







 本文介绍了使用Spark进行电影评分数据分析,包括最受欢迎电影、各年龄段男性/女性偏好、高评分电影筛选等。通过统计和排序展示了用户行为和电影热度的洞察。
本文介绍了使用Spark进行电影评分数据分析,包括最受欢迎电影、各年龄段男性/女性偏好、高评分电影筛选等。通过统计和排序展示了用户行为和电影热度的洞察。
数据来源:https://grouplens.org/datasets/movielens/
使用的文件内容如下:
用户表:

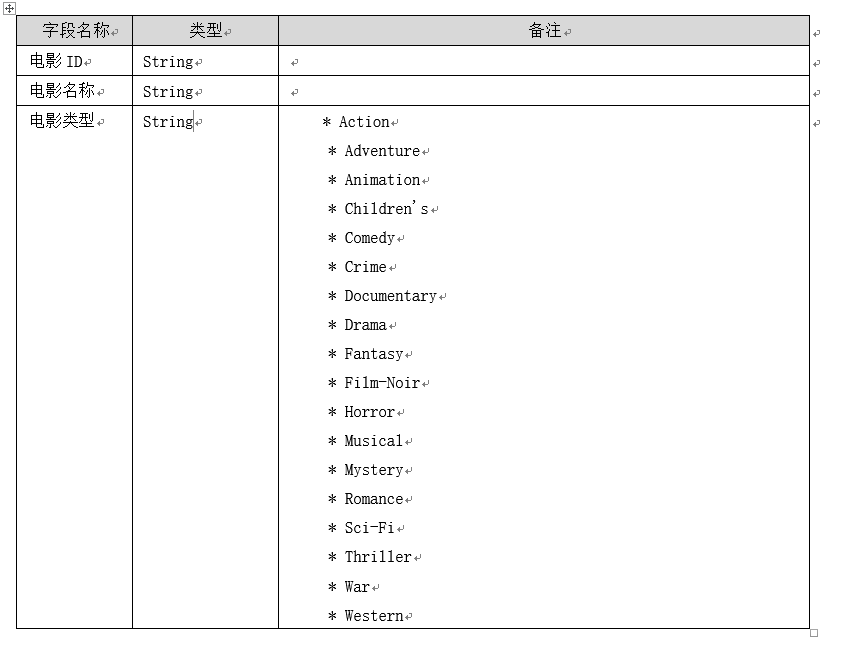
电影表:
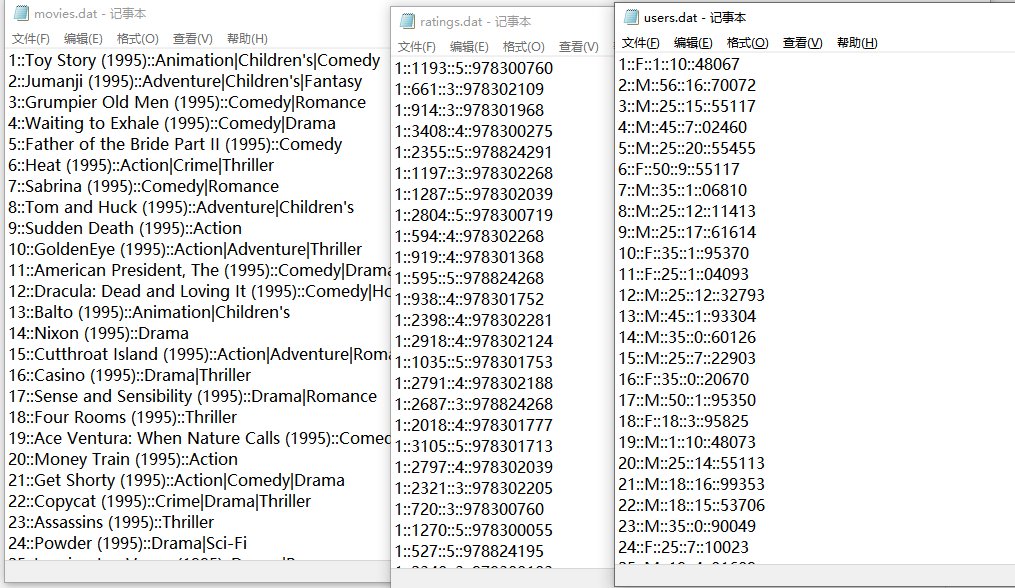
评分表:

三个表数据详情如下:
1、求被评分次数最多的 10 部电影,并给出评分次数(电影名,评分次数)
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_01{
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
//1、读取文件,提取需要的数据
// 用户id 性别
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
// 电影id 1
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
.map(x => (x(1),1))
//电影id 电影名
val movies = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\movies.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//(电影id,(电影名,1)) => (电影名,N)
val top10_movie = movies.join(ratings)
.map(x => (x._2._1, x._2._2))
.reduceByKey(_+_)
.takeOrdered(10)(Ordering[Int].reverse.on(x => x._2))
for (elem <- top10_movie) {println(elem)}
// TODO 关闭连接
sc.stop();
}
}
2、分别求男性,女性当中评分最高的 10 部电影(性别,电影名,影评分)
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_02 {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
//1、读取文件,提取需要的数据
// 用户id 性别
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
// 用户id (电影id,评分)
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
.map(x => (x(0),(x(1),x(2).toDouble)))
//电影id 电影名
val movies = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\movies.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//分别男女
val maleUsers = users.filter(x => x._2 == "F")
val femaleUsers = users.filter(x => x._2 == "M")
//(用户id,(性别,(电影id,评分))) => (电影id,(评分,1)) => 求和 =>(电影id,平均评分)
val maleMovie = maleUsers.join(ratings)
.map(x => (x._2._2._1,(x._2._2._2,1)))
.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))
.map(x => (x._1,x._2._1/x._2._2))
val femaleMovie = femaleUsers.join(ratings)
.map(x => (x._2._2._1,(x._2._2._2,1)))
.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))
.map(x => (x._1,x._2._1/x._2._2))
//(电影id,平均评分) => (电影id,(平均评分,电影名)) => (电影名,平均评分)
val maleMovieName = maleMovie.join(movies).map(x => (x._2._2, x._2._1))
val femaleMovieName = femaleMovie.join(movies).map(x => (x._2._2, x._2._1))
//取点击量最高的前10个
val top10_male = maleMovieName.takeOrdered(10)(Ordering[Double].reverse.on(x => x._2))
val top10_female = femaleMovieName.takeOrdered(10)(Ordering[Double].reverse.on(x => x._2))
println("男性:")
for (elem <- top10_male) {println(elem)}
println("女性: ")
for (elem <- top10_female) {println(elem)}
// TODO 关闭连接
sc.stop();
}
}
3、分别求男性,女性看过评分次数最多的 10 部电影(性别,电影名)
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_03{
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
//1、读取文件,提取需要的数据
// 用户id 性别
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
// 用户id 电影id
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//电影id 电影名
val movies = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\movies.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//分别男女
val maleUsers = users.filter(x => x._2 == "F")
val femaleUsers = users.filter(x => x._2 == "M")
//(用户id,(性别,电影id)) => (电影id,1) => (电影id,N)
val maleMovie = maleUsers.join(ratings).map(x => (x._2._2,1)).reduceByKey(_+_)
val femaleMovie = femaleUsers.join(ratings).map(x => (x._2._2,1)).reduceByKey(_+_)
//(电影id,(N,电影名)) => (电影名,N)
val maleMovieName = maleMovie.join(movies).map(x => (x._2._2, x._2._1))
val femaleMovieName = femaleMovie.join(movies).map(x => (x._2._2, x._2._1))
//取点击量最高的前10个
val top10_male = maleMovieName.takeOrdered(10)(Ordering[Int].reverse.on(x => x._2))
val top10_female = femaleMovieName.takeOrdered(10)(Ordering[Int].reverse.on(x => x._2))
println("男性:")
for (elem <- top10_male) {println(elem._1)}
println("女性: ")
for (elem <- top10_female) {println(elem._1)}
// TODO 关闭连接
sc.stop();
}
}
4、年龄段在“18-24”的男人,最喜欢看(评分次数最多的)10部电影
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_04 {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
// 用户id 性别
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.filter(x => x.toList(2) == "18") //年龄18~24
.map(x => (x(0),x(1)))
// 用户id 电影id
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//电影id 电影名
val movies = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\movies.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//取男性
val maleUsers = users.filter(x => x._2 == "F")
//(用户id,(性别,电影id)) => (电影id,1) => (电影id,N)
val maleMovie = maleUsers.join(ratings).map(x => (x._2._2,1)).reduceByKey(_+_)
//(电影id,(N,电影名)) => (电影名,N)
val maleMovieName = maleMovie.join(movies).map(x => (x._2._2, x._2._1))
//取点击量最高的前10个
val top10_male = maleMovieName.takeOrdered(10)(Ordering[Int].reverse.on(x => x._2))
for (elem <- top10_male) {println(elem._1)}
// TODO 关闭连接
sc.stop();
}
}
5、求 movieid = 2116 这部电影各年龄段(因为年龄就只有 7 个,就按这个 7 个分就好了)的平均影评(年龄段,影评分)
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_05 {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
// 用户id 年龄
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(2)))
// 用户id 评分
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
.filter(x => x(1) == "2116")
.map(x => (x(0),x(2)))
//(用户id,(年龄,评分)) => (年龄,(评分,1)) => (年龄,(sum评分,sum)) => (年龄,均值)
val score = users.join(ratings).map(x => (x._2._1.toInt, (x._2._2.toInt, 1)))
.reduceByKey((a,b) =>(a._1+b._1,a._2+b._2))
.map(x => (x._1, 1.0 * x._2._1 / x._2._2))
for (elem <- score.collect()) {
println(elem)
}
// TODO 关闭连接
sc.stop();
}
}
6、求最喜欢看电影(影评次数最多)的那位女性评最高分的 10 部电影的平均影评分(观影者,电影名,影评分)
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_06 {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
// 用户id 性别
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
// 用户id 电影id 评分
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
//电影id 电影名
val movies = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\movies.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//(用户id,1) => (用户id,(1,评分)) => (用户id,1) => 聚合(用户id,N) => 排序取最大的N
val top = ratings.map(x => (x(0), 1))
.join(users.filter(x => x._2 == "F"))
.map(x => (x._1, 1))
.reduceByKey(_ + _)
.takeOrdered(1)(Ordering[Int].reverse.on(x => x._2))
//最喜欢看电影的女性的id
val id = top(0)._1
//过滤id => (电影id,评分) => 取评分前10
val top10_movesId = ratings.filter(x => x(0) == id)
.map(x => (x(1), x(2)))
.takeOrdered(10)(Ordering[Int].reverse.on(x => x._2.toInt))
for (elem <- top10_movesId) {
// 当前电影id
val moveId = elem._1
// 当前电影名
val moveName = movies.filter(x => x._1 == moveId).collect()(0)._2
// 过滤电影 => 统计得分(moveName,(评分,1)) => (moveName (sum评分,sum)) => (moveName,平均评分)
val score = ratings.filter(x => x(1) == moveId)
.map(x => (moveName, (x(2).toInt, 1)))
.reduceByKey((a, b) => (a._1 + b._1, a._2 + b._2))
.map(x => (x._1, 1.0 * x._2._1 / x._2._2))
println(score.collect().toList)
}
// TODO 关闭连接
sc.stop();
}
}
7、求好片(评分>=4.0)最多的那个年份的最好看的 10 部电影(好看定义为平均评分最高)
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_07 {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
// 用户id 性别
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//电影id 评分
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
.map(x => (x(1),x(2).toDouble))
//电影id 电影名
val movies = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\movies.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//(电影id,(电影名,评分)) => 过滤大于大于4评分电影 => (电影id,1) => 计算数量 => 取评分数量最多的电影的id
val top1_moveId = movies.join(ratings.filter(x => x._2 >= 4))
.map(x => (x._1, 1))
.reduceByKey(_ + _)
.takeOrdered(10)(Ordering[Int].reverse.on(x => x._2))(0)._1
//id为top1_moveId 的电影名
val top1_moveName = movies.filter(x => x._1 == top1_moveId).collect()(0)._2
//取电影播放年份
val year = top1_moveName.substring(top1_moveName.length - 5, top1_moveName.length - 1)
//过滤年份 => 合并(电影id,(评分,电影名)) => (电影名,(评分,1))=>求和(电影名,(sum评分,sum)) => 求平均 => 取平均最高的10个
val score = ratings.join(movies.filter(x => x._2.contains(year)))
.map(x => (x._2._2, (x._2._1, 1)))
.reduceByKey((a, b) => (a._1 + b._1, a._2 + b._2))
.map(x => (x._1, x._2._1 / x._2._2))
.takeOrdered(10)(Ordering[Double].reverse.on(x => x._2))
for (elem <- score) {println(elem)}
// TODO 关闭连接
sc.stop();
}
}
8、求 1997 年上映的电影中,评分最高的 10 部 Comedy 类电影
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_08 {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
// 用户id 性别
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//电影id 评分
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
.map(x => (x(1),x(2).toDouble))
//电影id 电影名
//过滤类型 and 年份
val movies = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\movies.dat")
.map(x => x.split("::"))
.filter(x => x(2).contains("Comedy") && x(1).contains("1997"))
.map(x => (x(0),x(1)))
//合并(电影id,(评分,电影名)) => (电影名,(评分,1))=>求和(电影名,(sum评分,sum)) => 求平均 => 取平均最高的10个
val score = ratings.join(movies)
.map(x => (x._2._2, (x._2._1, 1)))
.reduceByKey((a, b) => (a._1 + b._1, a._2 + b._2))
.map(x => (x._1, x._2._1 / x._2._2))
.takeOrdered(10)(Ordering[Double].reverse.on(x => x._2))
for (elem <- score) {println(elem)}
// TODO 关闭连接
sc.stop();
}
}
9、该影评库中各种类型电影中评价最高的 5 部电影(类型,电影名,平均影评分)
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_09 {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
// 用户id 性别
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//电影id 评分
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
.map(x => (x(1),x(2).toDouble))
//电影id 电影名
val movies = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\movies.dat")
.map(x => x.split("::"))
//取得所有电影的类型
val moveType = movies.map(x => x(2)).flatMap(x => x.split('|')).distinct().collect()
for (elem <- moveType) {
//对于每种类型,获取评价最高的
//(电影id,(电影名,评分)) => (电影名,(评分,1)) => 求和,求平均 => 取最高的5个
val top5_movie = movies.filter(x => x(2).contains(elem))
.map(x => (x(0), x(1))).join(ratings)
.map(x => (x._2._1, (x._2._2, 1)))
.reduceByKey((a, b) => (a._1 + b._1, a._2 + b._2))
.map(x => (x._1, x._2._1 / x._2._2))
.takeOrdered(5)((Ordering[Double].reverse.on(x => x._2)))
println(elem + ":")
for (movie <- top5_movie) {println(movie)}
}
// TODO 关闭连接
sc.stop();
}
}
10、各年评分最高的电影类型(年份,类型,影评分)
package com.spark.homework.movie
import org.apache.spark.{SparkConf, SparkContext}
object code_10 {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
// 用户id 性别
val users = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\users.dat")
.map(x => x.split("::"))
.map(x => (x(0),x(1)))
//电影id 评分
val ratings = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\ratings.dat")
.map(x => x.split("::"))
.map(x => (x(1),x(2).toDouble))
//电影id 电影名
val movies = sc.textFile("E:\\BigData\\homework\\Spark作业\\实验八\\movies.dat")
.map(x => x.split("::"))
//取得所有电影上映时间
val years = movies.map(x => x(1)).map(x => x.substring(x.length - 5,x.length - 1)).distinct().collect()
for (elem <- years) {
//对于每年,获取评价最高的
//(电影id,(电影名,评分)) => (电影名,(评分,1)) => 求和,求平均 => 取最高的5个
val top_movie = movies.filter(x => x(1).contains(elem))
.map(x => (x(0), x(2))) //(电影id,类型)
.join(ratings) //(电影id,(类型,评分))
.map(x => (x._2._1, (x._2._2, 1))) //(类型,(评分,1))
.reduceByKey((a, b) => (a._1 + b._1, a._2 + b._2)) //求和
.map(x => (x._1, x._2._1 / x._2._2)) //求平均
.takeOrdered(1)((Ordering[Double].reverse.on(x => x._2))) //取最大
println(elem + ":" + top_movie(0))
}
// TODO 关闭连接
sc.stop();
}
}

















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









