




队列基础,一对一无锁
队列就是一个先进先出的数据结构,一般使用链表实现,如下图:
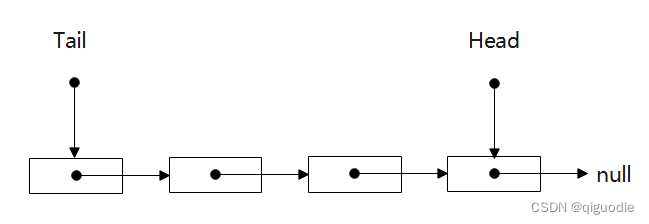
数据从Head进入链表,从Tail出链表。我们会发现,只要链表一直不是空的,那么Head指针和Tail指针是完全无关的,也就是读写之间不加锁的线程安全比较容易实现,我们只要保证链表从初始化开始Head和Tail就无关即可,那么一对一的生产者和消费者无锁队列就可以十分简单地实现,显然Tail或者Head直接指向的内存我们不用来存储数据,是最合理的。
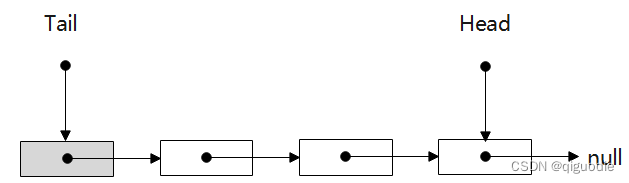
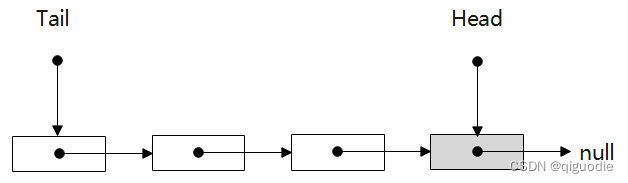
上述两种方式都可以,我们采用第一种展开讲述。在队列创建时,我们让Head和Tail共同指向一个不存储数据的内存,从此这两个指针就可以毫不相干了,后续生产消费中,Tail总是预留一个不存储数据的内存节点,而Head则只需要完成自己的指向操作。以下是相关代码:
template <typename T>
class T1V1Queue : NonCopyable {
public:
using ElementType = T;
T1V1Queue() : mSize(0) { mHead = mTail = new TNode; }
~T1V1Queue() {
while (mTail != nullptr) {
T 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









