



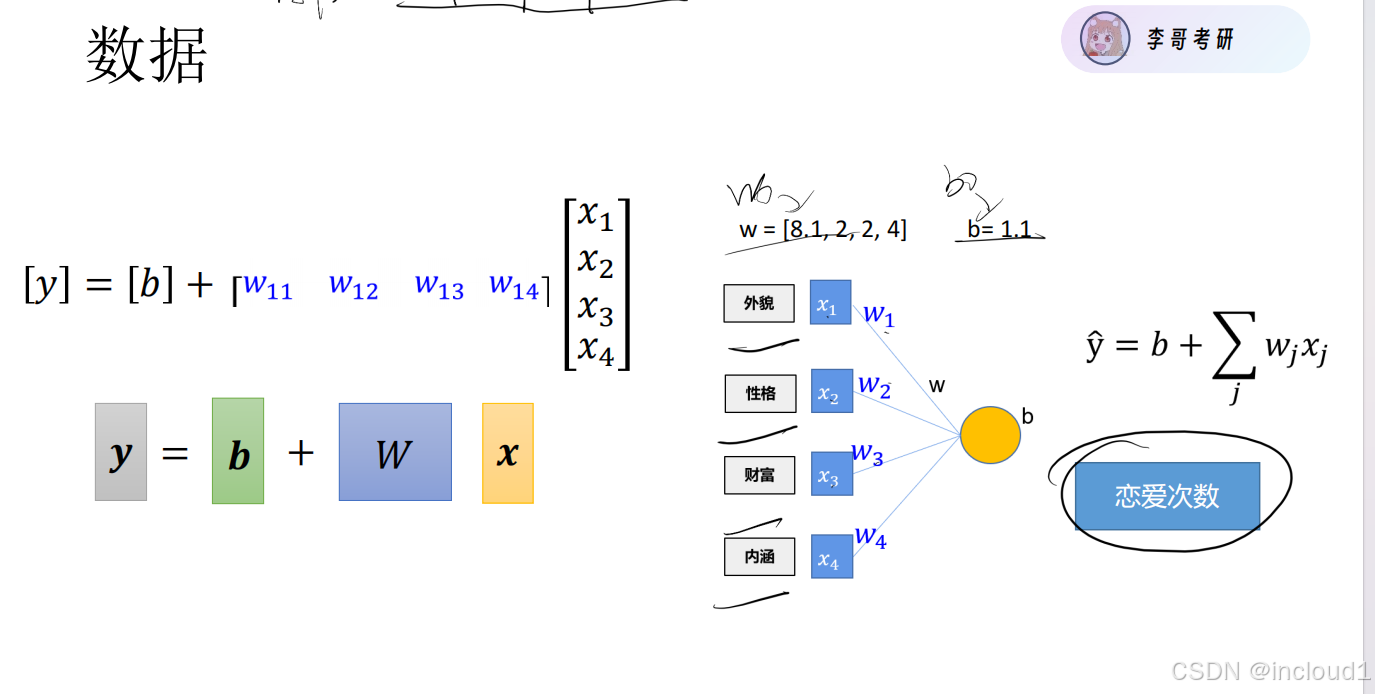
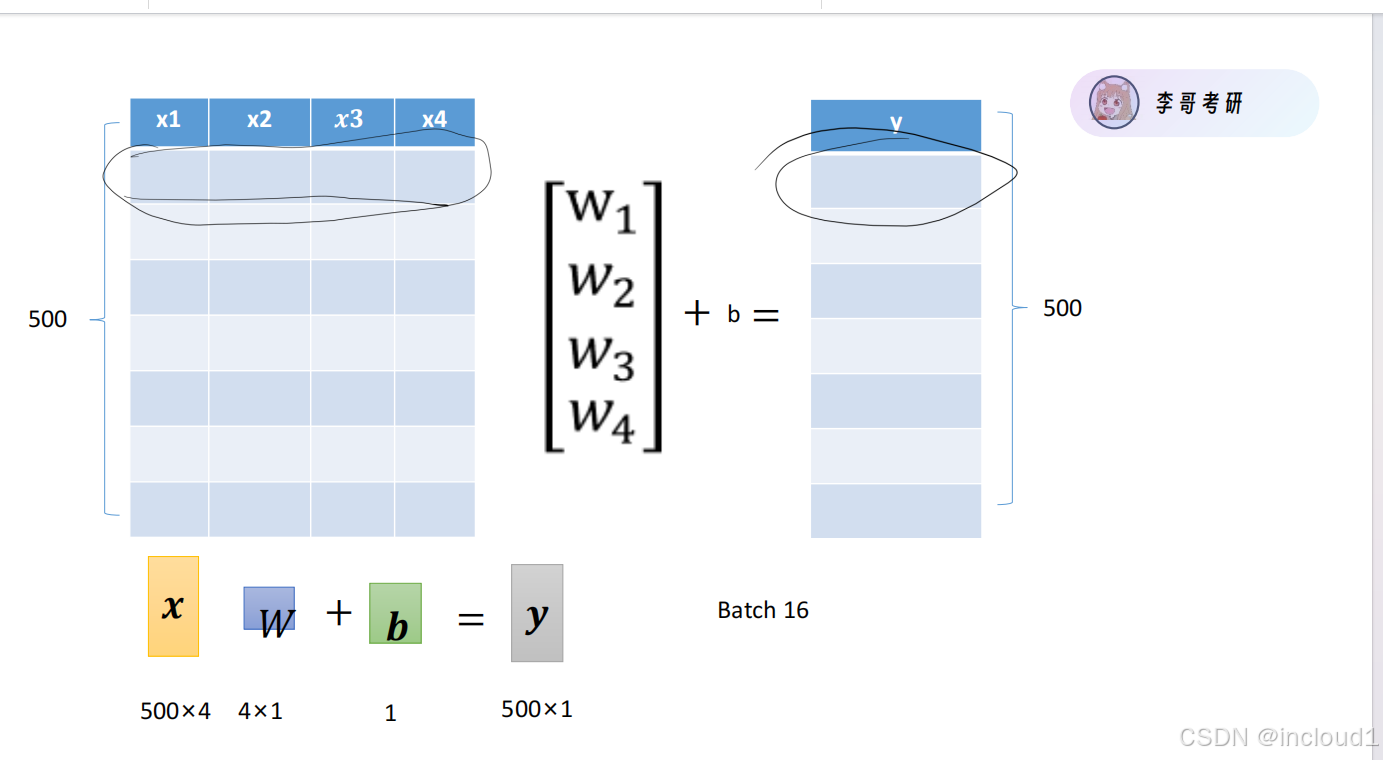
一.初始数据的生成:
初始样本x为500*4的矩阵,利用torch.normal生成服从正态分布的样本,标签y = xw + b,y为500*1的矩阵,利用torch.normal生成随机噪声,参数w和b人为设置。
# 1.生成数据
def create_data(w, b, data_size):
x = torch.normal(0, 1, (data_size, len(w)))
y = torch.matmul(x, w) + b
# 噪声
noise = torch.normal(0, 0.01, y.shape)
y += noise
return x, y
size = 500
true_w = torch.tensor([8.1, 2, 2, 4])
true_b = torch.tensor(1.1)
X, Y = create_data(true_w, true_b, size)
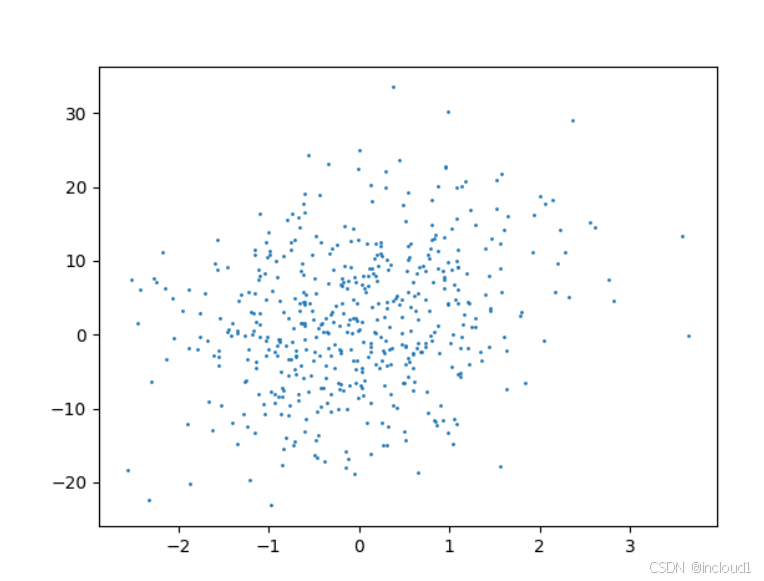
可视化:
需要注意此处的X为500*4的矩阵,因此需要手动指定某个变量,此处的下标是2,也就是x3
plt.scatter(X[:, 2], Y, 1)
plt.show()
二.将数据分批次
设置batch_size=16,并将数据打乱(打乱的作用是破坏原有数据数据之间的相关性,提高模型的泛化能力),数据分成多个小的批次而不是一次性是可以保证每次使用较少的资源并且不占用过多的内存,充分利用GPU进行训练。
# 数据提供
def data_provider(feature, label, batch_size):
length = len(label)
indices = [i for i in range(length)]
# 打乱下标,不按照顺序取
random.shuffle(indices)
# 按批次获取数据
for i in range(0, length, batch_size):
get_indices = indices[i:i + batch_size]
get_data = feature[get_indices]
ger_label = label[get_indices]
yield get_data, ger_label # 有存档点的return
三.自定义初始模型,对数据进行预测
# 自建模型
def predict(x, w, b):
return torch.matmul(x, w) + b
四.计算损失函数
# 计算损失函数
def get_loss(pred_y, y):
return torch.sum(abs(pred_y - y)) / len(pred_y)
五.对模型进行训练,更新参数
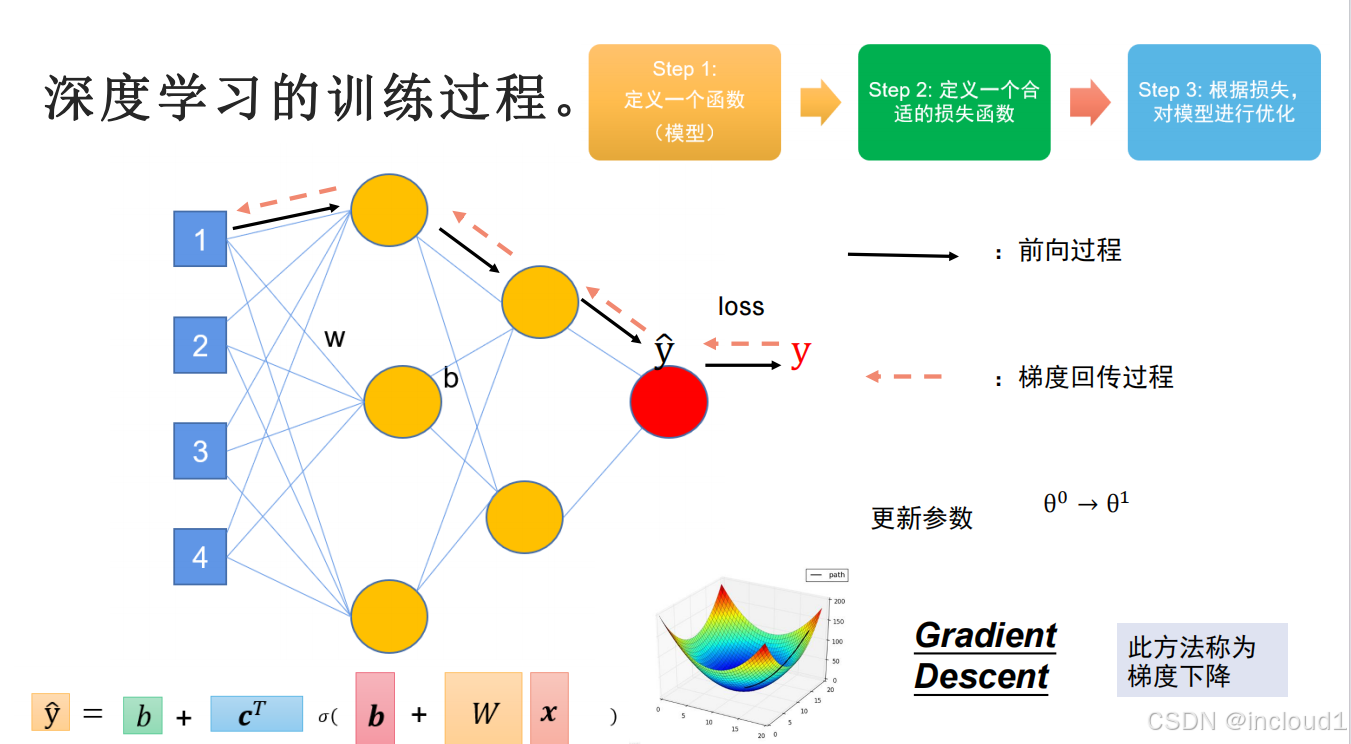
人为设置初始的参数w_0和b_0,采用随机梯度下降,前向过程计算出预测值pred_y,loss = |y - pred_y|,初始时所有参数中保存的grad梯度为0,利用反向传播backward()可以得到每个参数的梯度,并对每个参数进行更新w = w-η*grad,b = b-η*grad,最终找出合适的w和b。
注意:由于在张量网上的任何计算都会计算梯度,因此当我们不需要计算梯度时,需要使用with torch.no_grad(),该模型中只需要计算loss对参数的梯度,在更新参数时不需要计算梯度。并且由于pytorch默认在每次backward()后会进行梯度积累,因此需要手动进行梯度清0。
# 随机梯度下降,更新参数
def sgd(params, lr):
# loss是在前向计算时得到的,反向传播时计算各个参数的梯度,随后利用学习率和参数的梯度对参数进行更行,然后需要将梯度清0以防止梯度积累,然后利用新的参数再次预测
with torch.no_grad():
for param in params:
param -= lr * param.grad # 不能协程param = param-lr * param.grad
param.grad.zero_()
w_0 = torch.normal(0, 0.001, true_w.shape, requires_grad=True)
b_0 = torch.tensor(0.01, requires_grad=True)
lr = 0.01
epochs = 50
for epoch in range(epochs):
data_loss = 0
for my_x, my_y in data_provider(X, Y, batchsize):
pred_y = predict(my_x, w_0, b_0)
loss = get_loss(pred_y, my_y)
loss.backward() # 反向传播,计算各个参数的梯度
data_loss += loss
sgd([w_0, b_0], lr)
print("epoch %03d : loss:%.6f" % (epoch, data_loss))
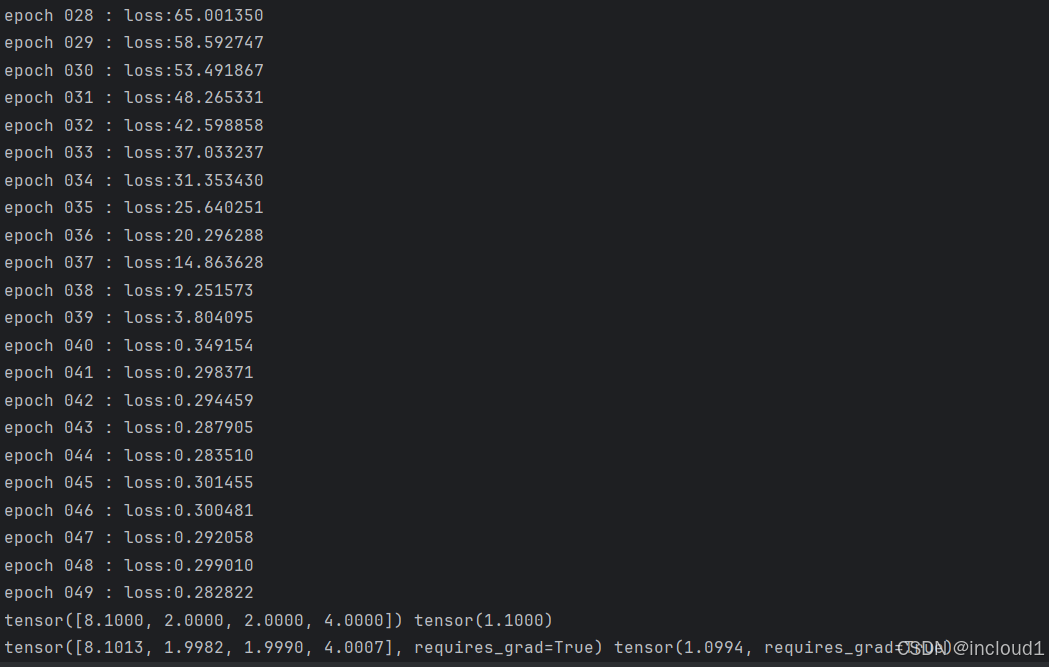
print(true_w, true_b)
print(w_0, b_0)
训练结果:
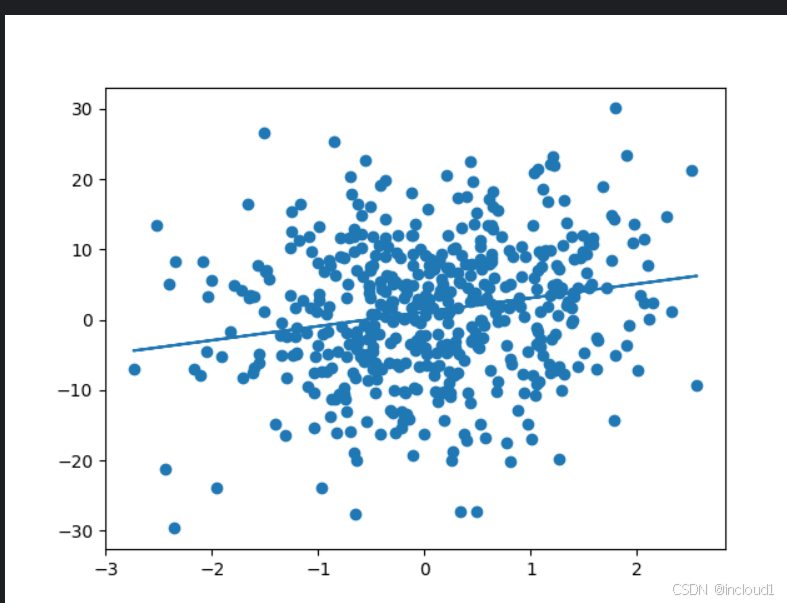
可视化:
本次需要绘制的X和Y位于计算图中,需要使用torch.detach().numpy()将其转化为numpy类型才可以画图。
idx = 1
plt.plot(X[:, idx].detach().numpy(), X[:, idx].detach().numpy() * w_0[idx].detach().numpy() + b_0.detach().numpy())
plt.scatter(X[:, idx].detach().numpy(), Y.detach().numpy())
plt.show()

















 2848
2848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









