








 超级会员免费看
超级会员免费看


Data+AI━━数据分析师即将失业?Agent智能分析助手3分钟完成2天工作量
还记得第一次给老板做数据分析的场景吗?面对Excel里密密麻麻的数字,我陷入"分析恐惧症"。好不容易做完PPT,老板一句"这些我都知道,给点有价值的洞察"让我瞬间石化。
最近在拜访企业客户时,一位CTO的吐槽令我印象深刻:“数据中台投了上千万,却天天被业务部门吐槽’看不懂、用不了’。”
是的,这就是当下企业的数据困境 - 数据很多,洞察很少;工具很贵,门槛很高;分析师很忙,需求更多…
直到大模型技术横空出世,为这些痛点带来曙光。想象一下,对着电脑说"帮我分析下上季度业绩下滑的原因",智能助手就能给出专业级的分析报告,这样的场景已不再是科幻。
本文将为你揭秘大模型如何重构企业数据分析新范式,带你探索AI赋能下的智能分析未来。

数据智能新范式:大模型重构企业数据分析体验
随着企业数字化转型深入,数据分析需求呈现爆发式增长。一位大型零售集团的CTO曾向我吐槽:"我们花了上千万搭建数据中台、建设数据仓库,结果业务部门天天反馈’看不懂数据、用不了数据’。"这样的困境并非个例。
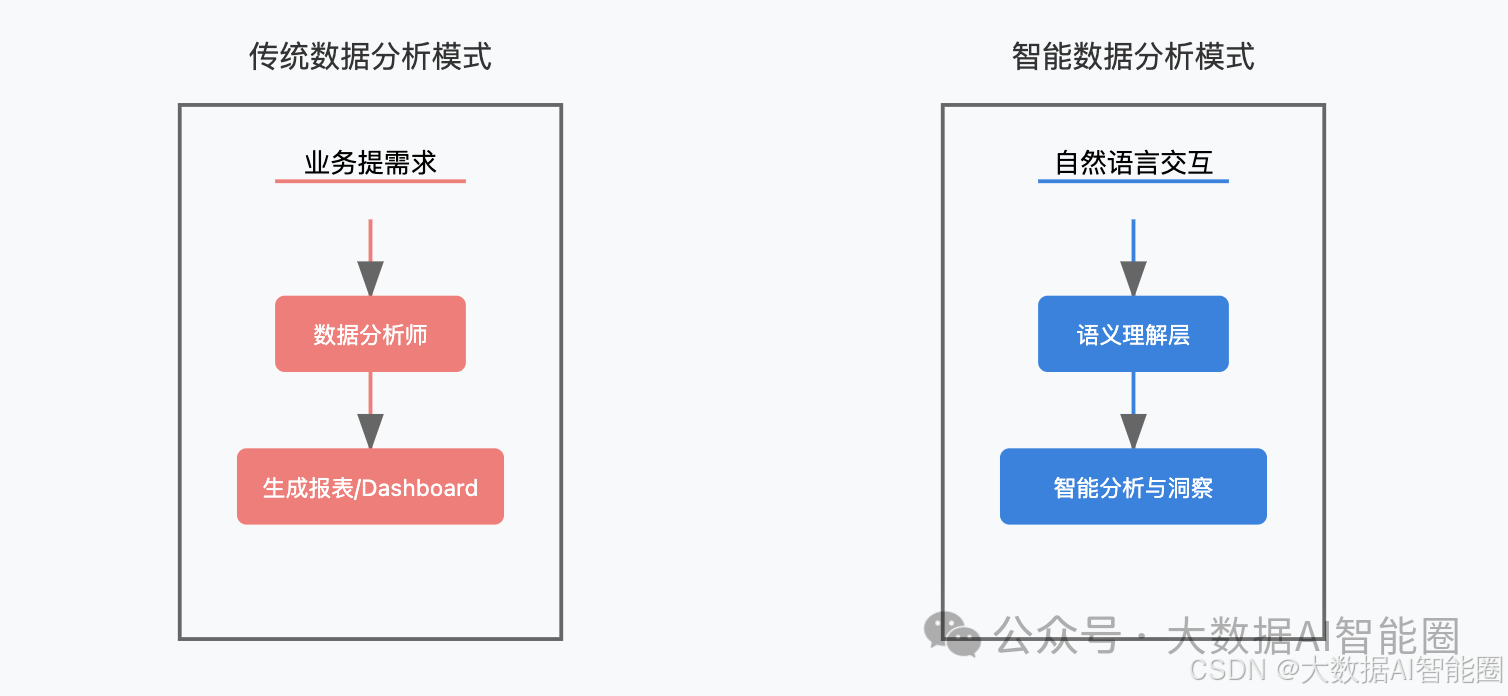
在数据资产丰富的今天,企业面临三大典型痛点:
管理层眼中,数据不等于洞察。某

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











