




借鉴:
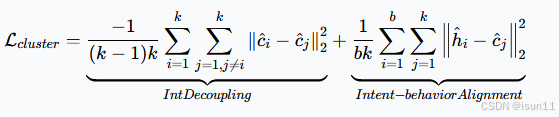
第一项旨在将复杂的用户意图解耦为简单的意图单元。从技术上讲,它将不同的聚类中心推开,从而减少不同簇(意图)之间的重叠。
第二项旨在通过将行为嵌入拉向聚类中心,使用户的潜在意图与行为对齐。这种设计使簇内分布更加紧凑,并引导网络将相似的行为浓缩为一个意图。
借鉴:
第一项旨在将复杂的用户意图解耦为简单的意图单元。从技术上讲,它将不同的聚类中心推开,从而减少不同簇(意图)之间的重叠。
第二项旨在通过将行为嵌入拉向聚类中心,使用户的潜在意图与行为对齐。这种设计使簇内分布更加紧凑,并引导网络将相似的行为浓缩为一个意图。
 6996
1万+
775
981
6996
1万+
775
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























