







You Only Watch Once:Architecture for Real-Time Spatiotemporal Action Localization
摘要
时空动作定位要求将两个信息源整合到设计的体系结构中:(1)来自前一帧的时间信息;(2)来自关键帧的空间信息。目前最先进的方法通常是通过单独的网络提取这些信息,并使用一种额外的融合机制来获取检测结果。在这项工作中,我们提出了一个统一的CNN架构YOWO,用于视频流中的实时时空动作定位。YOWO是一个具有两个分支的单阶段体系结构,可以在一次评估中同时提取时间和空间信息,并直接从视频剪辑中预测边界框和动作概率【个人理解就是行人检测+行为识别】。因为整个体系结构是统一的,所以可以端到端地进行优化。YOWO架构非常快,能实现16帧输入剪辑达到每秒34帧和8帧输入剪辑达到每秒62帧的速度,这是当前时空动作本地化任务上最快的最新架构 。值得注意的是,YOWO优于J-HMDB-21和UCF101-24上的最新技术成果,分别显着提高了约3%和约12%。我们使我们的代码和预先训练的模型公开可用。
1. 引言
人类行为的时空定位是近年来备受关注的研究课题,其目的不仅是识别行为的发生,而且是对行为在时间和空间上的定位。在这类任务中,与静态图像中的目标检测相比,时间信息起着至关重要的作用。寻找一种有效的策略来聚集空间和时间特征使得这个问题更加具有挑战性。另一方面,实时人体动作检测在众多视觉应用中变得越来越重要,如人机交互(HCI)系统、无人机(UAV)监控、自主驾驶、城市安全系统等。因此,探索一个更有效的框架来解决这个问题是可取的,也是值得的。受卓越的目标检测架构Faster R-CNN[27]的启发,最先进的工作[13,24]将经典的两阶段网络结构扩展到动作检测,在第一阶段产生大量proposals,然后在第二阶段进行分类和定位细化。然而,这两阶段的pipelines在时空动作定位任务中有三个主要的缺点。首先,由跨帧边界框组成的动作管( action tubes)的生成要比二维情况复杂得多,而且耗时。其次,动作建议(action proposals)只关注视频中的人的特征,忽略了人与背景中某些属性之间的关系,而这些关系能够为动作预测提供相当关键的上下文信息。两阶段体系结构的第三个问题是,单独训练区域建议网络和分类网络并不能保证找到全局最优解。相反,只能从两个阶段的组合中找到局部最优。训练成本也比单级网络高,因此需要更长的时间和更多的内存。
在本文中,我们提出了一个新颖的单级框架YOWO (You Only)
观看一次),用于视频中的时空动作定位。YOWO使用单阶段架构避免了上面提到的所有三个缺点。YOWO的直观思想源于人类的视觉认知系统。例如,当我们沉迷于电视前的一部肥皂剧时,每次我们的眼睛都捕捉到一个画面。为了了解每个艺术家正在执行的动作,我们必须将当前帧信息(关键帧中的二维特征)与从存储在内存中的先前帧中获得的知识(片段中的三维特征)关联起来。然后将这两种特征融合在一起,为我们提供一个合理的结论。图1展示了我们的灵感。
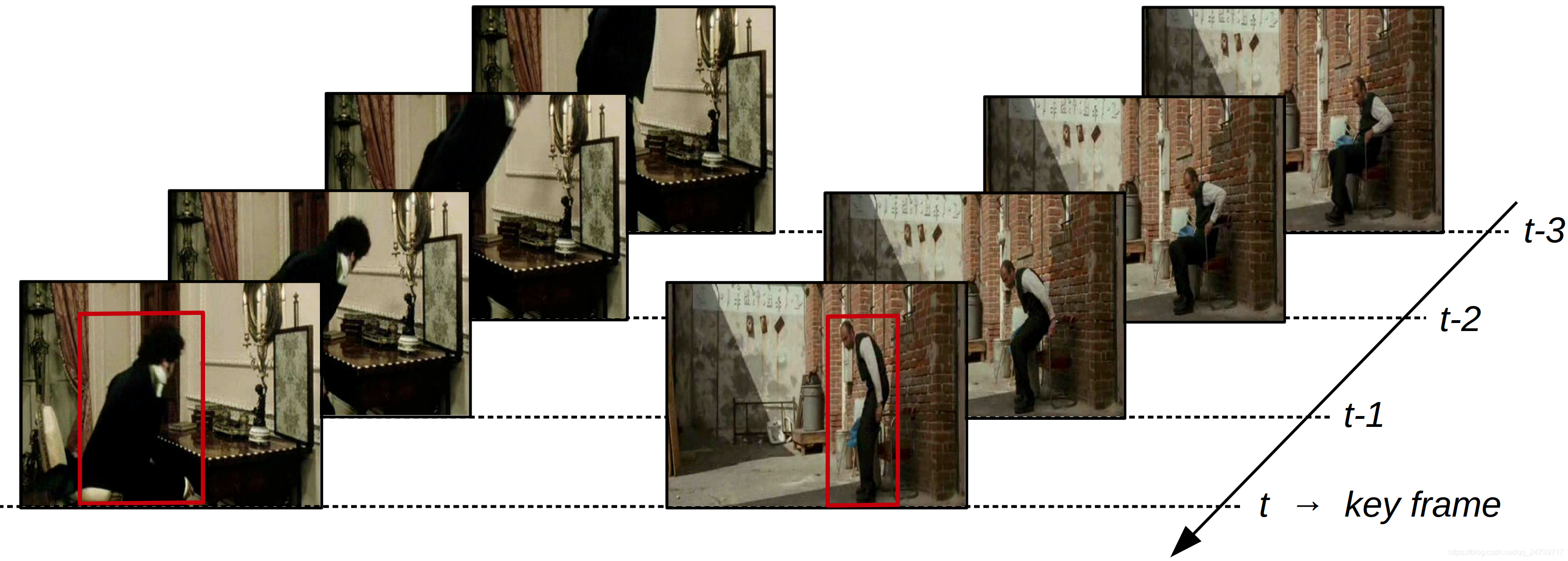 图1
图1
YOWO架构是一个具有两个分支的单阶段网络。一个分支通过2D-CNN提取关键帧(即当前帧)的空间特征,而另一个分支则通过3D-CNN建模由先前帧组成的剪辑的时空特征。 为了平稳地汇总这些特征,使用了一种通道融合和关注机制,在这种情况下,我们最大程度地利用了通道间的依赖性。最后,利用融合后的特征进行帧级检测,并给出一种生成动作管(action tubes)的连接算法。最后,利用融合后的特征进行帧级检测,并给出一种生成动作管的连接算法【应该就是行为预测】。
为了保持实时能力,我们在RGB模式下运行了YOWO。但是,必须指出的是,YOWO体系结构并不局限于仅在RGB模式下运行。在YOWO中可以插入不同的分支以适应不同的模式,如光流、深度等。此外,在其2D-CNN和3D-CNN分支中,任何CNN架构都可以根据所需的运行时性能来使用,这对于实际应用程序非常关键。
本文的贡献总结如下。
- 1.我们提出了一种实时单阶段的视频流时空动作定位框架YOWO,该框架可以端到端的高效训练。据我们所知,这是第一个实现二维CNN和三维CNN同时提取特征以实现边界框回归的工作。这两种特征对于最终的边界盒回归和动作分类具有互补作用。另外,我们使用了一个通道注意机制来平滑地聚合来自上面两个分支的特性。实验证明,基于通道的特征映射机制能够较好地模拟连接后的特征映射的通道间关系,并通过更合理地融合特征显著地提高了映射的性能。
- 2.我们对YOWO结构进行了详细的消融(ablation study)研究。我们研究了3D-CNN、2D-CNN的效果,它们的聚集性和融合机制。此外,我们尝试了不同的3D-CNN架构和不同的剪辑长度,以探索精度和速度之间的进一步平衡。
- 3.我们以J-HMDB-21和UCF101-24基准评估YOWO,并建立新的最新结果,分别在帧mAP方面分别提高3.3%和12.2%。
2. 相关工作
行为识别与深度学习。由于深度学习给图像识别带来了重大的技术进步,近年来大量的研究工作致力于将其扩展到视频中的动作识别中。然而,对于动作识别,除了从每个单独的图像中提取空间特征外,还需要考虑跨这些帧的时间上下文。双流CNN是一种分离提取空间和时间特征并将其聚合在一起的有效策略 [6] [30] [36]。这些工作大部分是基于光流,需要大量的计算能力来提取,这是一个耗时的过程。随着时间的推移,另一种集成CNN特性的选择是实现递归网络,但其性能不如最近基于CNN的方法[42]那么令人满意。近年来,三维cnn在视频分析任务中的应用越来越广泛,它可以同时从空间和时间两个维度学习特征。首先利用3D-CNN来提取[16]中的时空特征,并探讨了一些有效的网络结构,如C3D[34]和I3D[2]。灵感来自于2D-CNN残差网络[40],跨层跳转连接也适用于3D-CNNs解决了[12]梯度消失问题。为了提高资源效率,其他一些研究工作侧重于使用2D- cnn从单个图像中学习2D特征,然后将它们融合在一起,使用3D-CNN[44]学习时间特征。【总结一下,使用3DCNN,使用残差网络有效】
时空行为定位。对于图像中的目标检测,R-CNN系列在第一阶段使用选择性搜索[10]或RPN[27]提取区域建议,在第二阶段对这些潜在区域的对象进行分类。虽然Faster R-CNN[27]在对象检测方面取得了最先进的结果,但由于其耗时的两阶段结构,在实时任务中很难实现。YOLO[25]和SSD[23]旨在将这一过程简化为一个阶段,并具有出色的实时性能。对于视频中的动作定位,由于R-CNN系列的成功,大多数的研究方法都是先在每一帧中检测人类,然后将这些边界框合理地连接成动作管道( action tubes)[11,13,24]。双流检测器在原有的分类器的基础上引入了一个额外的流,用于光学流模态[24][29][32]。其他一些工作产生具有3D-CNN的候选夹管( clip tube),并在相应的3D特征上实现回归和分类[13] [29],因此候选区域对于它们是必要的。在最近的[4]工作中,作者提出了一种用于视频动作检测的三维胶囊网络,它可以联合执行像素级的动作分割和动作分类。但是,由于它是一个基于U-Net[28]的3D-CNN架构,因此在计算复杂度和参数数量上都非常巨大。
注意力模块。注意力是捕获远距离依赖项的有效机制,在图像分类[35][3][39]和场景分割[7]中,注意力被尝试用于CNNs中,以提高图像分类[35][3][39]和场景分割[7]的性能。
3. 方法
在本节中,我们首先详细介绍YOWO的体系结构,它从关键帧中提取二维特征,同时从输入片段中提取三维特征,并将它们聚合在一起。随后讨论了通道融合和注意机制的实现,这提供了必不可少的性能提升。最后,我们描述了YOWO架构的训练过程和改进的边界框连接策略,以生成未剪辑视频中的动作管(action tubes)。
3.1 YOWO框架
YOWO架构如图2所示,它可以分为四个主要部分:3D-CNN分支、2D-CNN分支、CFAM和边界框回归部分。
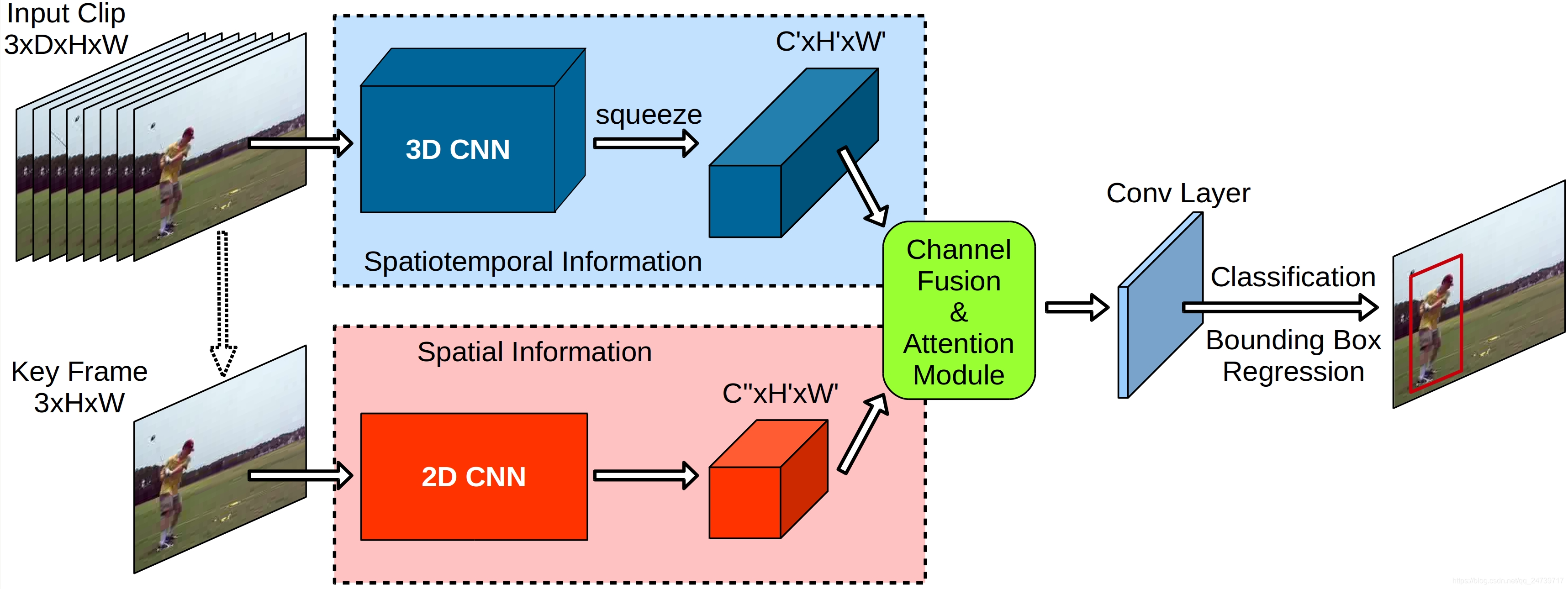
图2.YOWO框架。输入剪辑和相应的关键帧被馈送到3D-CNN和2D-CNN以产生分别为 [ C ′ ′ × H ′ × W ′ ] [C''×H'×W'] [C′′×H′×W′]和 [ C ′ × H ′ × W ′ ] [C'×H'×W'] [C′×H′×W′]的输出特征体积。这些输出量被输入到通道融合和注意机制(CFAM)以实现平滑的特征聚合。最后一个conv层用于调整最终边界框预测的通道号。
3D-CNN分支
由于上下文信息对人类行为理解至关重要,因此我们利用3D-CNN来提取时空特征。三维神经网络不仅可以在空间维度上进行卷积运算,而且可以在时间维度上进行卷积运算来获取运动信息。我们框架中的基本3D-CNN架构是3D-ResNext-101,因为它在Kinetics数据集中具有很高的性能[12]。除了3D-ResNext-101,我们还在消融研究中尝试了不同的3D-CNN模型。对于所有3D-CNN架构,最后一个conv层之后的所有层都将被丢弃。3D网络的输入是视频片段,该视频片段按时间顺序由一系列连续的帧组成,形状为 [ C × D × H × W ] [C×D×H×W] [C×D×H×W],而3D ResNext-的最后一个conv层 101输出形状为 [ C ′ × D ′ × H ′ × W ′ ] [C'×D'×H'×W'] [C′×D′×H′×W′]的特征图。其中 C = 3 C = 3 C=3, D D D为输入帧数, H H H和 W W W为输入图像的高度和宽度,C’为输出通道数, D ′ = 1 D' = 1 D′=1, H ′ = H / 32 H' = H/32 H′=H/32, W ′ = W / 32 W' = W/32 W′=W/32。为了匹配2D-CNN的输出特征图,将输出特征图的深度维数减少到1,将输出体积压缩到 [ C ′ × H ′ × W ′ ] [C' × H' ×W'] [C′×H′×W′]。
2D-CNN分支
同时,为了解决空间定位问题,并行提取关键帧的二维特征。我们在2D CNN分支中采用Darknet-19 [26]作为基本架构,因为它在准确性和效率之间取得了很好的平衡。形状为 [ C × H × W ] [C×H×W] [C×H×W]的关键帧是输入剪辑的最新帧,因此不需要额外的数据加载器。Darknet-19的输出特征图的形状为
[ C ′ ′ × H ′ × W ′ ] [C'' ×H' ×W'] [C′′×H′×W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









