







论文题目:A Memory-Augmented Self-Supervised Tracker
论文地址:https://arxiv.org/abs/2002.07793
这篇文章是今年牛津VGG组发表在ECCV20的文章,主要是用self-supervised的方法,处理Video Objects Segmentation的task。既然是自监督学习,那么训练阶段无需任何的annotation,只是通过学习到一种representation来实现frame之间像素级的关联;在测试阶段也只需要给出第一个frame的mask,后续frame的mask通过第0帧给定的mask进行预测。

本文的三大贡献如下:
(1)重新评估了过去的一些自监督方法,并给出了最优的选择;
(2)设计了一种存储结构—— memory bank,用来存放一些short-term以及long-term的帧信息,可以处理一些occluded instance;
(3)在video segmentation上面提出了一种新的metric——generalizability。
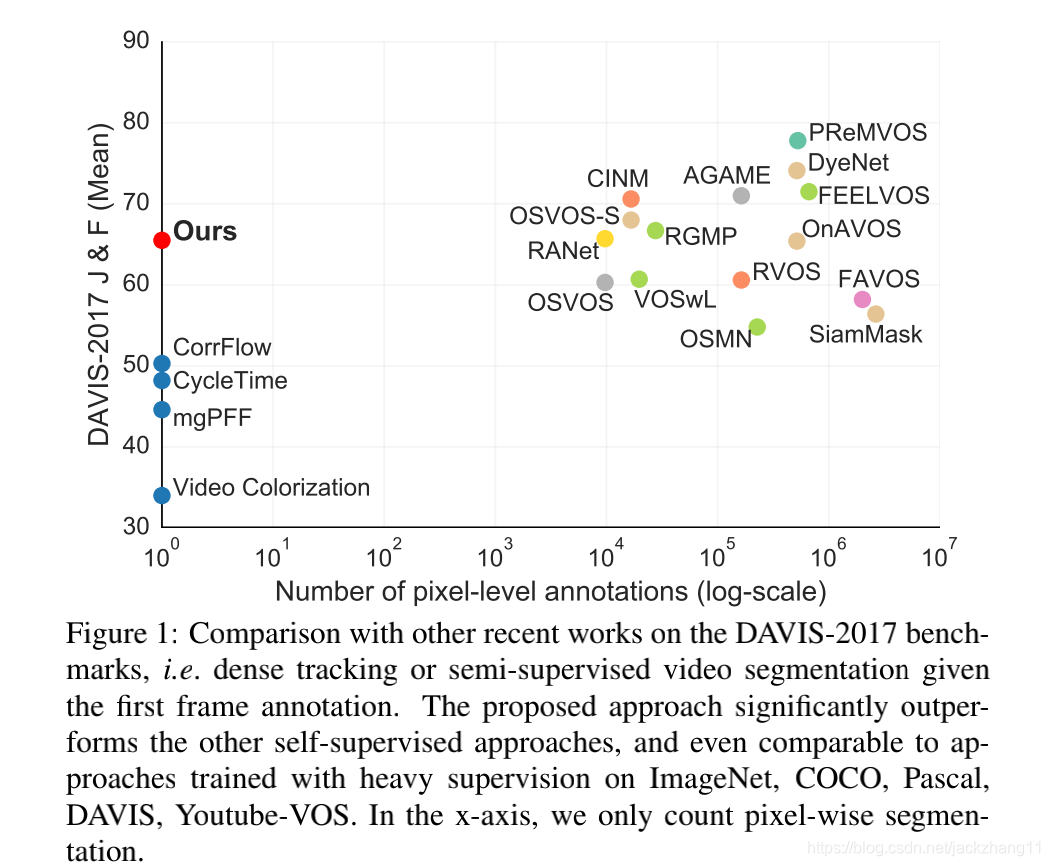
上图展示了一些无监督和有监督方法,在DAVIS-2017上的表现。可以发现过去的self-supervised方法普遍和supervised方法之间存在不小的gap,而本文的MAST已经达到甚至超越了一些有监督模型的performance,可以说比较强大。
Background
介绍了该论文的背景,自监督tracking的目标就是学习到一种feature representation,用来进行帧之间像素级的联系。主要是如何利用上一帧It−1I_{t-1}It−1来重构当前帧图像ItI_{t}It,此时这个t-1帧称为reference frame,需要我们找到这两个frame之间的关联性。
那么怎么做呢?首先我们可以在第t帧,定义一个三元组(Qt,Kt,Vt)({Q_{t},K_{t}},V_{t})(Qt,Kt,V
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









