




Data+AI━━大模型太慢?这个神奇的量化技术让推理速度提升50%!
前言
深夜加班写代码,你的大模型又在"磨磨唧唧"?一条简单的prompt要等半天才蹦出答案?别着急摔键盘,问题不在你,是大模型需要"提提速"了!
从OpenAI的重磅更新到国内大模型百花齐放,AI已经完全融入我们的工作生活。可是当我们期待AI像人类一样流畅对话时,推理性能却成了绕不过的"拦路虎"。尤其在显卡紧缺、成本高企的当下,如何让大模型跑得更快、花费更少,成了每个AI从业者的必修课。
让我们一起揭秘顶尖AI公司的性能优化秘籍,看看他们如何让大模型"健步如飞"。从显存优化到计算加速,从推理提速到成本优化,一场技术与创新的饕餮盛宴即将开启!

大模型推理时代的技术突围
生成式AI掀起的技术革命正达到新的高峰。大模型应用走进日常生活,推理性能优化成为AI从业者必须面对的重要课题。在这个技术与应用快速迭代的时代,我们需要思考:如何让大模型更快、更高效地服务用户?
A800、H800等高端AI芯片供不应求,4090等消费级显卡成为创业公司的重要选择。在硬件资源有限的约束下,推理性能优化显得尤为关键。让我们深入探讨大模型推理优化的核心技术。
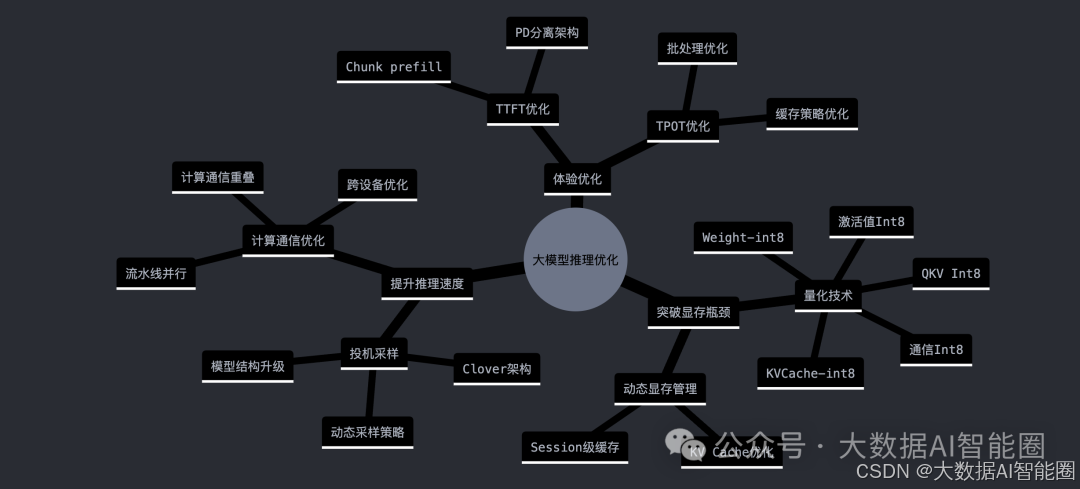
量化技术已成为大模型性能优化的关键一环。在智能的实践中,通过将模型权重和KV Cache量化到int8精度,显存占用直接降低50%。这意味着同样的硬件可以服务更多用户,极大地降低了运营成本。
激活值量化是另一个重要突破。通过将GEMM相关计算的输入激活量化到int8,首个token的生成时间缩短了50%。更进一步,采用int4量化技术,可以让模型在低端显卡上流畅运行,支持更长的上下文长度。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1774
1774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











