




 本文详细介绍了Apache Flink中的数据分区策略,包括随机分区、轮询分区、重缩放分区、广播、全局分区以及自定义分区。这些策略影响数据在并行任务间的分布,从而影响处理效率和结果。例如,随机分区实现数据均匀分布,轮询分区确保负载均衡,重缩放分区则在局部进行数据调整,广播分区将数据复制到所有任务,全局分区将所有数据发送至同一任务,自定义分区允许用户根据需求定制策略。
本文详细介绍了Apache Flink中的数据分区策略,包括随机分区、轮询分区、重缩放分区、广播、全局分区以及自定义分区。这些策略影响数据在并行任务间的分布,从而影响处理效率和结果。例如,随机分区实现数据均匀分布,轮询分区确保负载均衡,重缩放分区则在局部进行数据调整,广播分区将数据复制到所有任务,全局分区将所有数据发送至同一任务,自定义分区允许用户根据需求定制策略。
前言
flink中keyBy是一种按照键的哈希值来进行重新分区的操作,至于分区是否均匀、每个key 的数据具体会分到哪一区无法控制,因此keyBy 是一种逻辑分区(logical partitioning)操作。只有物理分区(physical partitioning),才真正控制分区策略精准地调配数据。
物理分区与 keyBy 另一大区别在于,keyBy 之后得到的是一个 KeyedStream,而物理分区之后结果仍是 DataStream,且流中元素数据类型保持不变。分区算子并不对数据进行转换处理,只是定义了数据的传输方式
flink控制分区策略的顶层接口为ChannelSelector,其实现类实现selectChannel()方法决定数据的流向
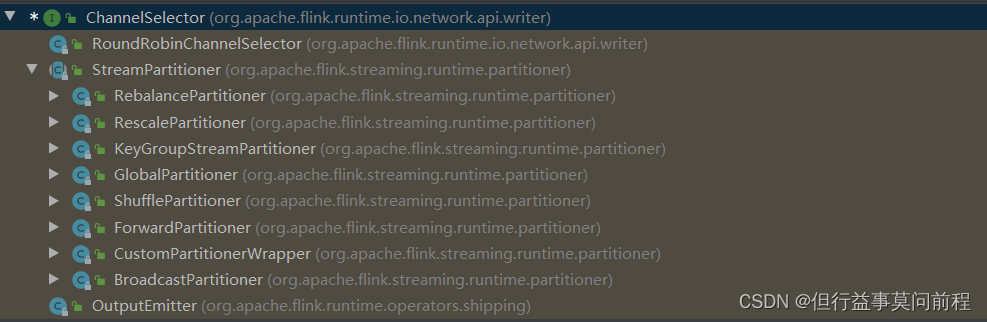
如:keyby算子采用的分区器KeyGroupStreamPartitioner,其核心逻辑如下
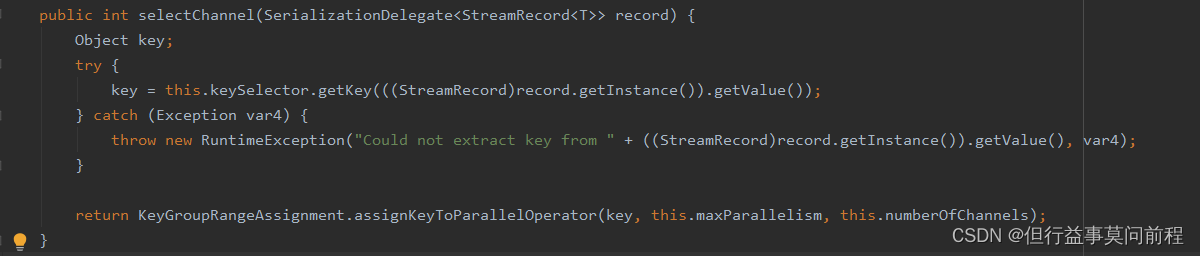
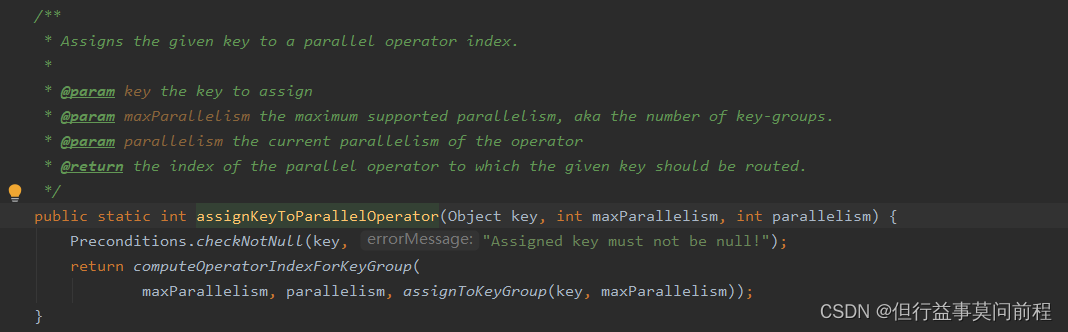
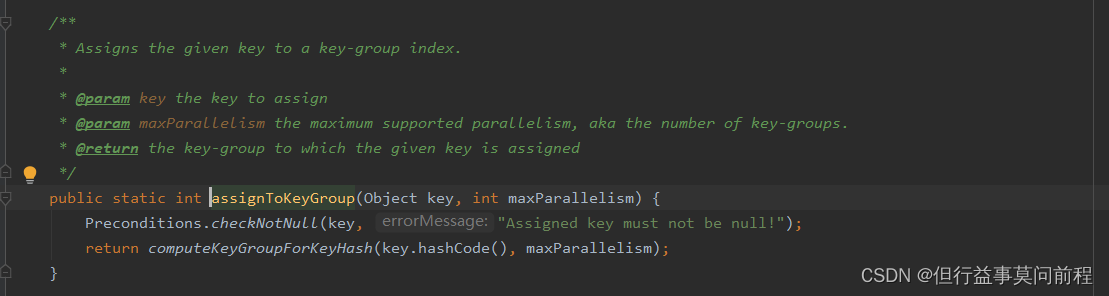
对传入的record的key进行取hashCode
1. 随机分区
Partitions elements randomly according to a uniform distribution
通过调用 dataStream 的shuffle()方法,将数据随机地分配到下游算子的并行任务中,因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
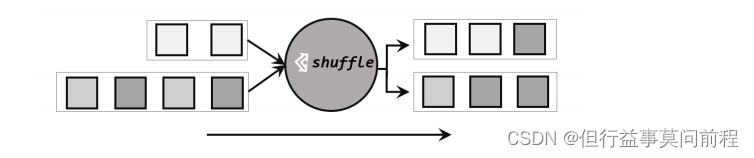
dataStream.shuffle();
底层采用分区器为:ShufflePartitioner,核心处理逻辑为:

2. 轮询分区
按照先后顺序将数据做依次分发。通过调用dataStream 的rebalance()方法,就可以实现轮询重分区。rebalance使用的是 Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去
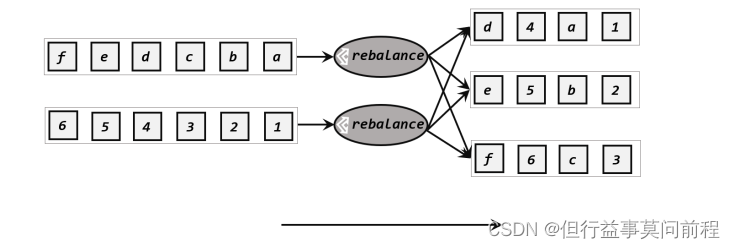
dataStream.rebalance( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











