




 本文探讨了YOWO结构在行为识别领域的应用,特别是在非标准餐厅数据集上的表现。YOWO结合了空间信息和时空特征,通过CFAM机制提升识别准确性。尽管在某些行为上表现优异,如‘拿起’,但在‘放下’等行为上因样本不平衡而受限。论文对比了Yolo与Yowo的性能,发现前者在部分行为识别上竟优于后者,突显了空间信息的重要性。
本文探讨了YOWO结构在行为识别领域的应用,特别是在非标准餐厅数据集上的表现。YOWO结合了空间信息和时空特征,通过CFAM机制提升识别准确性。尽管在某些行为上表现优异,如‘拿起’,但在‘放下’等行为上因样本不平衡而受限。论文对比了Yolo与Yowo的性能,发现前者在部分行为识别上竟优于后者,突显了空间信息的重要性。
0. 前言
1. 要解决什么问题
- 更像是技术报告。
- 使用不同的时空行为检测方法,在一个非标准的数据集(也就是他们自己的一个餐厅数据集上),构建一个产品(production application)
- 使用的这个餐厅数据集,无法下载,存在很多问题:
- Fast-moving actions
- small bbox
- poor class balance
- imperfect bounding bboxes and labels
2. 用了什么方法
- 使用了YOWO结构,是YOLO在行为识别方向上的扩展,具体的会单独写一篇论文介绍,本文中仅简单描述。
- YOWO 有两个分支,一个从关键帧中获取空间信息,一个提取整个clip的时空特征。
- YOWO 整体结构分为三个部分
- 特征提取:分为两个部分,一个是从关键帧中提取特征,一个是从clip中提取特征。
- CFAM(channel fusion and attention mechanism),即注意力机制,通过关键帧中提取的特征作为注意力机制的输入,对clip中提取的特征进行处理。
- bbox 提取
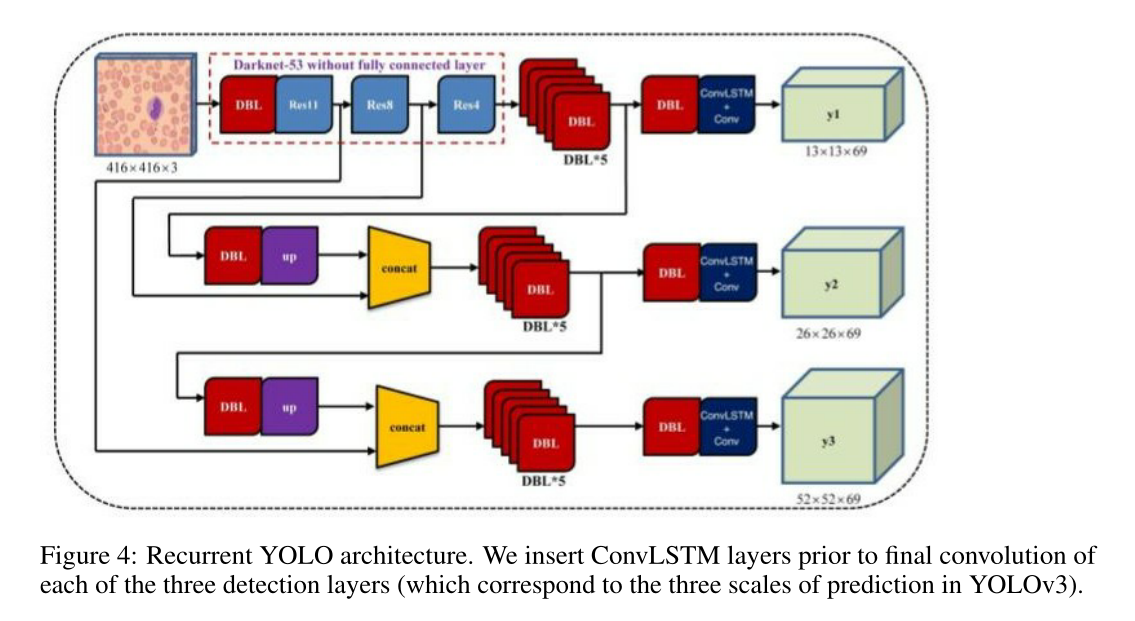
- 提出了 Recurrent YOLO
- ConvLSTM要参考论文:Convolutional LSTM network: A machine learning approach for precipitation nowcasting
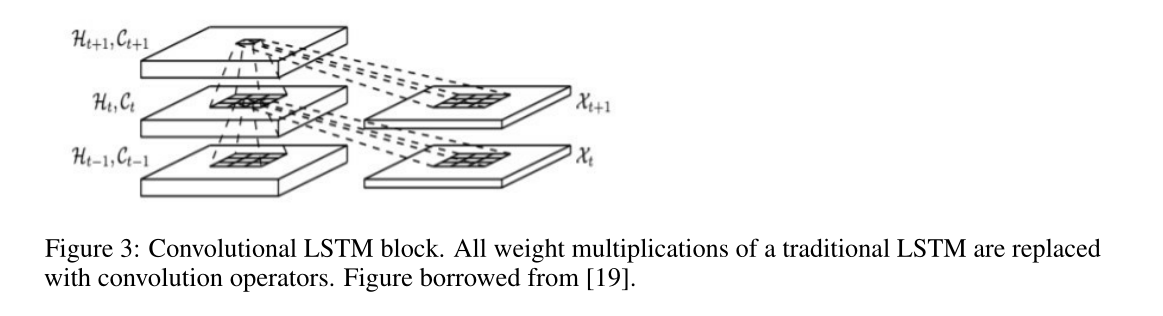
- 具体实现没看懂,结构如下
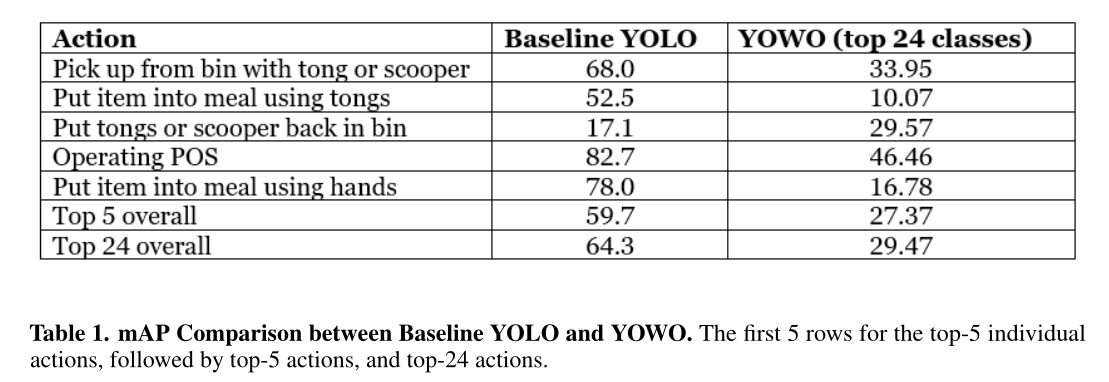
3. 效果如何
- 比较Yolo与Yowo在行为识别上的性能
- 从结果看,直接使用目标检测算法的效果竟然比行为识别的算法好。。
- 猜测原因如下:
- 部分行为可以通过单张图片片段,空间信息还是非常重要的。
- 对于时间敏感的行为(拿起、放下)可能还是Yowo比较好。
- 数据量还是不够多,比如“拿起”样本多,“放下”样本少,那对于类似的数据判断为“拿起”的概率就高,但因为样本多,所以测试的时候效果也更好……
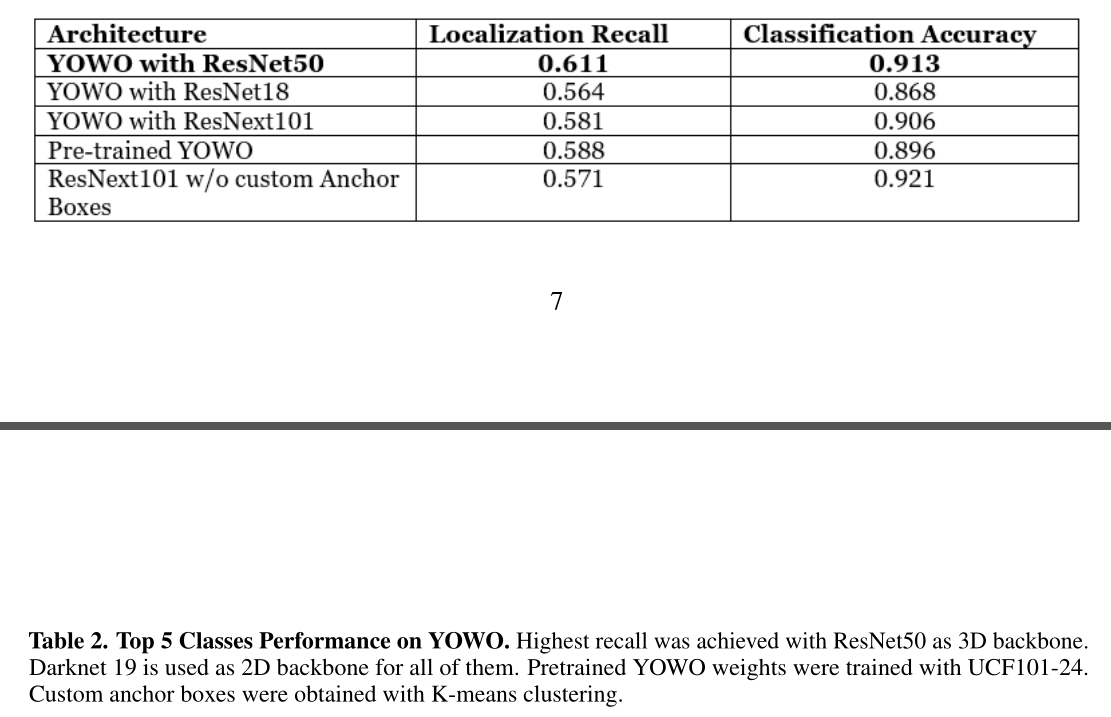
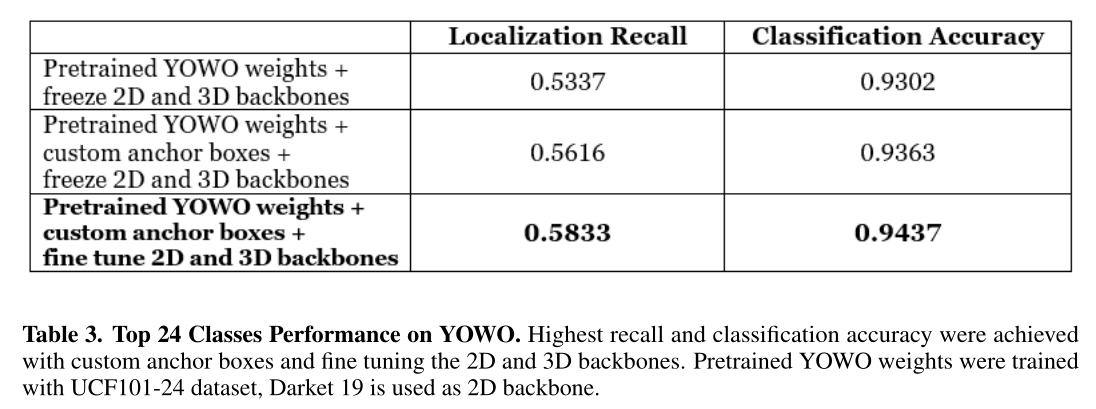
- 比较不同backend的Yowo
- 其实我对于 localization recall 算的是啥还不清楚,是时间上的定位还是空间上的定位?
- 这论文排版,我给满分
- 比较各种训练方法+tricks
- 本文提出的 Recurrent YOLO 的效果连个比较图都没,效果肯定不行。
4. 还存在什么问题&有什么可以借鉴
-
后续工作可以借鉴这篇论文,在看完Yowo论文后肯定还要研究本文的内容和源码。
-
这论文后续可能还会修改?

















 3744
3744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









