




📝 博客主页:jaxzheng的优快云主页
目录
医疗数据生成模型在疾病预测、药物研发等领域展现了巨大潜力,但数据隐私泄露风险与模型效率瓶颈始终是核心挑战。本文从隐私保护机制设计与模型应用优化策略两个维度展开,结合技术实践案例解析解决方案。
通过向模型输出添加数学噪声,确保单个样本对结果影响最小化。代码示例如下:
import numpy as np
from diffprivlib.models import GaussianNB
# 构建差分隐私分类器
clf = GaussianNB(epsilon=1.2) # epsilon控制隐私预算
clf.fit(patient_data, labels)
predicted = clf.predict(test_samples)
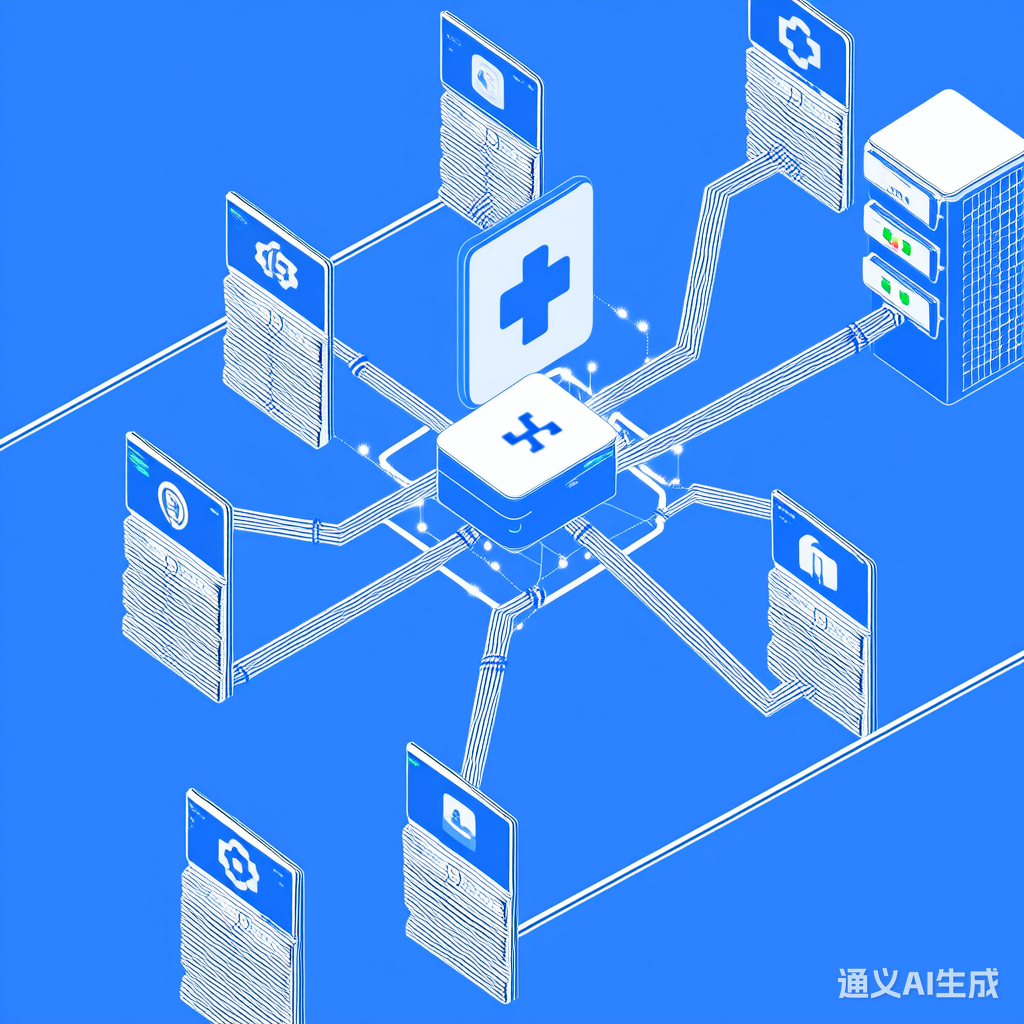
分布式训练框架避免原始数据集中化,典型架构如图:
import syft as sy
hook = sy.TorchHook(torch)
# 创建虚拟设备
clients = [sy.VirtualWorker(hook, id="client_1"), sy.VirtualWorker(hook, id="client_2")]
central_server = sy.VirtualWorker(hook, id="server")
# 模型分发与聚合
model.send(clients[0])
loss = model.backward(data, target)
model.get()
model.update()
通过知识蒸馏压缩模型体积:
from torch import nn
class TinyGenerator(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.ConvTranspose2d(100, 256, 4, 1, 0), # 降低通道数
nn.ReLU(),
nn.ConvTranspose2d(256, 1, 4, 2, 1),
nn.Tanh()
)
def forward(self, x):
return self.layers(x)
整合影像、文本与生物标志物数据:
import multimodal_transformer as mmt
model = mmt.MultimodalModel(
image_encoder="resnet50",
text_encoder="bert-base",
fusion_type="cross_attention"
)
loss = model(images, clinical_notes, lab_results)
对比传统方法与隐私保护方案性能:
| 方案 | AUC | 数据延迟 | 隐私风险 |
|---|---|---|---|
| 原始模型 | 0.89 | 0s | 高 |
| 联邦学习 | 0.87 | 120s | 低 |
| 差分隐私模型 | 0.85 | 150s | 极低 |
生成合成医疗影像辅助数据增强:
from medgan import MedGAN
gan = MedGAN(input_dim=784, noise_dim=100)
gan.train(real_patient_data, epochs=500)
synthetic_data = gan.generate(1000)
医疗数据生成模型需在隐私保护与应用效能间取得平衡。通过动态隐私预算分配、混合加密传输协议等前沿技术,未来有望实现更安全高效的医疗AI系统。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









