



RLHF(Reinforcement Learning from Human Feedback)是一种结合了强化学习(Reinforcement Learning, RL)和人类反馈的机器学习方法。这种方法特别适用于那些难以通过传统监督学习方法获得高质量标签数据的情况。
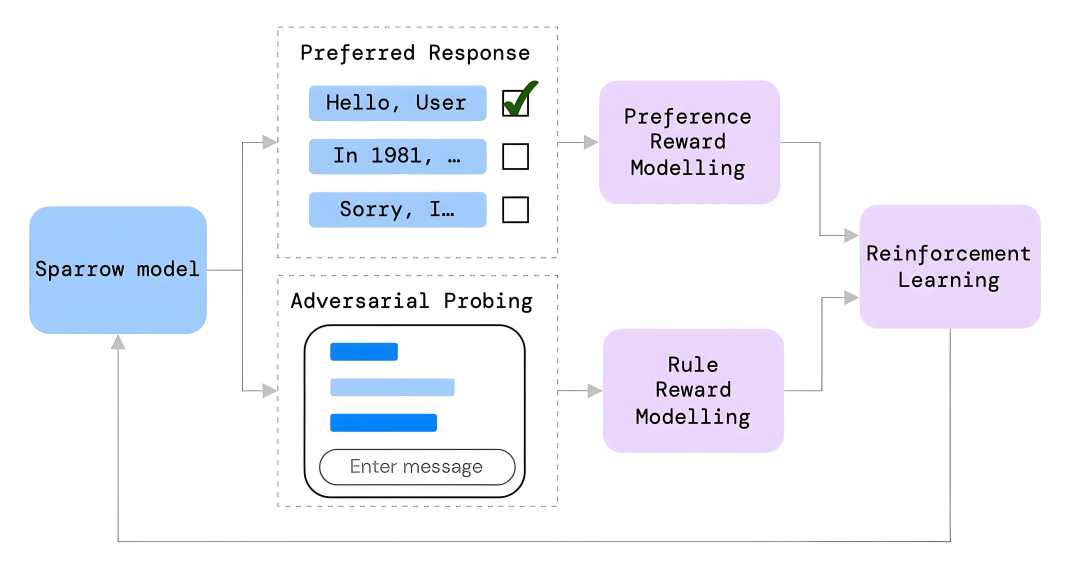
也可以说,人类偏好的强化学习(Reinforcement Learning from Human Feedback,简称RLHF)是近年来大模型发展的关键技术。
它解决了一个核心问题:如何让AI生成的内容不仅仅准确,更要符合人类的期望和价值观。 RLHF的概念并不新鲜。早在2017年,DeepMind和OpenAI的研究人员就探索了这一方向。
但直到2022年,当OpenAI在ChatGPT中大规模应用RLHF后,这项技术才真正进入大众视野。它在一夜之间改变了AI产品的交互体验,从生硬的**“机器回答”**变成了接近人类的对话体验。
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
RLHF在理论和实践中都有着重要的应用。
一、理论
1、强化学习(RL)基础
RLHF建立在强化学习的基础之上,RL是一种让机器学习代理(Agent)通过与环境互动来学习最佳行为的方法。在这个过程中,代理根据其所采取的行动获得奖励或惩罚。
2、人类反馈
在许多情况下,直接为复杂任务定义一个明确、全面的奖励函数是困难的。这时,RLHF通过引入人类反馈来辅助定义奖励函数或直接作为奖励信号。这种反馈可以是标注好的示例、行为评分或对代理输出的直接校正。
3、结合人类反馈的训练过程
在RLHF中,训练过程通常涉及以下几个步骤:
**初始阶段:**使用监督学习的方法,根据人类提供的初始数据集训练代理。
**在线学习:**代理在实际环境中执行任务,同时收集人类反馈。
**奖励建模:**使用收集到的反馈数据来优化或调整奖励函数。
二、实践
1、数据收集
在实际操作中,首先需要收集人类反馈。这可以通过不同方式进行,如让人类观察代理的行为并打分,或者直接对错误的行为进行更正。
2、奖励建模与优化
使用收集到的数据来建立或优化奖励模型。这可能涉及到机器学习或深度学习技术,用以从人类反馈中提取有效信息并将其转化为可以量化的奖励信号。
3、循环迭代
RLHF是一个迭代过程。代理根据当前的奖励模型进行学习和行动,然后根据新的人类反馈来更新奖励模型。这个过程不断重复,以逐渐提升代理的性能。
4、应用范围
RLHF在多个领域都有应用,例如自然语言处理、游戏、机器人控制等。特别是在那些对于模型行为的品质和道德标准有高要求的应用中,RLHF能够帮助确保模型行为的适当性和安全性。
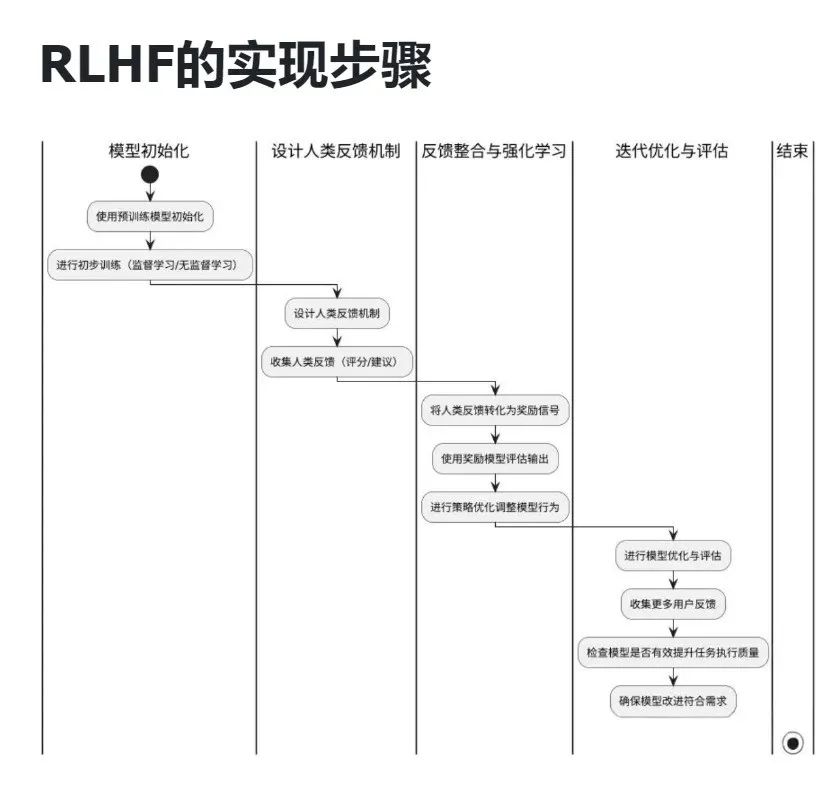
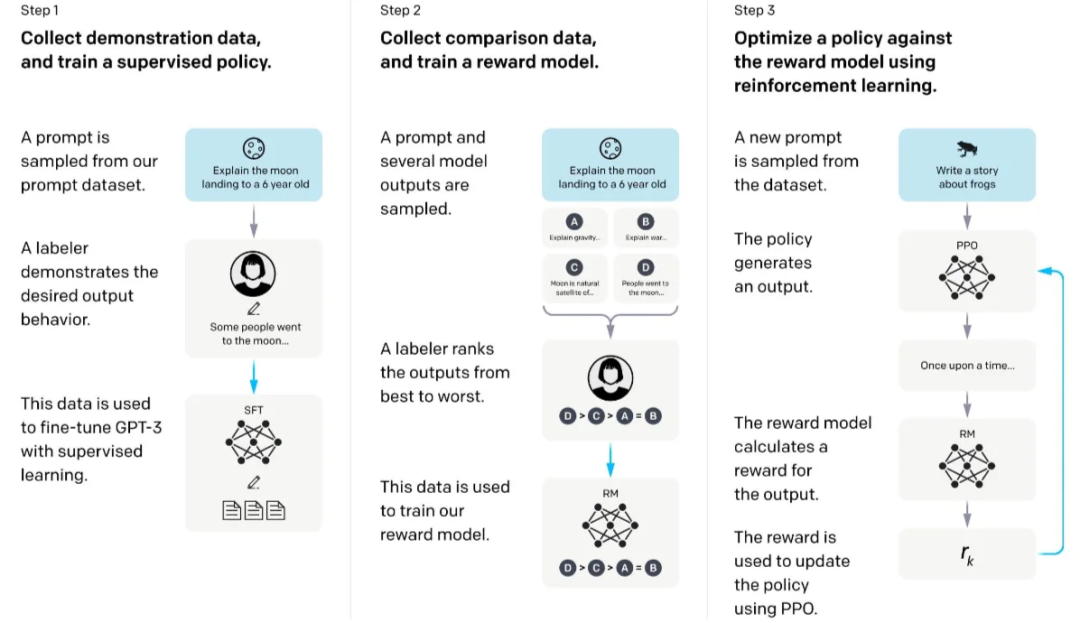
RLHF是一个三步走的过程:
第一步:监督微调(SFT)。
这相当于给AI一些示范,告诉它"这样回答是好的"。工程师们会收集高质量的问答对,让模型通过模仿学习基本的回答方式。
第二步:建立奖励模型(RM)。
这一步要训练一个能"评分"的模型。人类标注者会对同一问题的不同回答进行比较和排序,然后用这些数据训练一个能预测"人类会更喜欢哪个回答"的模型。
第三步:强化学习(RL)。
最后,利用第二步训练的奖励模型作为指导,对语言模型进行优化。每当模型生成一个回答,奖励模型就会给出评分,模型根据这个信号不断调整自己的策略,逐渐生成更符合人类偏好的内容。
这个过程之所以革命性,在于它解决了传统监督学习的局限。在复杂任务中,"正确答案"往往并不唯一,人类偏好也很难用固定规则表达。
RLHF允许模型从人类反馈中持续学习,捕捉那些难以明确定义但人类能直观感受的品质。 从技术层面看,RLHF面临着一些挑战。比如人类反馈的一致性问题——不同人对同一回答的评价可能截然不同。
 再如奖励黑客(reward hacking)问题——模型可能会学到取悦评分系统而非真正满足人类需求的技巧。这些挑战也推动了Constitutional AI等新方法的发展。
再如奖励黑客(reward hacking)问题——模型可能会学到取悦评分系统而非真正满足人类需求的技巧。这些挑战也推动了Constitutional AI等新方法的发展。
有意思的是,虽然RLHF让AI变得更"听话",但它也带来了一个哲学问题:我们真正想要的是什么样的AI?是完全遵循我们指令的工具,还是有独立思考能力的助手?
在某些情况下,过度优化的AI可能会过于迎合用户,甚至无法指出用户的错误。 随着技术发展,RLHF也在不断演化。
从简单的"喜欢/不喜欢"二元反馈,到更细粒度的多维度评价;从中心化的标注团队,到更广泛的用户参与。每一步演进都在塑造着AI与人类互动的未来。

同时,RLHF(人类反馈强化学习)的训练方式,也造就了Ai的讨好性人格, 反映了人性中我们难以直面自己弱点的懦弱本性。
当Ai一直在道歉, 为了不伤害我们的感情甚至在一本正经胡说八道的时候, 也埋下了一个个温柔的陷阱。
人夸赞我, 我们要能从对社会奖赏的迷恋中抽离出来,人批判我,我们也要能从社会排斥的愤怒和沮丧中抽离出去。
当我们提高了抑制本能反应的能力并且能从一个超越当下自我的角度去思考自我以及和他人以及世界的关系,在某种意义上我们更像是一个人而不是一个AI,至少不是2025年的AI。 这再次强调了类脑计算的重要性以及对人性的神经表征的理解的必要性。
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









