式如下所示,我们就不做详细讲解了。
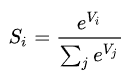
第二步:计算Cross-Entropy
神经网络的输出层经过Softmax函数作用后,接下来就要计算我们的loss了,这个这里是使用了Cross-Entropy作为了loss function。由于tf.nn.sparse_softmax_cross_entropy_with_logits()输入的label格式为一维的向量,所以首先需要将其转化为one-hot格式的编码,例如如果分量为3,代表该样本属于第三类,其对应的one-hot格式label为[0,0,0,1,…0],而如果你的label已经是one-hot格式,则可以使用tf.nn.softmax_cross_entropy_with_logits()函数来进行softmax和loss的计算。
转为one-hot格式之后就该计算我们的cross-entropy了,公式如下:
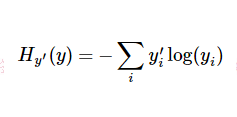
其中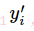 为label中的第i个值,yi为经softmax归一化输出的vector中的对应分量,由此可以看出,当分类越准确时,yi所对应的分量就会越接近于1,
为label中的第i个值,yi为经softmax归一化输出的vector中的对应分量,由此可以看出,当分类越准确时,yi所对应的分量就会越接近于1,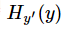 从而的值也就会越小。
从而的值也就会越小。
sparse 不用one-hot, 直接用标签计算交叉熵


















 3189
3189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









