




📝 博客主页:jaxzheng的优快云主页
目录
在医疗领域,数据呈现显著的多模态特性:电子健康记录(EHR)包含文本、影像数据(X光/CT/MRI)、基因组序列、生命体征信号等。由于数据分布不均衡和标注成本高,跨模态知识迁移学习(Cross-Modal Knowledge Transfer Learning, CMKTL)成为解决医疗AI瓶颈的关键技术。

通过共享潜在空间实现不同模态间的语义对齐。典型方法包括:
- 对比学习:最大化正样本相似度,最小化负样本相似度
- 注意力机制:动态建模模态间依赖关系
import torch
import torch.nn as nn
class CrossModalAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.q_proj = nn.Linear(dim, dim)
self.k_proj = nn.Linear(dim, dim)
self.v_proj = nn.Linear(dim, dim)
def forward(self, text_emb, image_emb):
Q = self.q_proj(text_emb)
K = self.k_proj(image_emb)
V = self.v_proj(image_emb)
attn_weights = torch.softmax(Q @ K.transpose(-2,-1) / (dim**0.5), dim=-1)
return attn_weights @ V
利用预训练大模型(如CLIP)作为教师模型,指导医疗领域小模型学习。
# 教师-学生模型定义
teacher_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
student_model = MedicalVisionTransformer(num_classes=1000)
# 蒸馏损失函数
def distillation_loss(student_logits, teacher_logits, temperature=4):
soft_teacher = torch.softmax(teacher_logits / temperature, dim=1)
soft_student = torch.log_softmax(student_logits / temperature, dim=1)
return nn.KLDivLoss()(soft_student, soft_teacher) * (temperature**2)
通过迁移学习实现:
- 使用PubMedBERT预训练医学文本编码器
- 结合ResNet-152提取影像特征
- 跨模态注意力融合
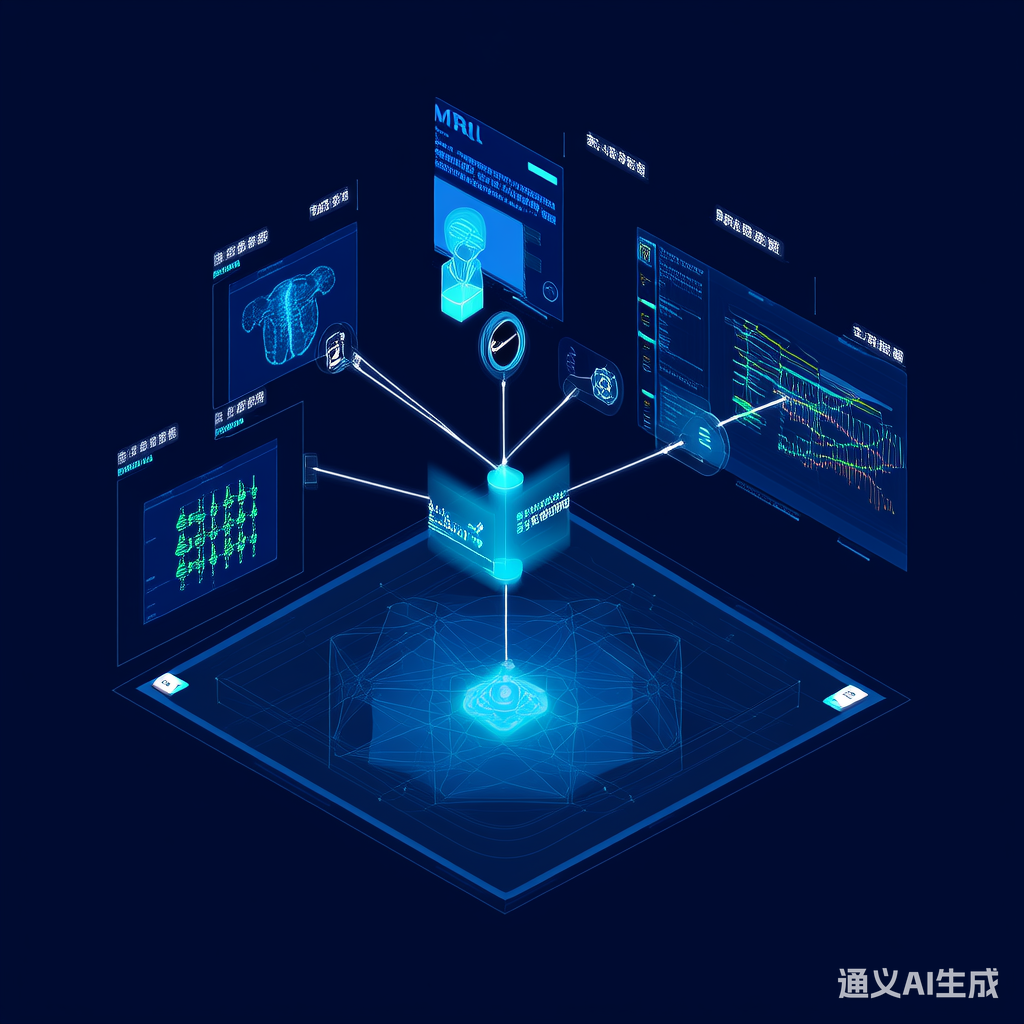
利用自监督学习框架:
# 基因表达特征与MRI特征联合训练
class GeneImageFusion(nn.Module):
def __init__(self):
super().__init__()
self.gene_encoder = TransformerEncoder(input_dim=20000)
self.image_encoder = SwinTransformer()
self.fusion_layer = ConcatFusion()
def forward(self, gene_data, mri_data):
gene_emb = self.gene_encoder(gene_data)
image_emb = self.image_encoder(mri_data)
return self.fusion_layer(gene_emb, image_emb)
| 挑战 | 解决方案 |
|---|---|
| 模态缺失问题 | 动态路由网络 + 退火训练 |
| 领域偏移问题 | 域对抗训练(DANN) |
| 小样本学习 | 元学习 + 压缩感知 |
示例:域适应训练代码片段
# 域分类器
domain_classifier = DomainDiscriminator(hidden_size=512)
# 双重损失函数
total_loss = task_loss + λ * domain_loss
- 联邦学习+跨模态迁移:保护患者隐私下的模型协作
- 物理约束建模:将医学先验知识嵌入神经网络
- 可解释性增强:开发可视化工具解释跨模态决策过程
跨模态知识迁移技术正在重塑医疗AI的开发范式,通过有效整合多源异构数据,显著提升了诊断准确率和模型泛化能力。随着多模态预训练模型的持续演进,医疗领域的AI应用将进入新的发展阶段。

















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









