




点击:【第一章:Java开发岗:基础篇】
计算机基础问题、HashMap、Fail-safe机制/Fail-fast机制、Synchronized、ThreadLocal、AQS、线程池、JVM内存模型、内存屏障、class文件结构、类加载 机制、双亲委派、垃圾回收算法、垃圾回收器、空间分配担保策略、安全点、JIT技术、可达性分析、强软弱虚引用、gc的过程、三色标记、跨代引用、 逃逸分析、 内存泄漏与溢出、JVM线上调优、CPU飙高系统反应慢怎么排查。
点击:【第二章:Java开发岗:MySQL篇】
隔离级别、ACID底层实现原理、 一致性非锁定读(MVCC的原理)、BufferPool缓存机制、filesort过程、 离散读、ICP优化、全文检索、 行锁、表锁、间隙锁、死锁、主键自增长实现原理、索引数据结构、SQL优化、索引失效的几种情况、聚集索引、辅助索引、覆盖索引、联合索引、redo log、bin log、undolog、分布式事务、SQL的执行流程、重做日志刷盘策略、有MySQL调优、分库分表、主从复制、读写分离、高可用。
点击:【第三章:Java开发岗:Redis篇】
多路复用模式、单线程模型、简单字符串、链表、字典、跳跃表、压缩列表、encoding属性编码、持久化、布隆过滤器、分布式寻址算法、过期策略、内存淘汰策略 、Redis与数据库的数据一致性、Redis分布式锁、热点数据缓存、哨兵模式、集群模式、多级缓存架构、并发竞争、主从架构、集群架构及高可用、缓存雪崩、 缓存穿透、缓存失效。
点击:【第四章:Java开发岗:MQ篇】
RabbitMQ、RockerMQ、Kafka 三种消息中间件出现的消息可靠投递、消息丢失、消息顺序性、消息延迟、过期失效、消息队列满了、消息高可用等问题的解决方案。RabbitMQ的工作模式,RocketMQ的消息类型,Kafka消费模式、主题/分区/日志、核心总控制器以及它的选举机制、Partition副本选举Leader机制、消费者消费消息的offset记录机制、消费者Rebalance机制、Rebalance分区分配策略、Rebalance过程、 producer发布消息机制、HW与LEO、日志分段存储、十亿消息数据线上环境规划、JVM参数设置。
点击:【第五章:Java开发岗:Spring篇】
SpringBean生命周期、Spring循环依赖、Spring容器启动执行流程、Spring事务底层实现原理、Spring IOC容器加载过程、Spring AOP底层实现原理、Spring的自动装配、Spring Boot自动装配、Spring Boot启动过程、SpringMVC执行流程、Mybatis的缓存机制。
微服务构建、客户端负载均衡、服务治理、服务容错保护、声明式服务调用、API网关服务、分布式配置中心、消息总线、消息驱动、分布式服务追踪、分布式事务、流量控制。
点击:【第七章:Java开发岗:项目篇】
简历上面的项目经历怎么写(项目介绍、负责模块、使用技术),面试项目实战(秒杀下单设计、权限设计、红包雨设计)
系列文章:每篇文章字数都是大几万,保证质量,文章以备战面试为背景,薪资参考坐标:上海;每个地方,每个时间段薪资待遇都不一样,文章仅做面试参考,具体能否谈到理想的薪资取决于面试表现、平时的积累、市场行情、机遇。
提示:系列文章还未全部完成,后续的文章,会慢慢补充进去的。
文章目录
这里总结一下35k的Java开发岗需要掌握的面试题,帮助大家快速复习,突破面试瓶颈。本章主讲Spring、SpringMVC、SpringBoot知识点,知识点有:SpringBean生命周期、Spring循环依赖、Spring容器启动执行流程、Spring事务底层实现原理、Spring IOC容器加载过程、Spring AOP底层实现原理、Spring的自动装配、Spring Boot自动装配、Spring Boot启动过程、SpringMVC执行流程、Mybatis的缓存机制。大致估算可以讲三小时左右,作为备战面试的Spring相关知识点还是很不错的。35k薪资参考的坐标:上海,参考时间:2022年8月。
Spring Bean的生命周期
 Spring Bean的生命周期管理的基本思路是:在Bean出现之前,先准备操作Bean的BeanFactory,然后操作完Bean,所有的Bean也还会交给BeanFactory进行管理。在所有Bean操作准备BeanPostProcessor作为回调。
Spring Bean的生命周期管理的基本思路是:在Bean出现之前,先准备操作Bean的BeanFactory,然后操作完Bean,所有的Bean也还会交给BeanFactory进行管理。在所有Bean操作准备BeanPostProcessor作为回调。
Bean创建前的准备阶段
步骤1: Bean容器在配置文件中找到Spring Bean的定义以及相关的配置,如init-method和destroy-method指定的方法。
步骤2: 实例化回调相关的后置处理器如BeanFactoryPostProcessor、BeanPostProcessor、InstantiationAwareBeanPostProcessor等
创建Bean的实例
步骤3: Srping 容器使用Java反射API创建Bean的实例。
步骤4:扫描Bean声明的属性并解析。
开始依赖注入
步骤5:开始依赖注入,解析所有需要赋值的属性并赋值。
步骤6:如果Bean类实现BeanNameAware接口,则将通过传递Bean的名称来调用setBeanName()方法。
步骤7:如果Bean类实现BeanFactoryAware接口,则将通过传递BeanFactory对象的实例来调用setBeanFactory()方法。
步骤8:如果有任何与BeanFactory关联的BeanPostProcessors对象已加载Bean,则将在设置Bean属性之前调用postProcessBeforeInitialization()方法。
步骤9:如果Bean类实现了InitializingBean接口,则在设置了配置文件中定义的所有Bean属性后,将调用afterPropertiesSet()方法。
缓存到Spring容器
步骤10: 如果配置文件中的Bean定义包含init-method属性,则该属性的值将解析为Bean类中的方法名称,并将调用该方法。
步骤11:如果为Bean Factory对象附加了任何Bean 后置处理器,则将调用postProcessAfterInitialization()方法。
销毁Bean的实例
步骤12:如果Bean类实现DisposableBean接口,则当Application不再需要Bean引用时,将调用destroy()方法。
步骤13:如果配置文件中的Bean定义包含destroy-method属性,那么将调用Bean类中的相应方法定义。
 在一个Bean实例被初始化时,需要执行一系列初始化操作以使其达到可用的状态。同样,当一个Bean不再被调用时需要进行相关的析构操作,并从Bean容器中移除。
在一个Bean实例被初始化时,需要执行一系列初始化操作以使其达到可用的状态。同样,当一个Bean不再被调用时需要进行相关的析构操作,并从Bean容器中移除。
Spring Bean Factory 负责管理在Spring容器中被创建的Bean的生命周期。Bean的生命周期由两组回调方法组成。
(1)初始化之后调用的回调方法。
(2)销毁之前调用的回调方法。
Spring提供了以下4种方式来管理Bean的生命周期事件:
(1)InitializingBean和DisposableBean回调接口。
(2)针对特殊行为的其他Aware接口。
(3)Bean配置文件中的customInit()方法和customDestroy()方法。
(4)@PostConstruct和@PreDestroy注解方式。
使用customInit()和 customDestroy()方法管理Bean生命周期
想进一步了解代码实现的,这里分享一个地址:点击【java_wxid】进行查看。
Spring循环依赖
什么是循环依赖?

BeanA类依赖了BeanB类,BeanB类依赖了BeanC类,BeanC类依赖了BeanA类,形成了一个依赖闭环,我们把这种依赖关系就称之为循环依赖。
循环依赖会导致什么问题的出现?

 启动项目,我们发现只要是有循环依赖关系的属性并没有自动赋值,而没有循环依赖关系的属性均有自动赋值,如下图所示:
启动项目,我们发现只要是有循环依赖关系的属性并没有自动赋值,而没有循环依赖关系的属性均有自动赋值,如下图所示:

IoC容器对Bean的初始化是根据BeanDefinition循环迭代,有一定的顺序。这样,在执行依赖注入时,需要自动赋值的属性对应的对象有可能还没初始化,没有初始化也就没有对应的实例可以注入。
Spring是怎么解决循环依赖导致的问题的?
Spring使用三级缓存解决循环依赖的过程
- 一级缓存存放实例化对象 。
- 二级缓存存放已经在内存空间创建好但是还没有给属性赋值的对象。
- 三级缓存存放对象工厂,用来创建提前暴露到bean的对象。
代码举例:
@Service
public class TestService1 {
@Autowired
private TestService2 testService2;
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}

testService1先去一级缓存看有没有实例,发现没有,继续去二级缓存查看,发现没有,去三级缓存查看,发现没有实例就创建实例,在创建的过程中,提前暴露,添加到三级缓存里。
这个时候进行属性赋值,发现还有一个testService2,它没有赋值,是一个空的,就从一级缓存中去看testSerivce2有没有实例,发现没有,去二级查看发现没有,去三级缓存查看,发现没有,就创建实例,也提前暴露,添加到三级缓存里面。
这个时候testSerivce2对象里面发现testService1里面没有赋值,然后对testService1进行赋值,从一级缓存去查看,发现没有,去二级查看,发现没有,去三级查看,发现有,就把实例testService1从三级缓存添加到二级缓存里面,把实例testService1三级缓存的实例删除,这个时候,testService2里面有实例对象,对象里面的testService1也有值了,就是一个可以使用的实例对象了,就把这个对象移动到一级缓存里面,把三级缓存里面的testService2删除。
这个时候testService1里面的testService2属性就可以从一级缓存里面获取这个testService2实例了,把它进行赋值填充,testService1也完成了实例化,把testService1从二级缓存移动到一级缓存里面,把testService1在二级缓存的实例也删除。

想进一步了解代码实现的,这里分享一个地址:点击【java_wxid】进行查看。
Spring容器启动执行流程
部署一个web应用在web容器中,它会提供一个全局的上下文环境,这个上下文就是ServletContext,它为后面的IoC容器提供宿主环境,当web容器启动的时候,会执行web.xml中的ContextLoaderListener监听器初始化contextInitialized方法,调用父类的initWebApplicationContext方法。
这个方法里面执行了三个任务:
1.创建WebApplicationContext容器
2.加载context-param中spring配置文件
3.初始化配置文件并且创建配置文件中的bean。
监听器初始化完毕后,开始初始化web.xml中配置的servlet ,用DispatcherServlet举例,它是一个前端控制器,用来转发、匹配、处理每个servlet 请求。
DispatcherServlet上下文在初始化的时候会建立自己的上下文,先从ServletContext 中获取之前的WebApplicationContext作为自己上下文的父类上下文,有了这个父类上下文之后,再初始化自己持有的上下文,创建springmvc相关的bean,初始化处理器映射、视图解析等等,初始化完后,spring把Servlet的相关的属性作为属性key,存到servletcontext中,方便后面使用。这样每个Servlet 都持有自己的上下文,拥有自己独立的bean 空间,各个servlet 共享相同的bean,也就是根上下文定义的那些bean。
web容器停止时候会执行ContextLoaderListener的contextDestroyed方法销毁context容器。
Spring事务底层实现原理
当在某个类或者方法上使用@Transactional注解后,spring会基于该类生成一个代理对象,并将这个代理对象作为bean。当调用这个代理对象的方法时,如果有事务处理,则会先关闭事务的自动功能,然后执行方法的具体业务逻辑,如果业务逻辑没有异常,那么代理逻辑就会直接提交,如果出现任何异常,那么直接进行回滚操作。当然我们也可以控制对哪些异常进行回滚操作。
一个Bean在执行Bean的创建生命周期时,会经过InfrastructureAdvisorAutoProxyCreator的初始化后的方法,会判断当前当前Bean对象是否和BeanFactoryTransactionAttributeSourceAdvisor匹配,匹配逻辑为判断该Bean的类上是否存在@Transactional注解,或者类中的某个方法上是否存在@Transactional注解,如果存在则表示该Bean需要进行动态代理产生一个代理对象作为Bean对象。
源码执行流程:
- 加了@Transactional注解的类,或者类中拥有@Transactional注解的方法,都会生成代理对象作为bean。
代理对象执行方法时。 - 获取当前正在执行的方法上的@Transactional注解的信息TransactionAttribute。
- 查看@Transactional注解上是否指定了TransactionManager,如果没有指定,则默认获取TransactionManager类型的bean作为TransactionManager。对于TransactionManager有一个限制,必须是PlatformTransactionManager。
- 生成一个joinpointIdentification,作为事务的名字。
- 开始创建事务。
- 创建事务成功后执行业务方法。
- 如果执行业务方法出现异常,则会进行回滚,然后执行完finally中的方法后再将异常抛出。
- 如果执行业务方法没有出现异常,那么则会执行完finally中的方法后再进行提交。
Spring IOC容器加载过程
spring ioc容器的加载,大体上经过以下几个过程:
资源文件定位、解析、注册、实例化
资源文件定位
资源文件定位,一般是在ApplicationContext的实现类里完成的,因为ApplicationContext接口继承ResourcePatternResolver 接口,ResourcePatternResolver接口继承ResourceLoader接口,ResourceLoader其中的getResource()方法,可以将外部的资源,读取为Resource类。
解析DefaultBeanDefinitionDocumentReader
解析主要是在BeanDefinitionReader中完成的,最常用的实现类是XmlBeanDefinitionReader,其中的loadBeanDefinitions()方法,负责读取Resource,并完成后续的步骤。ApplicationContext完成资源文件定位之后,是将解析工作委托给XmlBeanDefinitionReader来完成的
解析这里涉及到很多步骤,最常见的情况,资源文件来自一个XML配置文件。首先是BeanDefinitionReader,将XML文件读取成w3c的Document文档。
DefaultBeanDefinitionDocumentReader对Document进行进一步解析。然后DefaultBeanDefinitionDocumentReader又委托给BeanDefinitionParserDelegate进行解析。如果是标准的xml namespace元素,会在Delegate内部完成解析,如果是非标准的xml namespace元素,则会委托合适的NamespaceHandler进行解析最终解析的结果都封装为BeanDefinitionHolder,至此解析就算完成。
后续会进行细致讲解。
注册
然后bean的注册是在BeanFactory里完成的,BeanFactory接口最常见的一个实现类是DefaultListableBeanFactory,它实现了BeanDefinitionRegistry接口,所以其中的registerBeanDefinition()方法,可以对BeanDefinition进行注册这里附带一提,最常见的XmlWebApplicationContext不是自己持有BeanDefinition的,它继承自AbstractRefreshableApplicationContext,其持有一个DefaultListableBeanFactory的字段,就是用它来保存BeanDefinition。
所谓的注册,其实就是将BeanDefinition的name和实例,保存到一个Map中。刚才说到,最常用的实现DefaultListableBeanFactory,其中的字段就是beanDefinitionMap,是一个ConcurrentHashMap。
实例化
注册也完成之后,在BeanFactory的getBean()方法之中,会完成初始化,也就是依赖注入的过程。
想进一步了解代码实现的,这里分享一个地址:点击【java_wxid】进行查看。
SpringAOP实现原理
Spring的AOP的应用场景一般在日志记录、权限验证、事务管理等业务场景。
它是运行期进行织入,生成字节码,再加载到虚拟机中,JDK是利用反射原理,CGLIB使用了ASM原理。
初始化时会看目标类有没有实现InvocationHandler接口或者是Proxy类。
如果实现了接口,就使用JDK动态代理,通过反射来接收被代理的类。
如果没实现就利用cglib进行AOP动态代理,CGLIB是通过继承的方式做的动态代理,是一个代码生成的类库,可以在运行时动态的生成某个类的子类,将目标对象转变为代理对象对事务进行操作。
所以在初始化的时候,已经将目标对象进行代理,放入到spring 容器中。
想进一步了解代码实现的,这里分享一个地址:点击【java_wxid】进行查看。
Spring的自动装配
使用@Autowired注解自动装配指定的bean,在启动spring IoC时,容器自动加载了一个AutowiredAnnotationBeanPostProcessor后置处理器,当容器扫描到@Autowied的时候,就会在IoC容器自动查找需要的bean,并且注入对象的属性,使用@Autowired的时候,首先在容器中查询对应类型的bean,如果查询结果刚好为一个,就将这个bean装配给@Autowired指定的数据,如果查询的结果不止一个,那么@Autowired会根据名称来查找,如果上述查找的结果为空,那么会抛出异常,解决方法可以使用required=false。如果使用@Resource它默认是按照名称来装配注入的,只有当找不到与名称匹配的bean才会按照类型来装配注入。
在Spring中共有5种自动装配模式:
(1)no:这是Spring的默认设置,在该设置下自动装配是关闭的,开发者需要自行在Bean定义中用标签明确地设置依赖关系。
(2)byName:该模式可以根据Bean名称设置依赖关系。当向一个Bean中自动装配一个属性时,容器将根据Bean的名称自动在配置文件中查询一个匹配的Bean。如果找到就装配这个属性,如果没找到就报错。
(3)byType:该模式可以根据Bean类型设置依赖关系。当向一个Bean中自动装配一个属性时,容器将根据Bean的类型自动在配置文件中查询一个匹配的Bean。如果找到就装配这个属性,如果没找到就报错。
(4)constructor:和byType模式类似,但是仅适用于有与构造器相同参数类型的Bean,如果在容器中没有找到与构造器参数类型一致的Bean,那么将会抛出异常。
(5)autodetect:该模式自动探测使用constructor自动装配或者byType自动装配。首先会尝试找合适的带参数的构造器,如果找到就是用构造器自动装配,如果在Bean内部没有找到相应的构造器或者构造器是无参构造器,容器就会自动选择byType模式。
Spring Boot自动装配
Spring Boot启动的时候会通过@EnableAutoConfiguration注解找到META-INF/spring.factories配置文件中的所有自动配置类,并对其进行加载,而这些自动配置类都是以AutoConfiguration结尾来命名的,它实际上就是一个JavaConfig形式的Spring容器配置类,它能通过以Properties结尾命名的类中取得在全局配置文件中配置的属性如:server.port,而XxxxProperties类是通过@ConfigurationProperties注解与全局配置文件中对应的属性进行绑定的。
启动类的@SpringBootApplication注解由@SpringBootConfiguration,@EnableAutoConfiguration,@ComponentScan三个注解组成,三个注解共同完成自动装配;
- @SpringBootConfiguration 注解标记启动类为配置类
- @ComponentScan 注解实现启动时扫描启动类所在的包以及子包下所有标记为bean的类由IOC容器注册为bean
- @EnableAutoConfiguration通过 @Import 注解导入 AutoConfigurationImportSelector类,然后通过AutoConfigurationImportSelector 类的 selectImports 方法去读取需要被自动装配的组件依赖下的spring.factories文件配置的组件的类全名,并按照一定的规则过滤掉不符合要求的组件的类全名,将剩余读取到的各个组件的类全名集合返回给IOC容器并将这些组件注册为bean
Spring Boot启动过程
一、SpringBoot启动的时候,会构造一个SpringApplication的实例,构造SpringApplication的时候会进行初始化的工作,初始化的时候会做以下几件事:
1、把参数sources设置到SpringApplication属性中,这个sources可以是任何类型的参数.
2、判断是否是web程序,并设置到webEnvironment的boolean属性中.
3、创建并初始化ApplicationInitializer,设置到initializers属性中 。
4、创建并初始化ApplicationListener,设置到listeners属性中 。
5、初始化主类mainApplicatioClass。
二、SpringApplication构造完成之后调用run方法,启动SpringApplication,run方法执行的时候会做以下几件事:
1、构造一个StopWatch计时器,用来记录SpringBoot的启动时间 。
2、初始化监听器,获取SpringApplicationRunListeners并启动监听,用于监听run方法的执行。
3、创建并初始化ApplicationArguments,获取run方法传递的args参数。
4、创建并初始化ConfigurableEnvironment(环境配置)。封装main方法的参数,初始化参数,写入到 Environment中,发布 ApplicationEnvironmentPreparedEvent(环境事件),做一些绑定后返回Environment。
5、打印banner和版本。
6、构造Spring容器(ApplicationContext)上下文。先填充Environment环境和设置的参数,如果application有设置beanNameGenerator(bean)、resourceLoader(加载器)就将其注入到上下文中。调用初始化的切面,发布ApplicationContextInitializedEvent(上下文初始化)事件。
7、SpringApplicationRunListeners发布finish事件。
8、StopWatch计时器停止计时,日志打印总共启动的时间。
9、发布SpringBoot程序已启动事件(started())
10、调用ApplicationRunner和CommandLineRunner
11、最后发布就绪事件ApplicationReadyEvent,标志着SpringBoot可以处理就收的请求了(running())
Spring MVC的工作原理
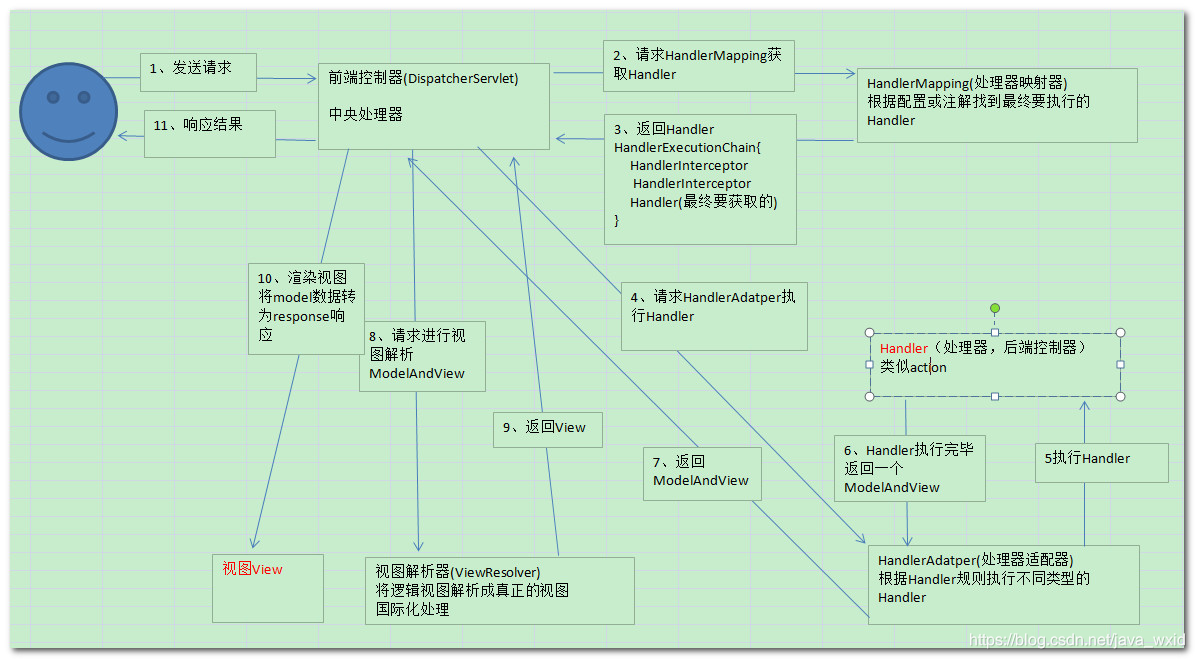
1、用户向服务器发送请求,请求被SpringMVC的前端控制器DispatcherServlet截获。
2、DispatcherServlet对请求的URL(统一资源定位符)进行解析,得到URI(请求资源标识符),然后根据该URI,调用HandlerMapping获得该Handler配置的所有相关的对象,包括Handler对象以及Handler对象对应的拦截器,这些对象都会被封装到一个HandlerExecutionChain对象当中返回。
3、DispatcherServlet根据获得的Handler,选择一个合适的HandlerAdapter。HandlerAdapter的设计符合面向对象中的单一职责原则,代码结构清晰,便于维护,最为重要的是,代码的可复制性高。HandlerAdapter会被用于处理多种Handler,调用Handler实际处理请求的方法。
4、提取请求中的模型数据,开始执行Handler(Controller)。在填充Handler的入参过程中,根据配置,spring将帮助做一些额外的工作消息转换:将请求的消息,如json、xml等数据转换成一个对象,将对象转换为指定的响应信息。数据转换:对请求消息进行数据转换,如String转换成Integer、Double等。 数据格式化:对请求的消息进行数据格式化,如将字符串转换为格式化数字或格式化日期等。数据验证:验证数据的有效性如长度、格式等,验证结果存储到BindingResult或Error中。
5、Handler执行完成后,向DispatcherServlet返回一个ModelAndView对象,ModelAndView对象中应该包含视图名或视图模型。
6、根据返回的ModelAndView对象,选择一个合适的ViewResolver(视图解析器)返回给DispatcherServlet。
7、ViewResolver结合Model和View来渲染视图。
8、将视图渲染结果返回给客户端。
Mybatis的缓存机制
首先,Mybatis里面设计了二级缓存来提升数据的检索效率,避免每次数据的访问都需要去查询数据库。
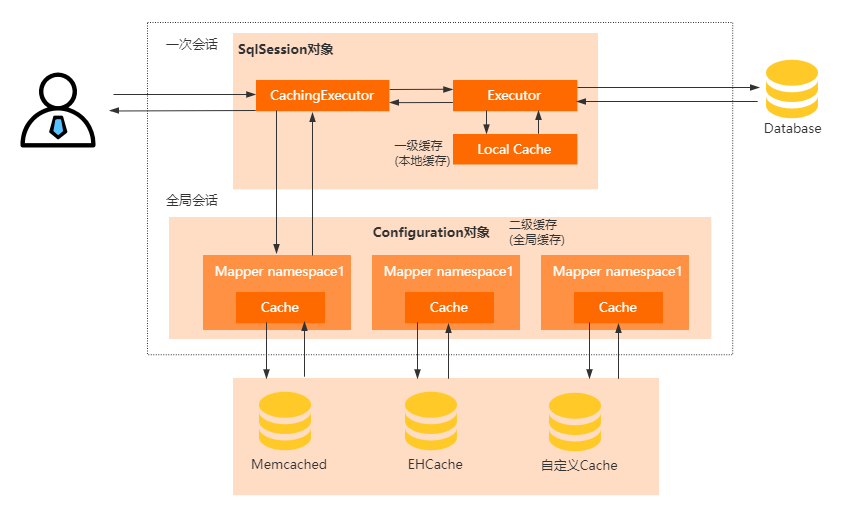
一级缓存,是SqlSession级别的缓存,也叫本地缓存,因为每个用户在执行查询的时候都需要使用SqlSession来执行,
为了避免每次都去查数据库,Mybatis把查询出来的数据保存到SqlSession的本地缓存中,后续的SQL如果命中缓存,就可以直接从本地缓存读取了。
如果想要实现跨SqlSession级别的缓存?那么一级缓存就无法实现了,因此在Mybatis里面引入了二级缓存,就是当多个用户
在查询数据的时候,只有有任何一个SqlSession拿到了数据就会放入到二级缓存里面,其他的SqlSession就可以从二级缓存加载数据。
每个一级缓存的具体实现原理是:
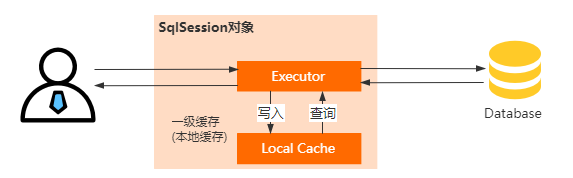
在SqlSession 里面持有一个Executor,每个Executor中有一个LocalCache对象。
当用户发起查询的时候,Mybatis会根据执行语句在Local Cache里面查询,如果没命中,再去查询数据库并写入到LocalCache,否则直接返回。
所以,以及缓存的生命周期是SqlSessiion,而且在多个Sqlsession或者分布式环境下,可能会导致数据库写操作出现脏数据。
二级缓存的具体实现原理是:
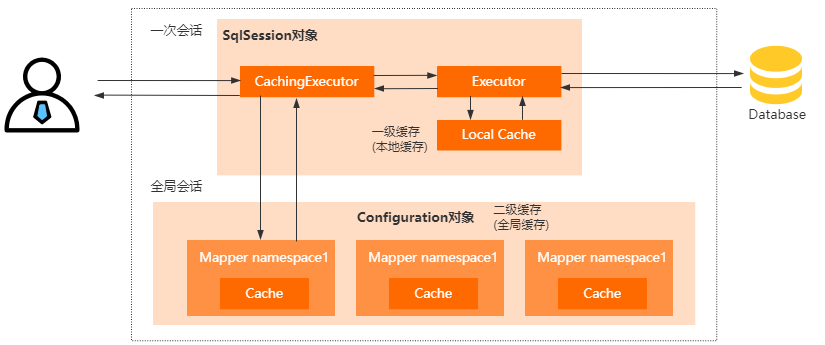
使用CachingExecutor装饰了Executor,所以在进入一级缓存的查询流程之前,会先通过CachingExecutor进行二级缓存的查询。
开启二级缓存以后,会被多个SqlSession共享,所以它是一个全局缓存。因此它的查询流程是先查二级缓存,再查一级缓存,最后再查数据库。
另外,MyBatis 的二级缓存相对于一级缓存来说,实现了 SqlSession 之间缓存数据的共享,同时缓存粒度也能够到 namespace 级别,并且还可以通过 Cache 接口实现类不同的组合,对 Cache 的可控性也更强。


















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











