




 本文介绍了Apache Flink的类型系统,包括基本类型、数组、复合类型、辅助类型和泛型类型。重点讲解了Flink如何处理POJO类型,并展示了类型提示(TypeHints)在解决Java泛型擦除问题上的作用。此外,还详细阐述了从Kafka读取自定义类型数据流时,如何自定义DeserializationSchema进行反序列化操作。
本文介绍了Apache Flink的类型系统,包括基本类型、数组、复合类型、辅助类型和泛型类型。重点讲解了Flink如何处理POJO类型,并展示了类型提示(TypeHints)在解决Java泛型擦除问题上的作用。此外,还详细阐述了从Kafka读取自定义类型数据流时,如何自定义DeserializationSchema进行反序列化操作。
1. Flink 的类型系统
Flink 作为一个分布式处理框架,处理的是以数据对象作为元素的流。要分布式地处理这些数据,就不可避免地要面对数据的网络传输、状态的落盘和故障恢复等问题,这就需要对数据进行序列化和反序列化。
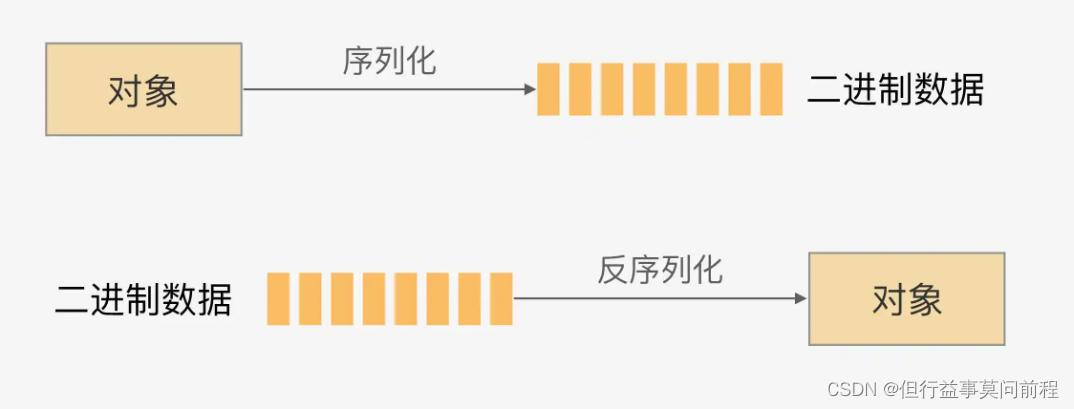
Flink 有自己一整套类型系统。Flink 使用“类型信息”(TypeInformation)来统一表示数据类型。TypeInformation 类是 Flink 中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器
2. Flink 支持的数据类型
Basic types: All Java primitives and their boxed form, plus void, String, Date, BigDecimal, and BigInteger.
Primitive arrays and Object arrays
Composite types:
------Flink Java Tuples (part of the Flink Java API): max 25 fields, null fields not supported
------Scala case classes (including Scala tuples): null fields not supported
------Row: tuples with arbitrary number of fields and support for null fields
------POJOs: classes that follow a certain bean-like pattern
Auxiliary types (Option, Either, Lists, Maps, …)
Generic types: These will not be serialized by Flink itself, but by Kryo.
(1)基本类型
所有 Java 基本类型及其包装类,再加上 Void、String、Date、BigDecimal 和 BigInteger
(2)数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)
(3)复合数据类型
Java 元组类型(TUPLE):这是 Flink 内置的元组类型,是 Java API 的一部分。最多25 个字段,也就是从 Tuple0~Tuple25,不支持空字段
Scala 样例类及 Scala 元组:不支持空字段
行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段
POJO:Flink 自定义的类似于 Java bean 模式的类
(4)辅助类型
Option、Either、List、Map 等
(5)泛型类型(GENERIC)
Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照POJO 类型的要求来定义,就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。Flink 对 POJO 类型的要求如下:
类是公共的(public)和独立的(没有非静态的内部类);
类有一个公共的无参构造方法;
类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些方法需要符合 Java bean 的命名规范
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











