




 本文探讨了在使用Hibernate处理十万级数据量时遇到的问题,通过关闭二级缓存、分批保存和调整配置,实现了批量保存操作。控制器中将数据分块处理,每批一万条,服务层和DAO层配合完成数据的刷新与持久化。
本文探讨了在使用Hibernate处理十万级数据量时遇到的问题,通过关闭二级缓存、分批保存和调整配置,实现了批量保存操作。控制器中将数据分块处理,每批一万条,服务层和DAO层配合完成数据的刷新与持久化。
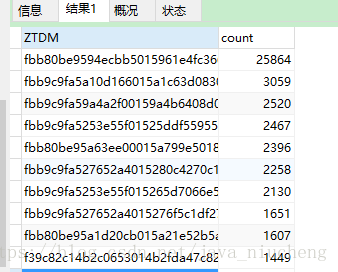
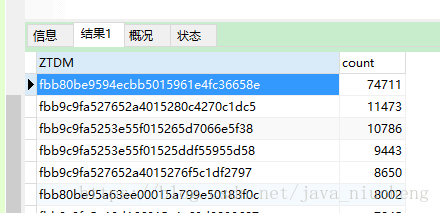
图一是我导入的第一张表,最大数据量也就2万多条,hibernate关闭二级缓存勉强能够导入,导入图二的7万多条数据时,就会在执行hibernate的save()停在2万多条.
具体配置:
1.修改spring的管理hibernate的配置
<bean id="webDataSource" class="com.alibaba.druid.pool.DruidDataSource"
</span>init-method="init" destroy-method="close">
</span><property name="url" value="${web.jdbc.connection.url}" />
</span><property name="username" value="${web.jdbc.connection.username}" />
</span><property name="password" value="${web.jdbc.connection.password}" />
</span><!-- 配置初始化大小、最小、最大 -->
</span><property name="initialSize" value="1" />
</span><property name="minIdle" value="1" />
</span><property name="maxActive" value="20" />
</span><!-- 配置获取连接等待超时的时间 -->
</span><property name="maxWait" value="6000000" />
</span><!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
</span><property name="timeBetweenEvictionRunsMillis" value="60000" />
</span><!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
</span><property name="minEvictableIdleTimeMillis" value="300000" />
</span><!-- 验证连接有效与否的SQL,不同的数据配置不同 -->
</span><property name="validationQuery" value="SELECT 'x'" />
</span><property name="testWhileIdle" value="true" />
</span><property name="testOnBorrow" value="false" />
</span><property name="testOnReturn" value="false" />
</span><!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
</span><property name="poolPreparedStatements" value="false" />
</span><property name="maxPoolPreparedStatementPerConnectionSize" </span>value="50" />
</span><!-- 配置监控统计拦截的filters -->
</span><property name="filters" value="stat" />
</bean>
<bean id="webSessionFactory"
class="org.springframework.orm.hibernate4.LocalSessionFactoryBean">
<property name="dataSource" ref="webDataSource" />
<<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">org.hibernate.dialect.MySQLDialect</prop>
<prop key="hibernate.current_session_context_class">org.springframework.orm.hibernate4.SpringSessionContext</prop>
<prop key="jdbc.use_scrollable_resultset">false</prop>
<prop key="hibernate.hbm2ddl.auto">none</prop>
<prop key="hibernate.show_sql">false</prop>
<prop key="hibernate.format_sql">false</prop>
<prop key="hibernate.jdbc.fetch_size">50</prop><!-- 每次从数据库中读取的记录条数,mysql不支持, -->
<prop key="hibernate.jdbc.batch_size">500</prop><!-- 批量删除,批量更新和批量插入的时候的批次大小 -->
<prop key=" hibernate.cache.use_second_level_cache">false</prop> <!-- 关闭hibernate耳机缓存 -->
</props>
</property>
<property name="mappingLocations">
<list>
<value>classpath:com/greatchn/htykj/db/po/*.hbm.xml</value>
</list>
</property>
</bean>
<bean id="webTransactionManager" class="org.springframework.orm.hibernate4.HibernateTransactionManager">
<property name="sessionFactory" ref="webSessionFactory" />
</bean>
<!-- 配置JDBC模板 -->
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="webDataSource"></property>
</bean>
<!-- 配置HIBERNATE模板 -->
<bean id="hibernateTemplate" class="org.springframework.orm.hibernate3.HibernateTemplate">
<property name="sessionFactory" ref="webSessionFactory" />
</bean>
<tx:annotation-driven transaction-manager="webTransactionManager" proxy-target-class="true" />
把hibernate的批量操作设置为:500,关闭hibernate的二级缓存.
注意:做海量数据批量操作一定要关闭显示执行的sql语句.(我导入7万多条数据,停在2万条有一个原因就是这个).
@Controller层: 因为数据量太大,把查询查询到List分成10000条一份,分批次执行保存方法
zwPzfls是查询的到74711条的数据,
int p = 0;
if (zwPzfls.size() % 10000 == 0) {
p = zwPzfls.size() / 10000;
} else {
p = zwPzfls.size() / 10000 + 1;
}
List zwPzflstemp = new ArrayList();
System.out.println("共" + p + "批");
for (int k = 1; k <= p; k++) {
if (k == p) {
System.out.println("第" + k + "批的10000条开始");
for (int l = (k - 1) * 10000; l < zwPzfls.size(); l++) {
ZwPzfl fl = zwPzfls.get(l);
zwPzflstemp.add(fl);
if (l == zwPzfls.size() - 1) {
htykj2Service.saveZwpzfl(zwPzflstemp);
zwPzflstemp.clear();
}
}
System.out.println("第" + k + "批的10000条结束");
} else {
System.out.println("第" + k + "批的10000条开始");
for (int l = (k - 1) * 10000; l < k * 10000; l++) {
ZwPzfl fl = zwPzfls.get(l);
zwPzflstemp.add(fl);
if (l == k * 10000 - 1) {
htykj2Service.saveZwpzfl(zwPzflstemp);
zwPzflstemp.clear();
}
}
System.out.println("第" + k + "批的10000条结束");
}
} @Service层:
public void saveZwpzfl(List<ZwPzfl> pzflList) throws Exception{
baseDao2Htykj.savePzflList(pzflList);
}@Dao层:
关键点:每一千条刷新并写入数据库 ,并清除seesion
public void savePzflList(List<?> list) {
try {
Session session = this.webSessionFactory.getCurrentSession();
//Transaction tx= session.beginTransaction();
for (int i = 0; i < list.size(); i++) {
ZwPzfl pzflList = (ZwPzfl) list.get(i);
pzflList.getId();
// System.out.println("::::::::::::::::::这个分录的id::::::::::::::::::"+ pzflList.getId() );
// System.out.println(".......执行进度:::......"+i);
session.save(list.get(i));
if(i%1000 == 0){ //每一千条刷新并写入数据库
session.flush();
session.clear();
}
}
// session.getTransaction().commit();
} catch (Exception e) {
e.printStackTrace();
}finally {
closeSession();
}
}
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









