




大家可能都有这样的经历,刚入职一家企业时,同事往往会给你分享一些文档资料,有可能是产品信息、规章制度等等。这些文档有的过于冗长,很难第一时间找到想要的内容。有的已经有了新版本,但员工使用的还是老版本。
基于这种背景,我们可以利用 Easysearch 加 LLM 实现一个内部知识的 QA 问答系统。这个系统将利用 LangChain 框架调用本地部署的大模型和 Easysearch,实现理解员工的提问,并基于最新的文档,给出精准答案。
开发框架
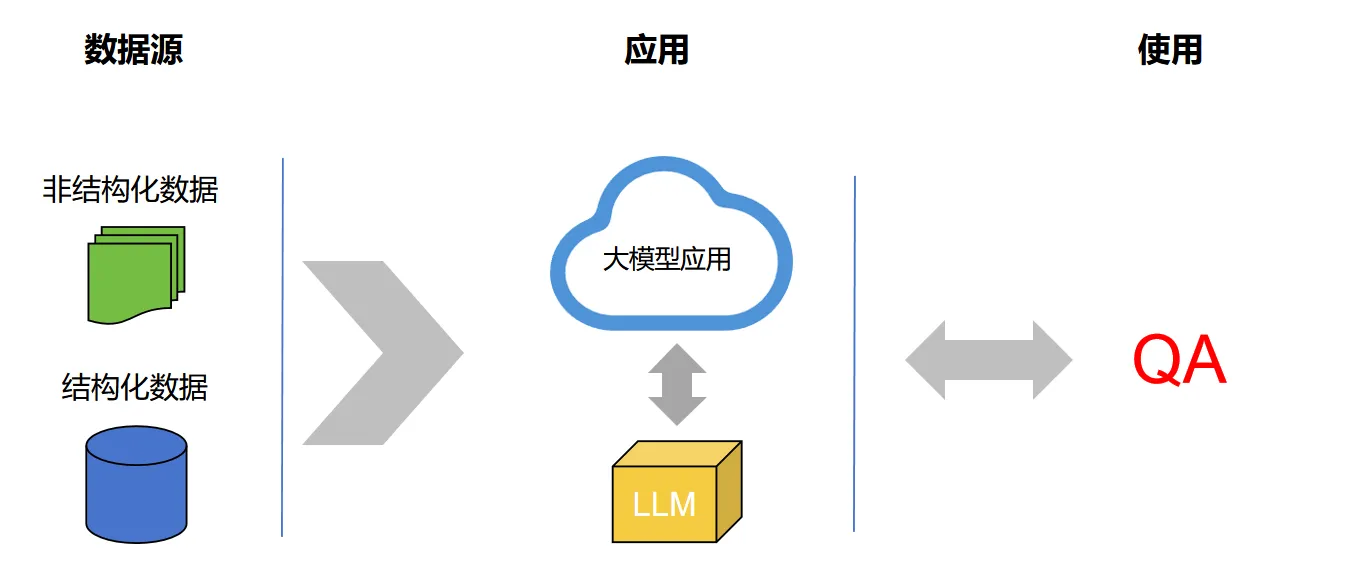
整个框架分为四个部分:
- 数据源:数据可以有很多种,可以是非结构化的,比如 PDF、docx、txt 等。也可以是结构化的数据,甚至代码也行。在本次示例中,我们使用 PDF 的非结构化数据。
- 大模型应用:应用与大模型交互,生成我们需要的答案。
- 大模型:系统执行相关任务需要用到的大模型,可以有多个。
- Q&A 场景:基于大模型为引擎的 QA 场景,使用 web 框架,构建一个交互界面。
数据准备
本次我们使用的资料是 “INFINI 产品安装手册.pdf” ,文档部分内容展示如下:

首先我们使用 LangChain 的 document_loaders 来加载文件。document_loaders 集成了数百种数据源格式,可以很方便的加载数据。我们的数据的 pdf 格式的,导入 PyPDFLoader 类来进行处理。代码如下:
import os
# 导入 Document Loaders
from langchain_community.document_loaders import PyPDFLoader
# Load Pdf
base_dir = '.\\easysearch' # 文档的存放目录
docs = []
for file in os.listdir(base_dir):
file_path = os.path.join(base_dir, file)
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
上面的代码将 pdf 文件的内容存储在 docs 这个列表中,以便后续进行处理。
文本分割
一个文件的文本内容可能很大,无法适应许多模型的上下文窗口,也不利于检索和存储。因此,通常我们会将文本内容分割成更小的块,这将帮助我们在运行时只检索文档中最相关的部分。LangChain 提供了工具来进行处理文本分割,非常方便。
我们将把文档分割成 1000 个字符的块,每个块之间有 200 个重叠字符。这种重叠有助于减少将语
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









