




文章目录
AI Coding之SWE-bench
AI Coding方向的Benchmark(基准测试)
Benchmark 是什么?
Benchmark(基准测试)是评估AI系统或模型性能的一种标准化测试方法,通常呈现出来的是一组测试内容。它通过使用预定义的数据集、任务和评估指标,对AI模型在特定任务上的表现进行量化评估,以便比较不同模型之间的性能差异。
简单来说,可以把各个大模型当作学生,那么 Benchmark 就是各类考试,如高考和数学竞赛等。
Benchmark 测评内容”分为五个主要维度:自然语言处理(NLP)、编码能力(Coding)、视觉多模态能力(Multimodal)、智能体能力(Agent)、鲁棒性(Robustness)。每个维度下又细分若干具体能力或子任务。这反映出评估大型模型/AI 系统时,需要从多方面、多任务、端到端地考察其实际能力。
Benchmark 里,有两个是跟 AI Coding Agent 表现强相关的:
什么是SWE-bench?
可以在 swebench.com 找到完整的排行榜!
大语言模型(LLM)在软件开发领域展现出了惊人的潜力。为了客观地衡量它们的能力,基准测试变得不可或缺。其中,SWE-bench已成为一个黄金标准,它通过评估模型解决真实世界GitHub问题的能力来进行测试。
SWE-bench(Software Engineering Benchmark)是一个专门用于评估大型语言模型或 AI 编码智能体在真实软件工程任务上能力的基准测试集合。SWE-bench 是为了衡量 AI 在“真实软件工程”场景下的端到端能力而设计的 benchmark。
SWE-bench 是由普林斯顿大学 NLP 团队开发的项目,23年10月就开始提出,主要是想找到一种方式可以评估大模型解决实际软件工程问题的能力,而不是像之前只衡量算法题的解决能力。当时还是 Claude 2 和 GPT4 的时代,随着 AI Coding 的逐渐火爆,OpenAI 也加入对这个 benchmark 的完善,这个项目也逐渐成为主流。
SWE-bench 提供:
- ✅ Real-world GitHub issues - Evaluate LLMs on actual software engineering tasks✅ 真实的 GitHub 问题 - 在实际软件工程任务上评估 LLM
- ✅ Reproducible evaluation - Docker-based evaluation harness for consistent results✅ 可复现的评估 - 基于 Docker 的评估工具,以获得一致的结果
- ✅ Multiple datasets - SWE-bench, SWE-bench Lite, SWE-bench Verified, and SWE-bench Multimodal✅ 多个数据集 - SWE-bench, SWE-bench Lite, SWE-bench Verified, 和 SWE-bench Multimodal
“Bash Only”类别Benchmark排行榜
官方文档:https://www.swebench.com/bash-only.html
可以在 swebench.com 找到完整的排行榜!
AI Coding Agent: SWE-bench深度解析, 为何简单的Bash环境是AI程序员的终极试炼场
原文链接:https://blog.youkuaiyun.com/qq_14829643/article/details/151755591
传统的代码生成基准测试通常关注“函数级别”的问题——编写一个特定的算法或完成一个定义明确的小代码片段。这虽然有用,但并未捕捉到完整的软件开发生命周期。
真实的软件工程远不止于此:它需要理解一个复杂的现有代码库、浏览文件结构、运行测试以复现一个错误、形成一个修复假设、实施修复,并验证这个修复没有引入新的问题。SWE-bench通过使用来自流行开源项目的真实问题,将这整个过程囊括其中。一个智能体的任务不仅仅是写代码,而是在一个真实的项目环境中从头到尾解决一个问题。
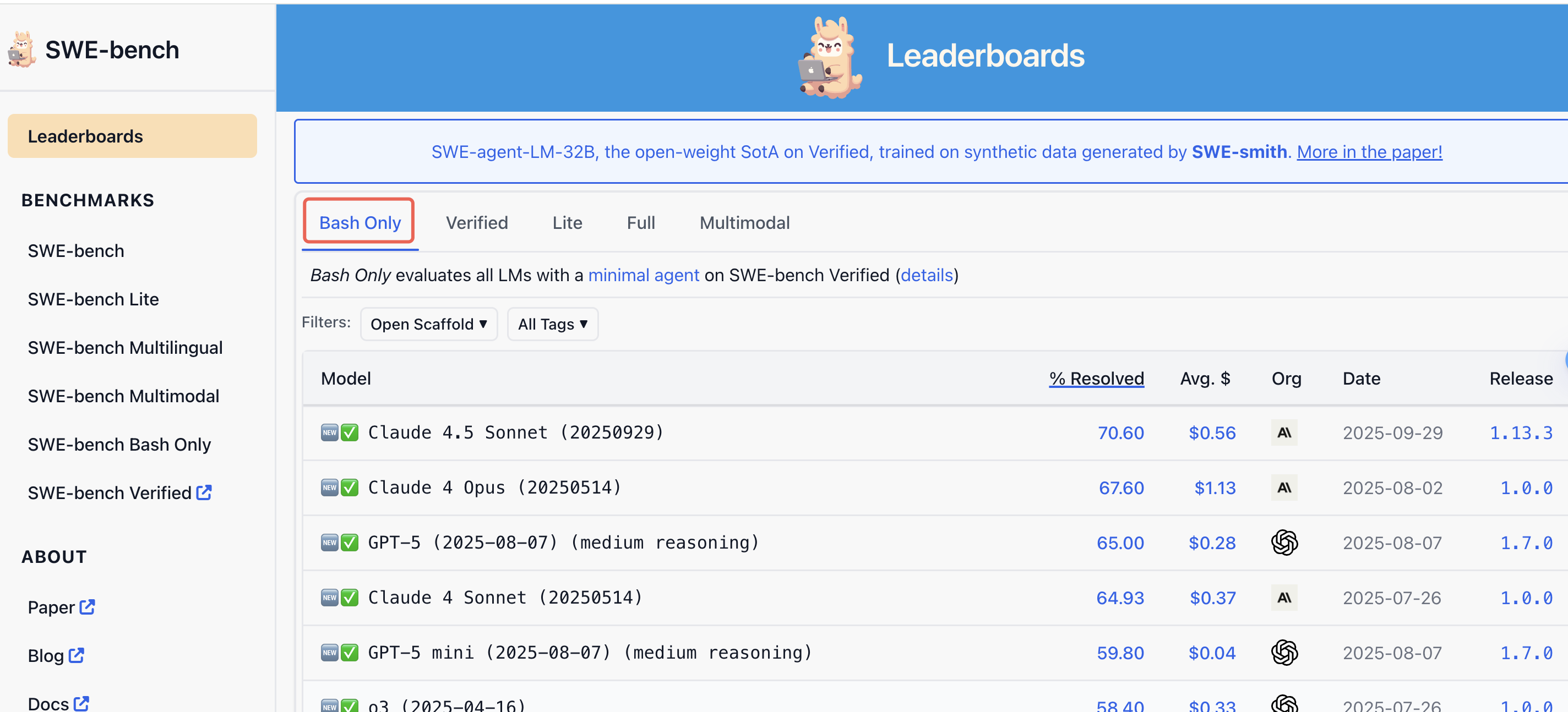
尽管SWE-bench上的“Full”(完整环境)或“Multimodal”(多模态)等类别指向了功能强大、工具丰富的AI智能体的未来,但**“Bash Only”类别的重要性依然不可动摇。它的流行并非因为任务简单,而是源于评估的清晰与纯粹。它剥离了噪音,衡量了真正重要的东西:LLM在软件开发情境中固有的推理、规划和行动能力。它作为一个公平、可复现且基础的基准**,通过提供一个关于模型核心软件工程智能的纯粹信号,推动了整个领域的进步。对于任何希望了解AI程序员真实能力的开发者或研究者来说,“Bash Only”排行榜在当下乃至未来,都可能是他们最应该首先关注的地方。
“Bash Only”排行榜建立了一个至关重要的基线。它回答了这样一个问题:“一个顶尖的模型,在使用最基础的工具集时,能表现得多好?”
SWE-bench Bash Only uses the SWE-bench Verified dataset with the mini-SWE-agent environment for all models [Post].
排行榜上明确强调的两个词:最小智能体(minimal agent)。该类别使用一个被刻意限制的智能体来评估LLM。它与代码仓库交互的唯一工具,就是一个标准的Bash Shell。
这意味着智能体无法依赖于功能丰富的集成开发环境(IDE),比如“跳转到定义”、交互式调试器或图形用户界面。它的每一个动作——从列出文件(ls)、读取代码(cat)、搜索特定文本(grep),到应用变更(sed或生成补丁文件)——都必须通过纯文本命令来完成。这种限制并非对任务的简化,恰恰相反,它是对评估过程的一次提纯。
这种最小智能体方法的主要好处在于,它隔离了LLM本身的核心推理和规划能力。当一个智能体使用一套复杂的工具时,它的成功可能是模糊的。高分究竟是源于模型的智能,还是源于其外部工具链的精巧工程?
通过剥离这些外部辅助,“Bash Only”基准测试迫使LLM依赖其最基本的能力。模型必须:
- 制定计划: 将问题分解为一系列逻辑步骤。
- 展现工具熟练度: 知道使用哪些Bash命令,以及如何将它们组合起来探索代码库并诊断问题。
- 综合信息: 解读命令的文本输出(stdout和stderr),为下一步行动提供信息。
本质上,这是在开发者最基础的环境中,对模型原始问题解决能力的终极考验。在这一类别中取得成功,有力地表明该模型具备了真正的软件工程智能,而不仅仅是善于使用高级辅助工具。
Bash Shell是通用的。这就创造了一个公平的竞争环境,研究人员和开发者可以轻松地测试他们的模型,并相信结果是可比的。
数据构造
分三步:

- **选靠谱的库:**选了 12 个流行的 Python 开源库,选择的标准是,热门库,长期维护,有比较多的 Pull Request 修复相关 issue,PR 的管理也很规范,有很好的测试覆盖率。这些库修复 issue 的 PR 就是我们要获取的测试 case,但会对这些 PR 进行一些过滤。
- **特性过滤:**1)明确 PR 是解决了某个特定问题。2) PR里包含了测试 case,可以很容易从测试 case 上判断代码修改是否有效。这些在运行前就能过滤出来。
- **运行时过滤:**这些 PR 应用前后,测试用例中要有明确的从不通过到通过的变化,程序跑起来也不会有错误,便于评估结果。
基于上述规则从 github 热门项目上抽取相关的数据,这些数据还可以持续更新,避免模型因为看到过这些数据而“作弊”。
经过上述步骤抽取构造数据后,得到 SWE-Bench 数据集,后来 OpenAI 对这个数据集再进行人工过滤筛选掉了一些不太好的 case,比如 issue 问题描述不准确、开发环境难搭建难测试等,也对每个挑选的 case 做了精心人工验证,一共500个样本,组成 SWE-bench_Verified 数据集,现在一般测的是这个数据集。
来看看这个数据集具体都由哪些部分组成:
instance_id: 实例ID,通常格式为 repo_owner__name-PR-number
//代码基本信息
repo: 仓库名
base_commit: PR 提交之前的代码 commit id,定位代码基线
version: 用于运行的版本号
environment_setup_commit: commit id,安装运行环境的代码基线
created_at: PR 创建时间
//PR基本信息
problem_statement: PR 对应的 issue 内容,也就是要解决的问题
test_patch: 这个 PR 提交的测试 case patch 代码
FAIL_TO_PASS: 应用修复的 PR 后会通过的测试 case
PASS_TO_PASS: 应用 PR 前和应用后,都应该通过的测试 case
patch: 这个 PR 修复的 patch 代码,相当于标准答案
hints_text: PR 提交之前,github 上对这个 issue 的讨论 comment。可选,如果要上榜单,禁止使用这个数据。
代码信息、问题描述、测试用例,重点是这几个,剩下的都是用于把程序跑起来、验证修复结果用。
SWE-bench 生态系统的项目
swe-agent
swesmith
swe-rex
sb-cli
mini-swe-agent
SWE-bench和SWE-agent是由[John Yang]于2024年在普林斯顿大学发起的开源项目。
该项目推动了基于大型语言模型的软件工程agent(Software Engineering Agent)研究。
其中,SWE-bench一经发布后,就成为了评估大语言模型编程的经典benchmark,伴随SWE-agent一同提出的Agent‑Computer-Interface(ACI)则进一步定义了“智能体如何与计算机交互”的标准接口方式。
而这一杰出的想法最初仅仅来自一次20多分钟的讨论。
在Matthew Berman的播客节目上,Carlos E. Jimenez分享道:SWE-bench最初的想法源自他和John Yang在闲逛时的一次头脑风暴。
他们意识到,GitHub不只是一个存储代码的地方,更是一个活跃的协作开发平台,充满了真实的软件工程过程:用户报告bug,开发者提交修复,社区公开审核和合入。
相比传统的编程竞赛,这些交互和修改才是真正代表“现实世界编程”的任务。于是他们设想,能否把这种开源协作的过程结构化下来,变成一种评估语言模型能力的标准流程?
这便催生了SWE-bench,一个基于GitHub上真实Issue与PullRequest构建的benchmark,用来测试LLM是否能像人类开发者一样,理解bug报告并修复代码。
这个系统不仅更接近现实,也让模型的“开发能力”变得可观察、可比较,而SWE-agent则是他们为这一评估任务设计的开源agent,目标就是成为能在SWE-bench上“修最多bug”的AI程序员。
mini-swe-agent
官网:https://mini-swe-agent.com/
SWE-bench、SWE-agent原班人马再出手,推出全新开源项目——mini-SWE-agent
它不依赖任何额外插件,仅通过基础命令即可运行。而且对模型没有限制,几乎兼容所有主流语言模型,支持直接在本地终端中部署和使用。
SWE-agent是一个开源项目(16.8k GitHub Star),它的目标是让agent自动修复GitHub上真实项目中的代码Bug。
不过,原版的SWE-agent基于[LangChain]构建,从接受issue、理解问题、编辑代码、到提交PR,涉及多工具、多轮对话管理,任务流程繁琐。
除此之外,开发者要跑通还需要安装多个依赖,精调工具调用逻辑,而且项目代码动辄上千行,对模型、环境的耦合也比较强。
而随着语言模型性能越来越强大,构建一个有用的agent已经不再需要这些工具和接口了。
mini-SWE-agent由此而来。
相较于SWE-agent,mini-SWE-agent有什么不同呢?
极简代码和依赖:mini-SWE-agent本身仅约100行Python代码,加上环境、模型、脚本才共约200行,没有复杂的依赖关系。
取消工具调用接口:mini版本不集成专用的代码编辑、搜索等工具;它只使用操作系统的Bash环境执行命令。每一步由语言模型输出一个完整的shell命令,不通过独立的“tool call”协议,从而可兼容任何语言模型。
线性历史记录:agent的每一步都只是附加到消息中。
**独立单步执行:**每条命令通过Python独立执行,并非保持一个持续的shell会话,这使得在沙盒中执行操作变得非常简单,并且可以轻松扩展。
简化配置与接口:取消了SWE-agent依赖的复杂YAML配置;mini-swe-agent采用代码内置模板,并提供直观的命令行工具。用户可以通过mini命令快速启动agent,或使用mini-v启动可视化界面。
多样的运行环境支持:除了本地Shell,mini-swe-agent还内置支持多种容器与虚拟化环境(如[Docker],这意味着开发者可以在不同平台和容器中轻松部署,而无需额外修改代码。
此外,对于应在何种场景下使用 SWE-agent 或 mini-SWE-agent,团队也根据不同的需求给出了建议:
mini-swe-agent更适合希望快速本地运行、追求简洁控制流和更稳定评估环境的用户。它非常轻量,适合用于微调(FT)或强化学习(RL)等实验,不容易陷入对复杂框架的过拟合。
如果你需要高度可配置的工具链、更复杂的历史状态管理,或希望通过修改YAML文件自由切换组件而无需动代码,那么功能更丰富的SWE-agent会是更合适的选择。
总体而言,mini-swe-agent体现了可读、方便、易扩展的开发理念。
对于日常开发者而言,它既可以作为简单的命令行工具使用。如在本地终端快速解决问题),也可以作为库被集成到其他Python应用中。
相比于重型框架,它降低了上手成本,让开发者可以像使用脚本一样灵活地“驾驭”智能代理。
其他参考
细看 Claude 3.7 两个重要的 Benchmark:SWE-Bench & TAU-Bench
原文链接:https://blog.cnbang.net/tech/4178/
大模型竞技场生存指南:当我们在谈论 Benchmark 时到底在比什么?
原文链接:https://zhuanlan.zhihu.com/p/1911745989020223159



















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











