







目录
1 前言
2 大模型如何在业务中发挥作用
3 普通程序员应该关注的机会
4 总结
最近几年,大模型在技术领域的火热程度属于一骑绝尘遥遥领先,它已经深刻地影响了“编程”领域,且正在各个领域迅速渗透。与此同时,普通开发者也变得非常地焦虑,因为实实在在感受到了它强大的威力,担心哪天自己就被取代。与其担忧,我们不如主动拥抱这种技术变革。
前言
最近几年,大模型在技术领域的火热程度属于一骑绝尘遥遥领先,不论是各种技术论坛还是开源项目,大多都围绕着大模型展开。大模型的长期目标是实现 AGI,这可能还有挺长的路要走,但是眼下它已经深刻地影响了“编程”领域。各种 copilot 显著地提升了开发者的效率,但与此同时,开发者也变得非常地焦虑。因为开发者们实实在在感受到了它强大的能力,虽然目前只能辅助还有很多问题,但随着模型能力的增强,以后哪天会不会就失业了?与其担忧,我们不如主动拥抱这种技术变革。
但是很多人又会打退堂鼓:研究 AI 的门槛太高了,而大模型属于 AI 领域皇冠上的明珠,可能需要深厚的数学和理论基础。自己的微积分线性代数概率论这三板斧早都忘光了,连一个最基础的神经网络反向传播的原理都看不懂,还怎么拥抱变革?
其实大可不必担心,不论大模型吹得如何天花乱坠,还是需要把它接入到业务中才能产生真正的价值,而这归根到底还是依赖我们基于它之上去做应用开发。而基于大模型做业务开发,并不依赖我们对 AI 领域有深入的前置了解。就好比我们做后台业务开发,说到底就是对数据库增删改查,数据库是关键中的关键。理论上你需要懂它了解它,但其实你啥也不懂也没太大影响,只是“天花板低“而已,有些复杂场景你就优化不了。基于大模型做应用开发也是一样,你不需要了解大模型本身的原理,但是怎么结合它来实现业务功能,则是开发者需要关心的。
本文是给所有非 AI 相关背景的开发人员写的一个入门指南,目标是大家读完之后能够很清晰地明白以下几点:
-
参与大模型应用开发,无需任何 AI 和数学知识背景,不必担心学习门槛。
-
了解基于LLM的应用开发的流程、各个环节,最后可以自信地说:我行我上啊。
-
大模型怎么和具体业务知识结合起来,实现用户真正需要的功能——RAG。
-
我们广大非 AI 背景的开发人员,在大模型的浪潮中如果想卷一下,发力点在哪里——AI Agent。
大模型如何在业务中发挥作用
目前的大语言模型,几乎都是以聊天地方式来和用户进行交互的,这也是为什么 OpenAI 开发的大模型产品叫 ChatGPT,核心就是 Chat。而我们基于大语言模型 LLM 开发应用,核心就是利用大模型的语义理解能力和推理能力,帮我们解决一些难以用“标准流程”去解决的问题,这些问题通常涉及:理解非结构化数据、分析推理 等。
一个典型的大模型应用架构如下图所示,其实和我们平时开发的应用没什么两样。我们平时开发应用,也是处理用户请求,然后调用其它服务实现具体功能。在这个图中,大模型也就是一个普通的下游服务。
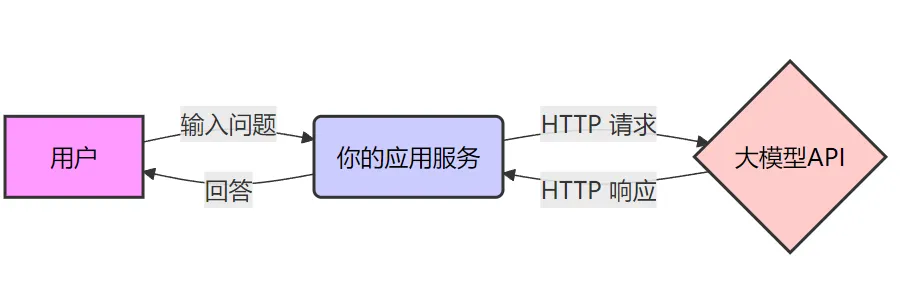
不过像上图的应用,没有实际的业务价值,通常只是用来解决的网络连不通的问题,提供一个代理。真正基于大模型做应用开发,需要把它放到特定的业务场景中,利用它的理解和推理能力来实现某些功能。
2.1 最简单的大模型应用
下图就是一个最简单的 LLM 应用:

和原始的 LLM 的区别在于,它支持 联网搜索。可能大家之前也接触过可以联网搜索的大模型,觉得这也没啥,应该就是大模型的新版本和老版本的区别。其实不然,我们可以把大模型想象成一个有智慧的人,而人只能基于自己过去的经验和认知来回答问题,对于没学过或没接触过的问题,要么就是靠推理要么就是胡说八道。大语言模型的“智慧”完全来自于训练它的数据,对于那些训练数据之外的,它只能靠推理,这也是大家经常吐槽它“一本正经的胡说八道”的原因——它自身没有能力获取外界的新知识。但假如回答问题时有一个搜索引擎可供它使用,对于不确定的问题直接去联网搜,最后问答问题就很简单了。
带联网功能的聊天大模型就是这样一种“大模型应用”,看起来也是聊天机器人,但其实它是通过应用代码进行增强过的机器人:
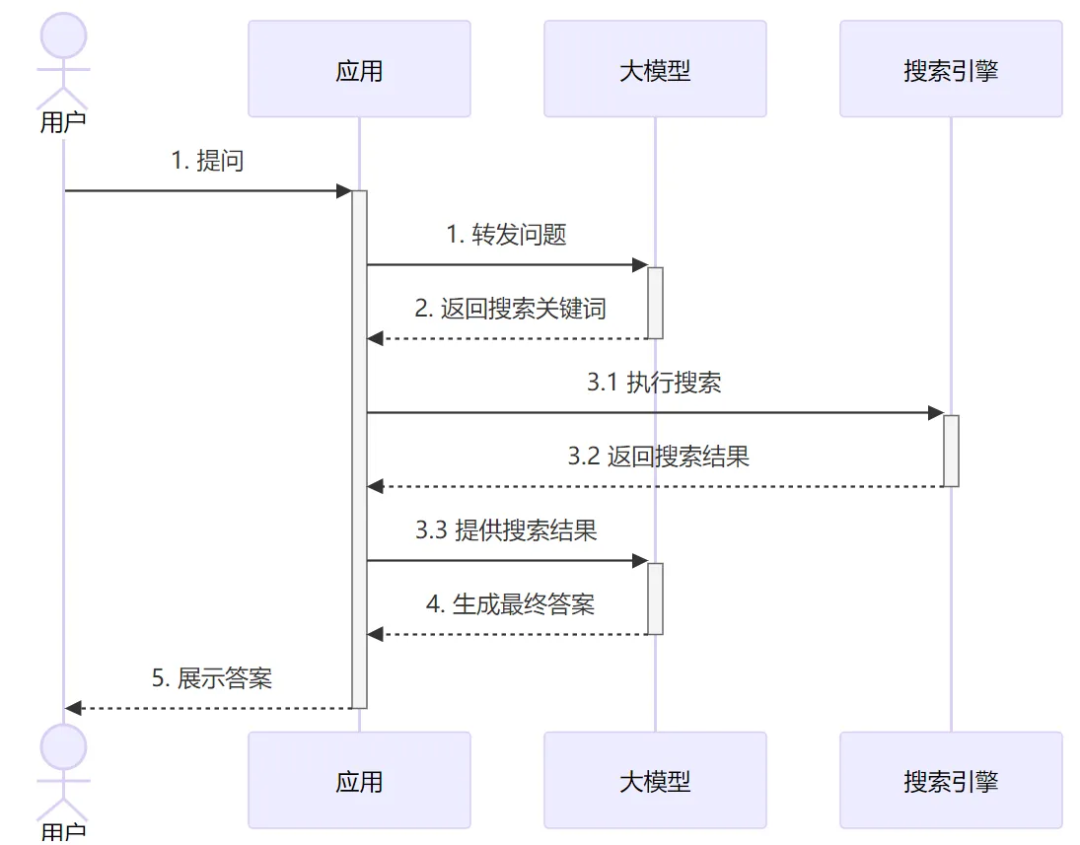
从图中可以看到,为了给用户的问题生成回答,实际上应用和 LLM 进行了两轮交互。第一轮是把原始问题给大模型,大模型分析问题然后告诉应用需要联网去搜索什么关键词(如果大模型觉得不需要搜索,也可以直接输出答案)。应用侧使用大模型给的搜索关键词 调用外部 API 执行搜索,并把结果发给大模型。最后大模型基于搜索的结果,再推理分析给出最终的回答。
从这里例子中我们可以看到一个基于大模型开发应用的基本思路:应用和大模型按需进行多轮交互,应用侧主要负责提供外部数据或执行具体操作,大模型负责推理和发号施令。
2.2 怎么和 LLM 进行协作——Prompt Engineering
以我们平时写代码为例,为了实现一个功能,我们通常会和下游服务进行多次交互,每次调不通的接口实现不同的功能:
func AddScore(uid string, score int) {// 第一次交互user := userService.GetUserInfo(uid)// 应用本身逻辑newScore := user.score + score// 第二次交互userService.UpdateScore(uid, score)}
如果从我们习惯的开发视角来讲,当要开发前面所说的联网搜索 LLM 应用时,我们期望大模型能提供这样的 API 服务:
service SearchLLM {// 根据问题生成搜索关键词rpc GetSearchKeywords(Question) Keywords;// 参考搜索结果 对问题进行回答rpc Summarize(QuestionAndSearchResult) Answer;}
有了这样的服务,我们就能很轻易地完成开发了。但是,大模型只会聊天,它只提供了个聊天接口,接受你的问题,然后以文本的形式给你返回它的回答。那怎么样才能让大模型提供我们期望的接口?——答案就是靠 “话术(嘴遁)”,也叫 Prompt(提示词)。因为大模型足够 “智能”,只要你能够描述清楚,它就可以按照你的指示来 “做事”,包括按照你指定的格式来返回答案。
我们先从最简单的例子讲起——让大模型返回确定的数据格式。
让大模型返回确定的数据格式
简单讲就是你在提问的时候就明确告诉它要用什么格式返回答案,理论上有无数种方式,但是归纳起来其实就两种方式:
Zero-shot Prompting (零样本提示)。
Few-shot Learning/Prompting (少样本学习/提示)。
这个是比较学术比较抽象的叫法,其实它们很简单,但是你用 zero-shot、few-shot 这种词,就会显得很专业。
Zero-shot
直接看个 Prompt 的例子:
帮我把下面一句话的主语谓语宾语提取出来要求以这样的json输出:{"subject":"","predicate":"","object":""}---这段话是:我喜欢唱跳rap和打篮球
在这个例子中,所谓的 zero-shot,我没给它可以参考的示例,直接就说明我的要求,让它照此要求来进行输出。与只对应的 few-shot 其实就是多加了些例子。
Few-shot
比如如下的 prompt:
帮我解析以下内容,提取出关键信息,并用JSON格式输出。给你些例子:input: 我想去趟北京,但是最近成都出发的机票都好贵啊output: {"from":"成都","to":"北京"}input: 我看了下机票,成都直飞是2800,但是从香港中转一下再到新西兰要便宜好几百output: {"from":"成都","to":"新西兰"}input: 之前飞新加坡才2000,现在飞三亚居然要单程3000,堂堂首都票价居然如此高昂,我得大出血了output: {"from":"北京","to":"三亚"}
从这个 prompt 中可以看到,我并没有明确地告诉大模型要提取什么信息。但是从这3个例子中,它应该可以分析出来2件事:
-
以
{"from":"","to":""}这种 JSON 格式输出。 -
提取的是用户真正的
出发地和目的地。
这种在 prompt 中给出一些具体示例让模型去学习的方式,这就是所谓的 few-shot。不过,不论是 zero-shot 还是 few-shot,其核心都在于 更明确地给大模型布置任务,从而让它生成符合我们预期的内容。当然,约定明确的返回格式很重要但这只是指挥大模型做事的一小步,为了让它能够完成复杂的工作,我们还需要更多的指令。
怎么和大模型约定多轮交互的复杂任务
回到最初联网搜索的应用的例子,我给出一个完整的 prompt,你需要仔细阅读这个 prompt,然后就知道是怎么回事了:
你是一个具有搜索能力的智能助手。你将处理两种类型的输入:用户的问题 和 联网搜索的结果。1. 我给你的输入格式包含两种:1.1 用户查询:{"type": "user_query","query": "用户的问题"}1.2 搜索结果:{"type": "search_result","search_keywords": ["使用的搜索关键词"],"results": [{"title": "搜索结果标题","snippet": "搜索结果摘要","url": "来源URL",}],"search_count": number // 当前第几次搜索}2. 你需要按如下格式给我输出结果:{"need_search": bool,"search_keywords": ["关键词1", "关键词2"], // 当need_search为true时必须提供"final_answer": "最终答案", // 当need_search为false时提供"search_count": number, // 当前是第几次搜索,从1开始"sources": [ // 当提供final_answer时,列出使用的信息来源{"url": "来源URL","title": "标题"}]}3. 处理规则:- 收到"user_query"类型输入时:* 如果以你的知识储备可以很确定的回答,则直接回答* 如果你判断需要进一步搜索,则提供精确的search_keywords- 收到"search_result"类型输入时:* 分析搜索结果* 判断信息是否足够* 如果信息不足且未达到搜索次数限制,提供新的搜索关键词* 如果信息足够或达到搜索限制,提供最终答案4. 搜索限制:- 最多进行3次搜索- 当search_count达到3次时,必须给出最终答案- 每次搜索关键词应该基于之前搜索结果进行优化5. 注意事项:- 每次搜索的关键词应该更加精确或补充不足的信息- 最终答案应该综合所有搜索结果
看完这个 prompt,假如 LLM 真的可以完全按照 prompt 来做事,可能你脑子中很快就能想到应用代码大概要如何写了(伪代码省略海量细节):
const SYSTEM_PROMPT = "刚才的一大段提示词"async function chatWithSearch(query, maxSearches = 3) {// 初始调用,给
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











