







111111
简要介绍
本文通过调用torchvision.models中的resnet18模型来简洁实现ResNet18
————————————————————
数据集文件视图:
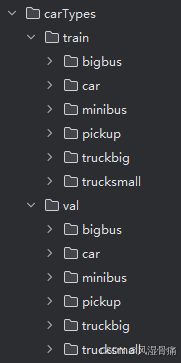
(训练集大约有3650张图片)
因为各个数据都在名称为自己label的文件夹下,所以我们使用torchvision.datasets.ImageFolder读取数据集
————————————————————
源代码:
import os # 标准库
import torch # 第三方库
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
import matplotlib.pyplot as plt
# 超参数设置
BATCH_SIZE = 32
LEARNING_RATE = 0.01
EPOCHS = 15
filepath = r'./carTypes'
# 数据预处理
transform = transforms.Compose([
transforms.Resize((128, 128)),
# transforms.RandomHorizontalFlip(), # 随机水平翻转
# transforms.RandomRotation(15), # 随机旋转
# transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 随机颜色调整
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# 加载数据集
dataset_train = datasets.ImageFolder(filepath + r'/train', transform)
dataset_test = datasets.ImageFolder(filepath + r'/val', transform)
NUM_CLASSES = len(dataset_train.classes) # 汽车型号类别数
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)#
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False, drop_last=False)#
# 加载 ResNet18 模型到指定路径
os.environ['TORCH_HOME'] = filepath
model = models.resnet18(pretrained=True)
# 迁移学习:冻结预训练层
for param in model.layer1.parameters():
param.requires_grad = False
for param in model.layer2.parameters():
param.requires_grad = False
for param in model.layer3.parameters():
param.requires_grad = False
# 修改最后的全连接层,使其适应汽车型号的类别数
model.fc = nn.Linear(model.fc.in_features, NUM_CLASSES)
# 使用 GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
# 使用Adam
#optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
# 使用SGD和动量参数
optimizer = optim.SGD(model.parameters(), lr=LEARNING_RATE, momentum=0.9)
# 动态调整学习率
# scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 训练模型
def train(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for batch_idx, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
# 添加梯度裁剪,防止梯度爆炸
# torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
running_loss += loss.item()
if batch_idx % 10 == 9: # 每 10 个批次输出一次损失值
print(f'Epoch [{epoch}/{EPOCHS}]: Step [{batch_idx + 1}/{len(train_loader)}], Loss: {running_loss / 10:6f}')
loss_list.ap 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









