







一、本文介绍
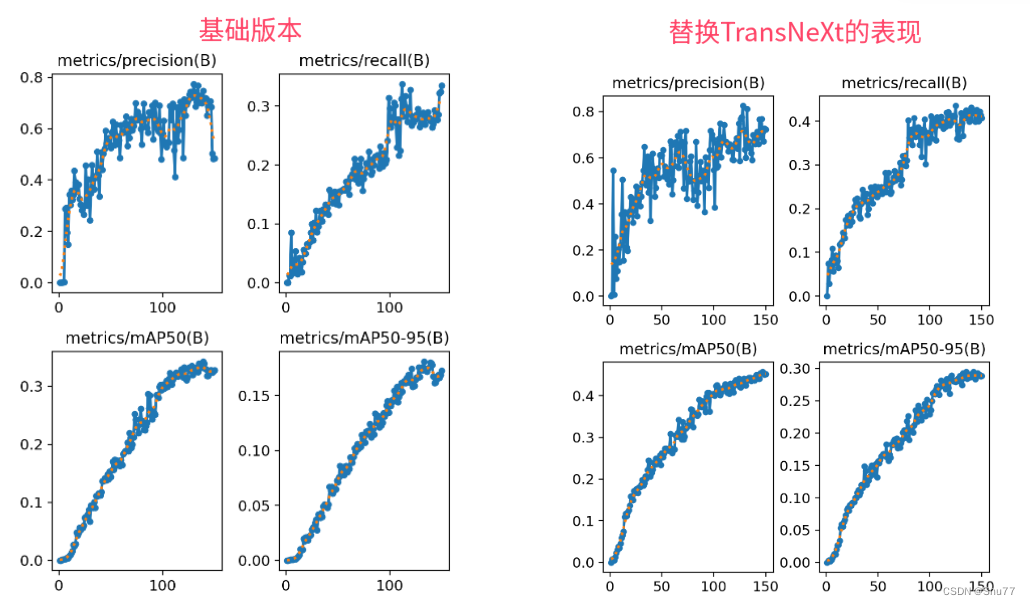
本文给大家带来的改进机制是TransNeXt特征提取网络,将其应用在我们的特征提取网络来提取特征,同时本文给大家解决其自带的一个报错,通过结合聚合的像素聚焦注意力和卷积GLU,模拟生物视觉系统,特别是对于中心凹的视觉感知。这种方法使得每个像素都能实现全局感知,并强化了模型的信息混合和自然视觉感知能力。TransNeXt在各种视觉任务中,包括图像分类、目标检测和语义分割,都显示出优异的性能(该模型的训练时间很长这是需要大家注意的)。
欢迎大家订阅我的专栏一起学习YOLO!
目录
本文给大家带来的改进机制是TransNeXt特征提取网络,将其应用在我们的特征提取网络来提取特征,同时本文给大家解决其自带的一个报错,通过结合聚合的像素聚焦注意力和卷积GLU,模拟生物视觉系统,特别是对于中心凹的视觉感知。这种方法使得每个像素都能实现全局感知,并强化了模型的信息混合和自然视觉感知能力。TransNeXt在各种视觉任务中,包括图像分类、目标检测和语义分割,都显示出优异的性能(该模型的训练时间很长这是需要大家注意的)。
欢迎大家订阅我的专栏一起学习YOLO!
目录
 3623
1017
3623
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

























