






 本文介绍了批量梯度下降法在优化线性回归中的应用,详细阐述了成本函数、学习曲线和梯度下降公式,并探讨了如何选择合适的步长以确保算法收敛。内容包括不同参数数量的学习曲线和迭代过程的可视化,强调了适当步长选择的重要性。
本文介绍了批量梯度下降法在优化线性回归中的应用,详细阐述了成本函数、学习曲线和梯度下降公式,并探讨了如何选择合适的步长以确保算法收敛。内容包括不同参数数量的学习曲线和迭代过程的可视化,强调了适当步长选择的重要性。
Batch Gradient Descent
We use linear regression as example to explain this optimization algorithm.
1. Formula
1.1. Cost Function
We prefer residual sum of squared to evaluate linear regression.
1.2. Visualize Cost Function
E.g. 1 :
one parameter only θ1 –> hθ(x)=θ1x1
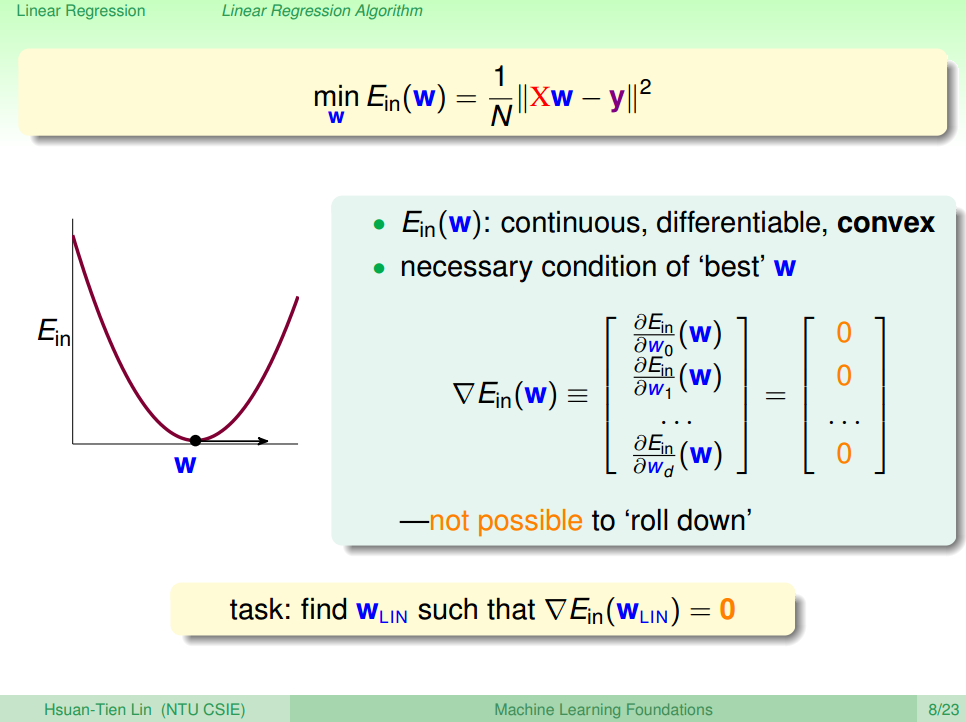
E.g. 2 :
two parameters θ0,θ1 –> hθ(x)=θ0+θ1x1
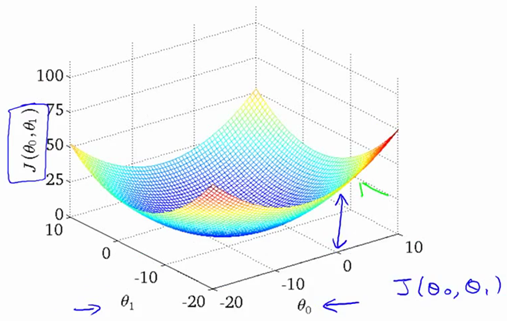
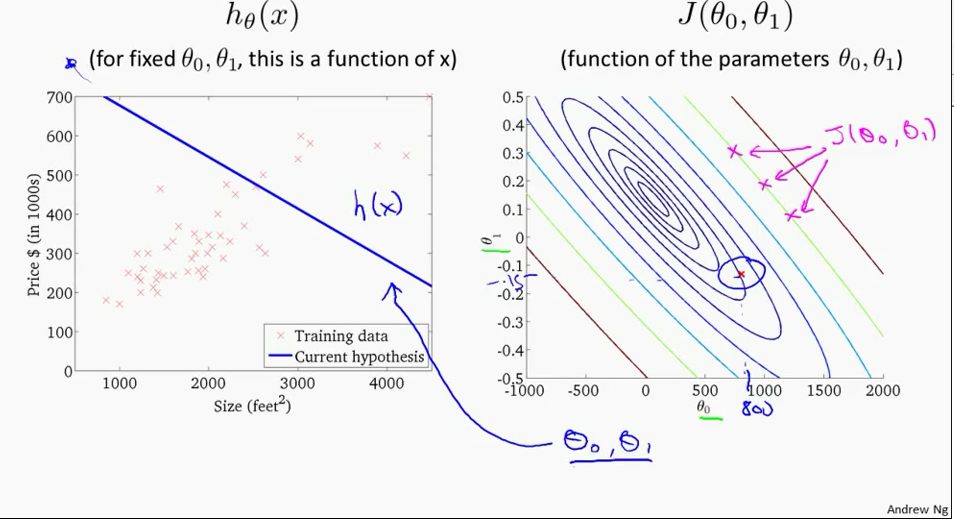
Switch to contour plot
1.3. Gradient Descent Formula
For all θi
E.g.,
two parameters θ0,θ1 –> hθ(x)=θ0+θ1x1
For i = 0 :
For i = 1:
% Octave
%% =================== Gradient Descent ===================
% Add a column(x0) of ones to X
X = [ones(len, 1), data(:,1)];
theta = zeros(2, 1);
alpha = 0.01;
ITERATION = 1500;
jTheta = zeros(ITERATION, 1);
for iter = 1:ITERATION
% Perform a single gradient descent on the parameter vector
% Note: since the theta will be updated, a tempTheta is needed to store the data.
tempTheta = theta;
theta(1) = theta(1) - (alpha / len) * (sum(X * tempTheta - Y)); % ignore the X(:,1) since the values are all ones.
theta(2) = theta(2) - (alpha / len) * (sum((X * tempTheta - Y) .* X(:,2)));
%% =================== Compute Cost ===================
jTheta(iter) = sum((X * theta - Y) .^ 2) / (2 * len);
endfor2. Algorithm
For all θi
E.g.,
two parameters θ0,θ1 –> hθ(x)=θ0+θ1x1
For i = 0 :
For i = 1 :
Iterative for multiple times (depends on data content, data size and step size). Finally, we could see the result as below.
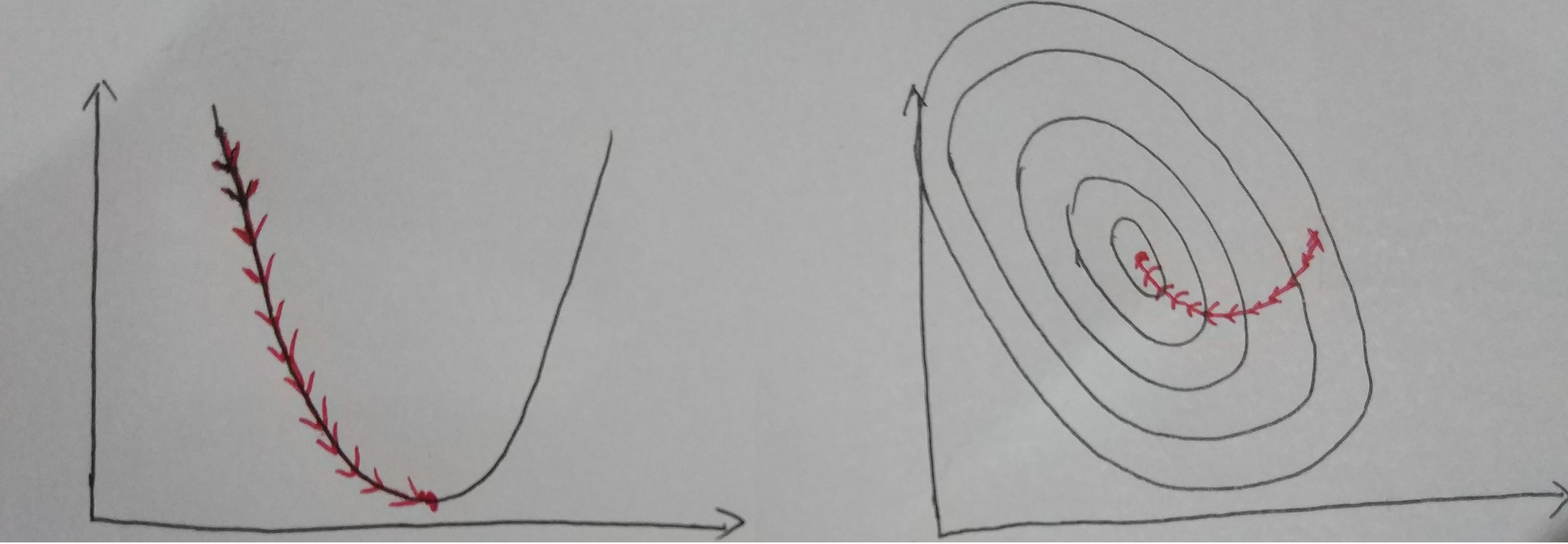
Visualize Convergence
3. Analyze
| Pros | Cons |
|---|---|
| Controllable by manuplate stepsize, datasize | Computing effort is large |
| Easy to program |
4. How to Choose Step Size?
Choose an approriate step size is significant. If the step size is too small, it doesn’t hurt the result, but it took even more times to converge. If the step size is too large, it may cause the algorithm diverge (not converge).
The graph below shows that the value is not converge since the step size is too big.
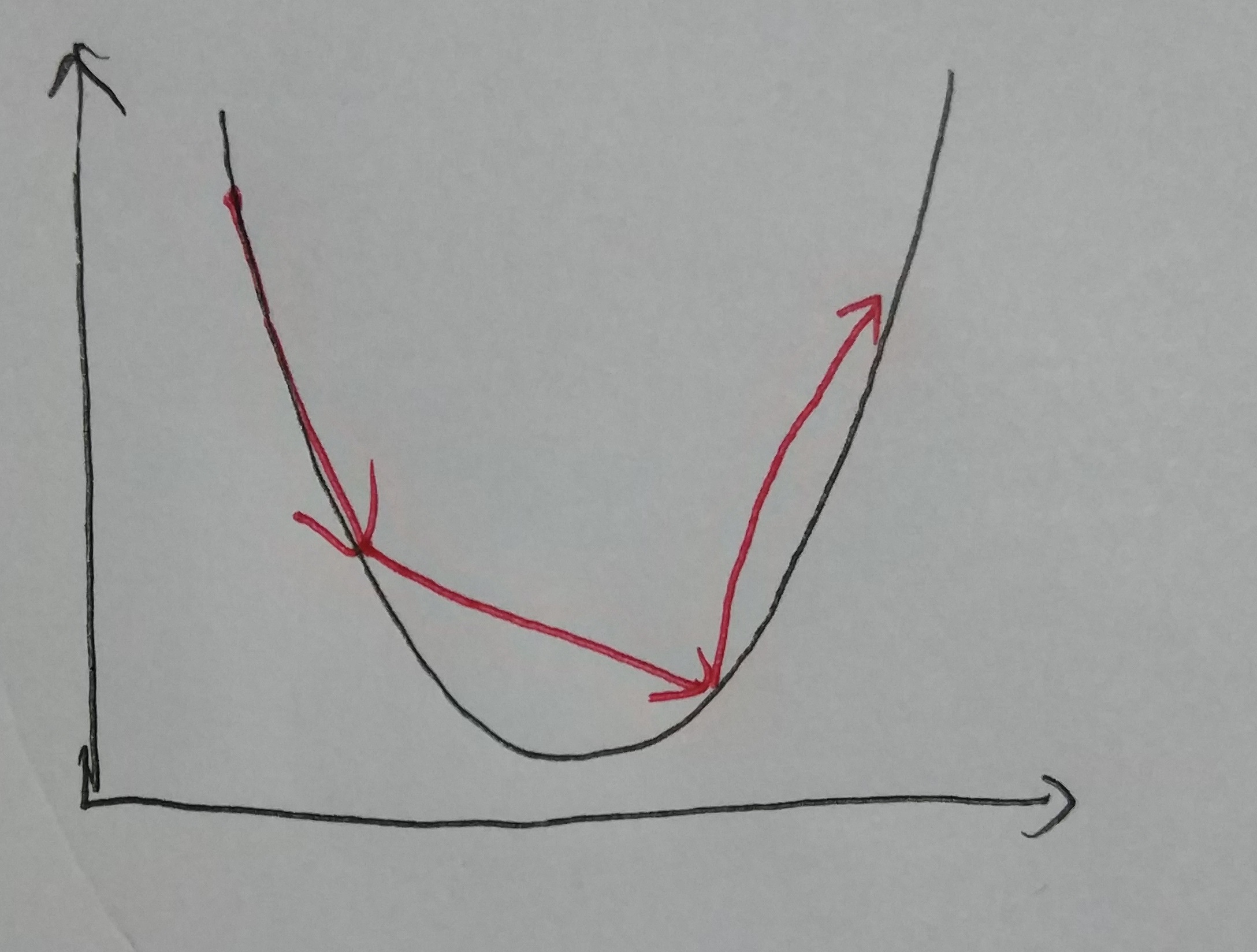
Large Step Size
The best way, as far as I know, is to decrease the step size according to the iteration times.
E.g.,
α(t+1)=αtt
or
α(t+1)=αtt√
Reference
机器学习基石(台湾大学-林轩田)\lecture_slides-09_handout.pdf
Coursera-Standard Ford CS229: Machine Learning - Andrew Ng

















 1901
1901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









