



引入:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
代码:
@GetMapping("/embeding")
public String embeding() {
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource);
List<Document> documentList = tikaDocumentReader.get();
System.out.println("size:"+documentList.size()+"documentList.get(0).getText():"+documentList.get(0).getText());
// 将文本内容划分成更小的块
List<Document> splitDocuments = new TokenTextSplitter()
.apply(documentList);
System.out.println("splitDocuments.size():"+splitDocuments.size());
return "doc to embeding";
}
问题描述:documentList.get(0).getText()为空。
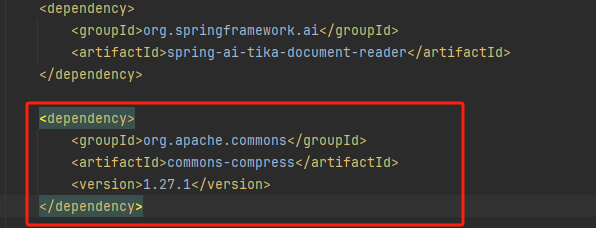
原因:spring-ai-tika-document-reader依赖了commons-compress。由于ommons-compress与其他模块的版本冲突,所以排除了本模块的ommons-compress之后,导致无法获取得到text内容。
解决方法:
单独把加到本模块

















 242
242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









