









目录
①为什么是struct Node* next;而不是int* next;
1.链式存储的特点
逻辑(通过指针实现)上相邻,物理上可相邻可不相邻
优点:操作灵活,增删效率比较高
缺点:不方便查找,不支持随机存取
2.结点(节点都可以)
| 4(&8) | 8(&6) | 6(&1) | 1(&9) | 9(NULL) |
4后面存上8的地址 8后面存上6的地址 6后面存上1的地址 1后面存上9的地址 9后面存上空地址
也就是说,在链表中,需要存储:数据本身+下一个数据的地址,大体结构如下:
| 数据域 | 指针域 (下一个结点的地址) |
而上面列表所构成的整体也被称作结点(Node)
而后面的代码示例的数据类型我们均以int为例,方便理解
typedef struct Node {
int data; //该节点的数据
struct Node* next;
}Node,*LinkList;这里有几个需要注意的小点:
小细节
①为什么是struct Node* next;而不是int* next;
因为在我们的指针域中,存储的是下一个结点的地址,而不是下一个数据的地址。因为在结点中既包含数据又包含指针域,只有这样才能将一个又一个的结点串起来。
要是这么说不能够理解,我们也可以换一种想法,此时我们的示例中只有一个数据,要是该链表再复杂一些,有100个数据,难道我们要定义100个指针吗?显然是不可能的,而存储下一个结点则可以有效避免这个问题。
②Node和*LinkList之间的联系
LinkList等价于Node*,我们可以看下面声明的两个变量
LinkList p;
Node* q;这里的p和q都是结构体指针,他们的类型相同,而LinkList* x则是一个二级指针,等价于Node** x
③为什么使用*LinkList
为了增强代码的可读性,关于这一点我们稍后会去重点强调
④一个结点占多少字节
typedef struct Node {
int data; //该节点的数据
struct Node* next;
}Node,*LinkList;还是以这个为例分析(64位系统)
int 型变量占4个字节,因为struct Node* next; 是一个指针,只要是指针,无论这个指针是什么类型,都是占8个字节,所以一共占12个字节
⑤由结点组成的链表在内存中是什么样的
以下面这个为例:
| 4(&8) | 8(&6) | 6(&1) | 1(NULL) |

注意:0x表示该数是十六进制,本身没有数值含义
从图中可以看出,他们的物理位置是不相邻的,但是逻辑上通过指针相邻。但是图中还有一个问题,头节点如何表示?
这个时候我们用Node *L去指向头结点。

注意,在本质上,L是指针的名字,而不是链表的名字,而为了方便称呼,我们需要给链表起名,而为了增强程序的可读性,所以我们在定义结构体的时候,多一个*LinkList,所以我们在这里做一些小改动。这也就回答了③为什么使用*LinkList的问题
在这里我们又引入了几个新的概念
3.头指针
保存结点中第一个结点的地址的指针(上个案例中L是头指针),并以头指针的名字命名整个链表
4.首元结点
链表中第一个保存实际数据的结点
在我们对该链表进行修改时回存在一个问题:如果在4的前面 插入数据会使头结点发生改变 ,所以我们可以在4的前面添加一个不保存数据的结点,而头指针的位置也随之改变

而我们给这个不存实际数据(或者称作脏数据)的元素也起一个名字:头结点
5.头结点(可有可无)

不过这两种方法(带头结点和不带头结点)都是可以的。如果是带头结点的链表,头结点的指针域保存首元结点的地址,数据与不用(也就是浪费掉的),目的是使得首元结点的操作与后面的结点统一起来。
知识点补充:
如果我们申请一块空间但是没有赋值,但是这块空间也是有数据的
注意头指针、头结点、首元结点的关系
头指针指向头结点× (需要前提条件:是否有头结点)
头指针指向首元结点×
6.具体操作(代码)
6.1初始化一个空链表(带头结点)
//初始化一个带头结点的空链表
LinkList InitLinkList() {
Node* s = (Node*)malloc(sizeof(Node));//申请头结点
if (s == NULL) {
printf("空间分配失败\n");
}
else {
//s->data 脏数据,不用管
s->next = NULL;
}
return s;
}
int main() {
LinkList L = NULL;
L = InitLinkList();
}(不带头结点)
int main() {
LinkList L = NULL;
}6.2增删改查
①增
解释:
添加一个数据,申请一个新的结点,把数据放在该结点的数据域中,再把这个节点插入到链表中
分类:
Ⅰ)头插法:
每次在首元节点的前面插入一个数据(结点)
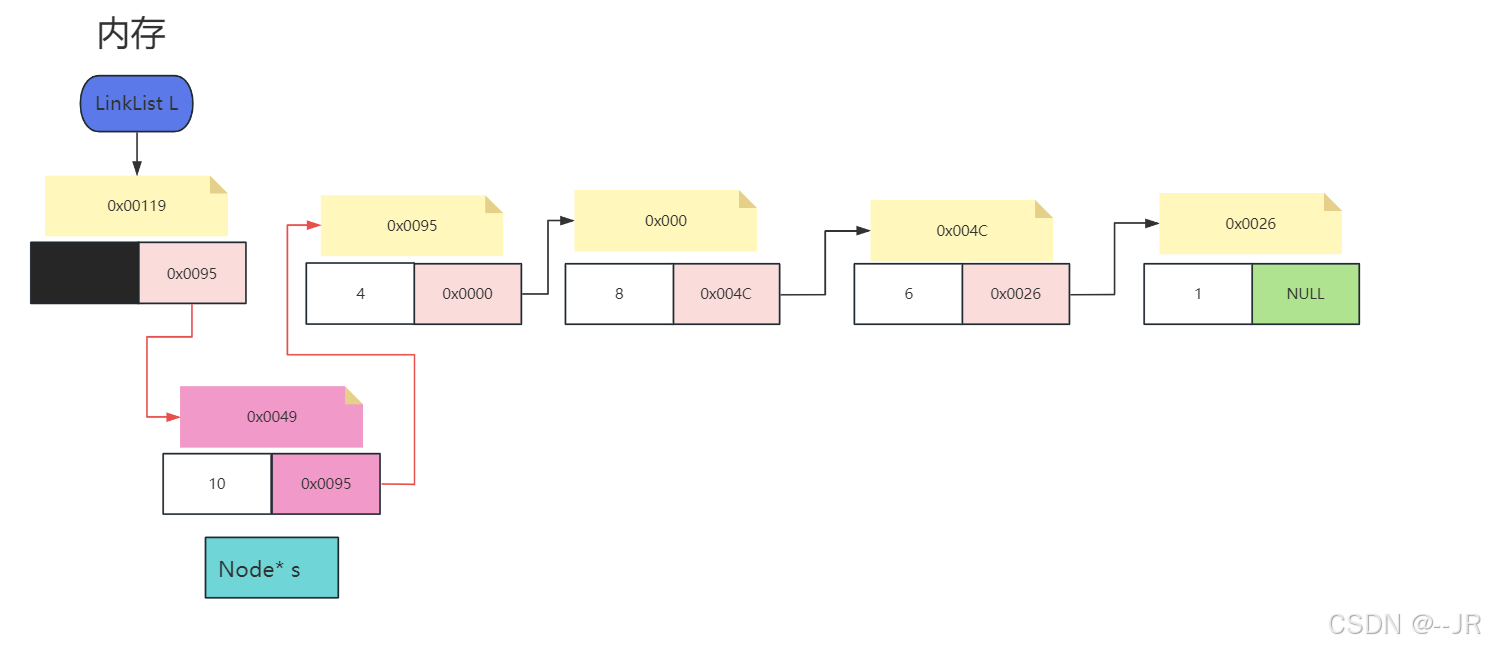
代码实现:
//头插法:
LinkList HeadInsert(LinkList L, int k) {
//先申请一个新的结点用来保存数据k
Node* s = (Node*)malloc(sizeof(Node));
if (s == NULL) {
printf("空间分配失败/n");
return L;
}
else {
s->data = k;//将数据传给新申请的结点s
s->next = L->next;
L->next = s;
}
return L;
}
//主函数
int main() {
LinkList L = NULL;
L = InitLinkList();
L = HeadInsert(L, 10);
}Ⅱ)尾插法:
每次在最后一个节点的前面插入一个数据(结点),这时我们需要遍历查找尾结点的位置,尾结点的位置特点:指针域为NULL
//尾插法
LinkList RearInsert(LinkList L, int k) {
Node* p = L; //指针指p向头结点
while (p->next != NULL) {
p = p->next;
}
//循环结束后指针p指向最后一个结点
//先申请一个新的结点用来保存数据k
Node* s = (Node*)malloc(sizeof(Node));
if (s == NULL) {
printf("空间分配失败/n");
return L;
}
else {
s->data = k;//将数据传给新申请的结点s
s->next = NULL;
p->next = s;
}
return L;
}
Ⅲ)中间插入:
在链表中指定的某个数据之后插入一个数据(结点)
//中间插入
//首先需要一个查找函数,并且返回该结点的地址
Node* find(LinkList L, int k) {
Node* p = L->next;
while (p!=NULL && p->data != k) {
//出现NULL->data!=k会报错,所以这两项的顺序不可以颠倒
p = p->next;
}
return p;//要么为空,要么保存所要数据
}
//中间插入的函数
Node* MidInsert(LinkList L, int x, int k) {
//在元素x后面插入数据k
Node* p = find(L, x);
if (p == NULL) {
printf("数据%d不存在\n,插入失败",x);
return L;
}
Node* s = (Node*)malloc(sizeof(Node));
if (s == NULL) {
printf("空间分配失败,插入失败\n");
}
else {
s->data = k;
s->next = p->next;
p->next = s;
}
return L;
}②删
//删除
LinkList Delete(LinkList L, int k) {
if (L->next == NULL) {
printf("数据%d不存在,删除失败\n", k);
return L;
}
//找到k所在的结点p和上一个结点
Node* pre = L;
Node* p = L->next;
while (p!=NULL&&p->data!=k)
{
pre = p;
p = p->next;
}
if (p == NULL) {
printf("数据%d不存在,删除失败\n", k);
return L;
}
pre->next = p->next;
free(p);
p = NULL;//防止p成为野指针
return L;
}
③改
//首先需要一个查找函数,并且返回该结点的地址
Node* find(LinkList L, int k) {
Node* p = L->next;
while (p!=NULL && p->data != k) {
//出现NULL->data!=k会报错,所以这两项的顺序不可以颠倒
p = p->next;
}
return p;//要么为空,要么保存所要数据
}
//修改
LinkList Replace(LinkList L, int x, int k) {
Node* p = find(L, x);
if (p == NULL) {
printf("数据%d不存在\n,修改失败", x);
return L;
}
else {
p->data = k;
}
return L;
}④查
查找某个数据所在的结点
//首先需要一个查找函数,并且返回该结点的地址
Node* find(LinkList L, int k) {
Node* p = L->next;
while (p!=NULL && p->data != k) {
//出现NULL->data!=k会报错,所以这两项的顺序不可以颠倒
p = p->next;
}
return p;//要么为空,要么保存所要数据
}整体代码示例
#include<stdio.h>
#include<stdlib.h>
typedef struct Node {
int data; //该节点的数据
struct Node* next;
}Node,*LinkList;//*LinkList是结构体指针
//LinkList等价于Node*
//LinkList p;
//Node* q;
//这里的p和q都是结构体指针,他们的类型相同
//LinkList* x;//二级指针==Node** x
//目的:增强代码可读性
//初始化一个带头结点的空链表
LinkList InitLinkList() {
Node* s = (Node*)malloc(sizeof(Node));//申请头结点
if (s == NULL) {
printf("空间分配失败\n");
}
else {
//s->data 脏数据,不用管
s->next = NULL;
}
return s;
}
//头插法:
LinkList HeadInsert(LinkList L, int k) {
//先申请一个新的结点用来保存数据k
Node* s = (Node*)malloc(sizeof(Node));
if (s == NULL) {
printf("空间分配失败/n");
}
else {
s->data = k;//将数据传给新申请的结点s
s->next = L->next;
L->next = s;
}
return L;
}
//尾插法
LinkList RearInsert(LinkList L, int k) {
Node* p = L; //指针指p向头结点
while (p->next != NULL) {
p = p->next;
}
//循环结束后指针p指向最后一个结点
//先申请一个新的结点用来保存数据k
Node* s = (Node*)malloc(sizeof(Node));
if (s == NULL) {
printf("空间分配失败\n");
return L;
}
else {
s->data = k;//将数据传给新申请的结点s
s->next = NULL;
p->next = s;
}
return L;
}
//中间插入
//首先需要一个查找函数,并且返回该结点的地址
Node* find(LinkList L, int k) {
Node* p = L->next;
while (p!=NULL && p->data != k) {
//出现NULL->data!=k会报错,所以这两项的顺序不可以颠倒
p = p->next;
}
return p;//要么为空,要么保存所要数据
}
//中间插入的函数
Node* MidInsert(LinkList L, int x, int k) {
//在元素x后面插入数据k
Node* p = find(L, x);
if (p == NULL) {
printf("数据%d不存在,无法找到插入位置,插入失败\n",x);
return L;
}
Node* s = (Node*)malloc(sizeof(Node));
if (s == NULL) {
printf("空间分配失败,插入失败\n");
return L;
}
else {
s->data = k;
s->next = p->next;
p->next = s;
}
return L;
}
//修改
LinkList Replace(LinkList L, int x, int k) {
Node* p = find(L, x);
if (p == NULL) {
printf("数据%d不存在,无法找到修改位置,修改失败\n", x);
return L;
}
else {
p->data = k;
}
return L;
}
//删除
LinkList Delete(LinkList L, int k) {
if (L->next == NULL) {
printf("数据%d不存在,删除失败\n", k);
return L;
}
//找到k所在的结点p和上一个结点
Node* pre = L;
Node* p = L->next;
while (p!=NULL&&p->data!=k)
{
pre = p;
p = p->next;
}
if (p == NULL) {
printf("数据%d不存在,删除失败\n", k);
return L;
}
pre->next = p->next;
free(p);
p = NULL;//防止p成为野指针
return L;
}
void show(LinkList L) {
Node* p = L->next;
while (p!=NULL)
{
printf("%d\t", p->data);
p = p->next;
}
}
int main() {
LinkList L = NULL;
L = InitLinkList();
L=HeadInsert(L,10);
L = HeadInsert(L, 8);
L = RearInsert(L, 15);
L = MidInsert(L, 5, 55);
L=Replace(L, 8, 88);
L = Delete(L, 8);
show(L);
}运行结果:


















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









