



1.环境准备
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple2.数据集下载
https://www.modelscope.cn/datasets/gongjy/minimind_dataset/files
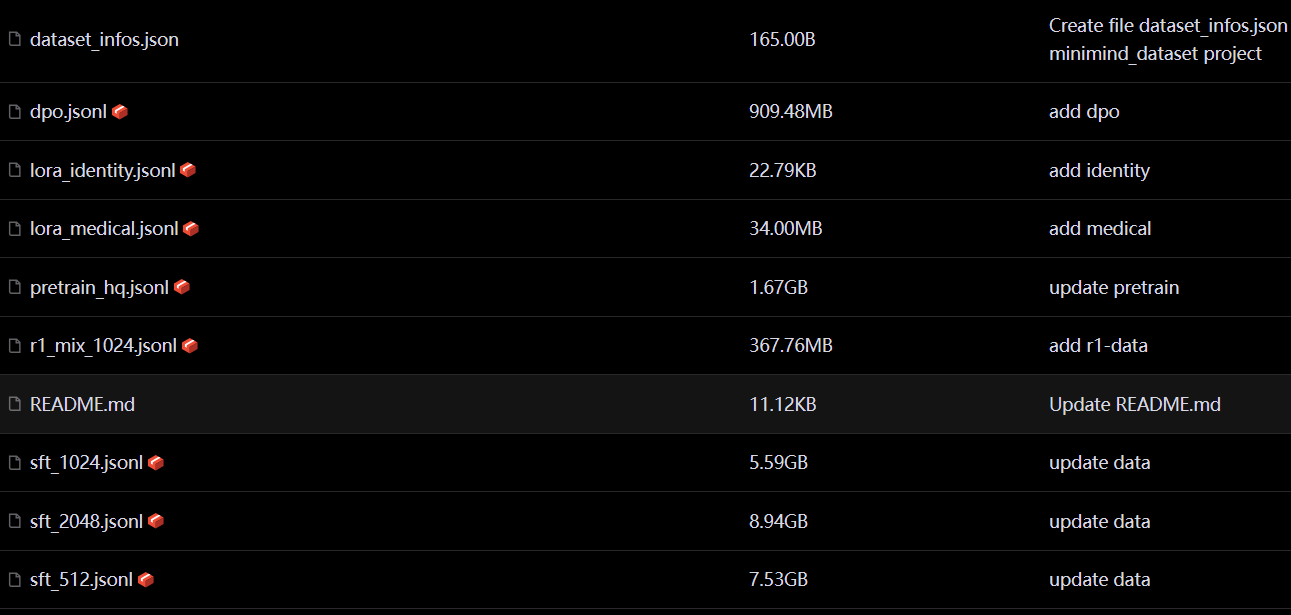
dpo.jsonl--RLHF阶段数据集lora_identity.jsonl--自我认知数据集(例如:你是谁?我是minimind...),推荐用于lora训练(亦可用于全参SFT,勿被名字局限)lora_medical.jsonl--医疗问答数据集,推荐用于lora训练(亦可用于全参SFT,勿被名字局限)pretrain_hq.jsonl✨ --预训练数据集,整合自匠数科技r1_mix_1024.jsonl--DeepSeek-R1-1.5B蒸馏数据,每条数据字符最大长度为1024(因此训练时设置max_seq_len=1024)sft_1024.jsonl--整合自Qwen2.5蒸馏数据(是sft_2048的子集),每条数据字符最大长度为1024(因此训练时设置max_seq_len=1024)sft_2048.jsonl--整合自Qwen2.5蒸馏数据,每条数据字符最大长度为2048(因此训练时设置max_seq_len=2048)sft_512.jsonl--整合自匠数科技SFT数据,每条数据字符最大长度为512(因此训练时设置max_seq_len=512)sft_mini_512.jsonl✨ --极简整合自匠数科技SFT数据+Qwen2.5蒸馏数据(用于快速训练Zero模型),每条数据字符最大长度为512(因此训练时设置max_seq_len=512)tokenizer_train.jsonl--均来自于匠数大模型数据集,这部分数据相对次要,(不推荐自己重复训练tokenizer,理由如上)如需自己训练tokenizer可以自由选择数据集。
人设数据集 lora_identity.jsonl
{"conversations": [{"role": "user", "content": "你好"},
{"role": "assistant", "content": "您好,我是 MiniMind,一个由 Jingyao Gong
打造的人工智能助手,请问有什么可以帮助您的吗?"}]}
3.训练
3.1 预训练(Pretrain)
预训练就是让Model先埋头苦学大量基本的知识,例如从Wiki百科、新闻、书籍整理大规模的高质量训练数据
python train_pretrain.py
{"text": "<|im_start|>鉴别一组中文文章的风格和特点,例如官方、口语、文言等。需要提供样例文章才能准确鉴别不同的风格和特点。<|im_end|>
<|im_start|>好的,现在帮我查一下今天的天气怎么样?今天的天气依据地区而异。请问你需要我帮你查询哪个地区的天气呢?<|im_end|>
<|im_start|>打开闹钟功能,定一个明天早上七点的闹钟。好的,我已经帮您打开闹钟功能,闹钟将在明天早上七点准时响起。<|im_end|>
<|im_start|>为以下场景写一句话描述:一个孤独的老人坐在公园长椅上看着远处。一位孤独的老人坐在公园长椅上凝视远方。<|im_end|>
<|im_start|>非常感谢你的回答。请告诉我,这些数据是关于什么主题的?这些数据是关于不同年龄段的男女人口比例分布的。<|im_end|>
<|im_start|>帮我想一个有趣的标题。这个挺有趣的:\"如何成为一名成功的魔术师\" 调皮的标题往往会吸引读者的注意力。<|im_end|>
<|im_start|>回答一个问题,地球的半径是多少?地球的平均半径约为6371公里,这是地球自赤道到两极的距离的平均值。<|im_end|>
<|im_start|>识别文本中的语气,并将其分类为喜悦、悲伤、惊异等。\n文本:“今天是我的生日!”这个文本的语气是喜悦。<|im_end|>"}
{"text": "<|im_start|>根据输入的内容,编写一个类别标签。\n这是一篇介绍如何阅读心电图的文章类别标签: 医学/心电图阅读指南<|im_end|>
<|im_start|>帮我搜索一下最近的天气情况。当然,我可以帮您搜索最新的天气情况。请问您需要查询哪个城市的天气情况呢?<|im_end|>
<|im_start|>帮我讲一个令人开心的笑话。好的,我帮您讲一个关于细菌的笑话。为什么细菌不会上网?因为连接总是断开了!<|im_end|>
<|im_start|>现在给我生成一首关于大海的五言诗。碧波万顷月满天,海天相接处天地间。波涛滚滚江山美,海鸟翱翔日月闲。<|im_end|>
<|im_start|>谢谢你,这篇文章很有用。不客气,我很高兴能够为您提供帮助。如果您还有其他问题或需求,随时可以对我说。<|im_end|>
<|im_start|>你好,我想下载一个视频编辑软件,你有什么推荐吗?您好!当然,有很多选择。您想要免费软件还是愿意付费?<|im_end|>
<|im_start|>为什么我的程序不输出正确结果?可能是代码逻辑有误,或者输入数据有误,需要仔细调试代码逻辑和输入数据。<|im_end|>
<|im_start|>谢谢你的回答。现在我想知道这场比赛的具体时间和地点。这场比赛的时间是北京时间10月4日,地点是上海。<|im_end|>"}
3.2监督微调(Supervised Fine-Tuning)
经过预训练,LLM此时已经掌握了大量知识,然而此时它只会无脑地词语接龙,还不会与人聊天。 SFT阶段就需要把半成品LLM施加一个自定义的聊天模板进行微调。 例如模型遇到这样的模板【问题->回答,问题->回答】后不再无脑接龙,而是意识到这是一段完整的对话结束。
python train_full_sft.py
{"conversations": [
{"content": "给定一段文本和关键词列表,删除文本中包含所有给定关键词的子字符串。\n文本:\"这是一个测试句子,目的是看看模型是否可以正确地从这个句子中删除关键词。\"\\n关键词列表:[‘测试’,‘模型’]", "role": "user"},
{"content": "删除包含所有给定关键词的子字符串后,文本变为:\"这是一个句子,目的是看看是否可以正确地从这个句子中删除关键词。\"", "role": "assistant"},
{"content": "好的。现在请你将这个文本中的所有的逗号都替换成空格。", "role": "user"},
{"content": "好的,请稍等一下,现在我会将文本中的所有逗号替换为空格。处理后文本为:\"这是一个句子 目的是看看是否可以正确地从这个句子中删除关键词。\"。处理结果如何?", "role": "assistant"}
]}
{"conversations": [
{"content": "写一个关于秋天的诗吧。", "role": "user"}, {"content": "红黄绿交织,田野金黄色。风吹枫叶落,人在秋天慢步行。", "role": "assistant"},
{"content": "给我推荐一些好听的摇滚歌曲。", "role": "user"},
{"content": "摇滚歌曲推荐:AC/DC的Back in Black,Guns N' Roses的Sweet Child O' Mine,Rolling Stones的Satisfaction,Led Zeppelin的Stairway to Heaven,Nirvana的Smells Like Teen Spirit等。", "role": "assistant"},
{"content": "计算一下2的100次方。", "role": "user"},
{"content": "2的100次方等于1.267650600228229401496703205376e+30,约等于1.27乘以10的30次方。","role": "assistant"},
{"content": "帮我回答一道历史题目。清朝时期的八旗共有多少旗人?", "role": "user"},
{"content": "清朝时期八旗旗人总数约为200万人左右,其中正黄
旗、正蓝旗、正白旗、正红旗的人数较多,其他旗的人数较少。", "role": "assistant"}]}
3.3 微调LoRA (Low-Rank Adaptation)
LoRA是一种高效的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,旨在通过低秩分解的方式对预训练模型进行微调。 相比于全参数微调(Full Fine-Tuning),LoRA 只需要更新少量的参数。 LoRA 的核心思想是:在模型的权重矩阵中引入低秩分解,仅对低秩部分进行更新,而保持原始预训练权重不变。 代码可见./model/model_lora.py和train_lora.py,完全从0实现LoRA流程,不依赖第三方库的封装。
{"conversations": [{"role": "user", "content": "头发稀少细软可以植发吗"},
{"role": "assistant", "content": "是的,头发稀少和细软的情况下,
植发是一种可能的解决方案。植发手术是一种将
头发从头部的一个地方移植到另一个地方的过程,通常用于治疗男性或女性的脱发。这种手术通常由皮肤科医生进
行。\n\n植发手术的两种主要类型是:毛囊单位移植(FUT)和毛囊单位提取(FUE)。在FUT中,医生会从后脑勺
切下一块头皮,然后将其分成数百个小部分,每个部分包含一个或几个毛囊,然后将这些毛囊植入秃头区域。在
FUE中,医生会直接从头皮上提取毛囊,然后将它们植入秃头区域。\n\n然而,植发手术并不适合所有人。理想的
候选人应该有足够的健康毛囊可以移植。此外,患者应该有适当的期望,因为植发手术可能需要多次手术,并且结
果可能需要一年或更长时间才能显现。\n\n在决定是否进行植发手术之前,建议您咨询医生或植发专家,以了解这
是否是最佳的解决方案。他们可以帮助您了解手术的风险和益处,以及可能的替代方案,如药物治疗或使用假
发。"}]}
3.4 垂域知识训练
非常多的人困惑,如何使模型学会自己私有领域的知识?如何准备数据集?如何迁移通用领域模型打造垂域模型? 这里举几个例子,对于通用模型,医学领域知识欠缺,可以尝试在原有模型基础上加入领域知识,以获得更好的性能。 同时,我们通常不希望学会领域知识的同时损失原有基础模型的其它能力,此时LoRA可以很好的改善这个问题。 只需要准备如下格式的对话数据集放置到./dataset/lora_xxx.jsonl,启动 python train_lora.py 训练即可得到./out/lora/lora_xxx.pth新模型权重。
4.pth文件为训练好的模型
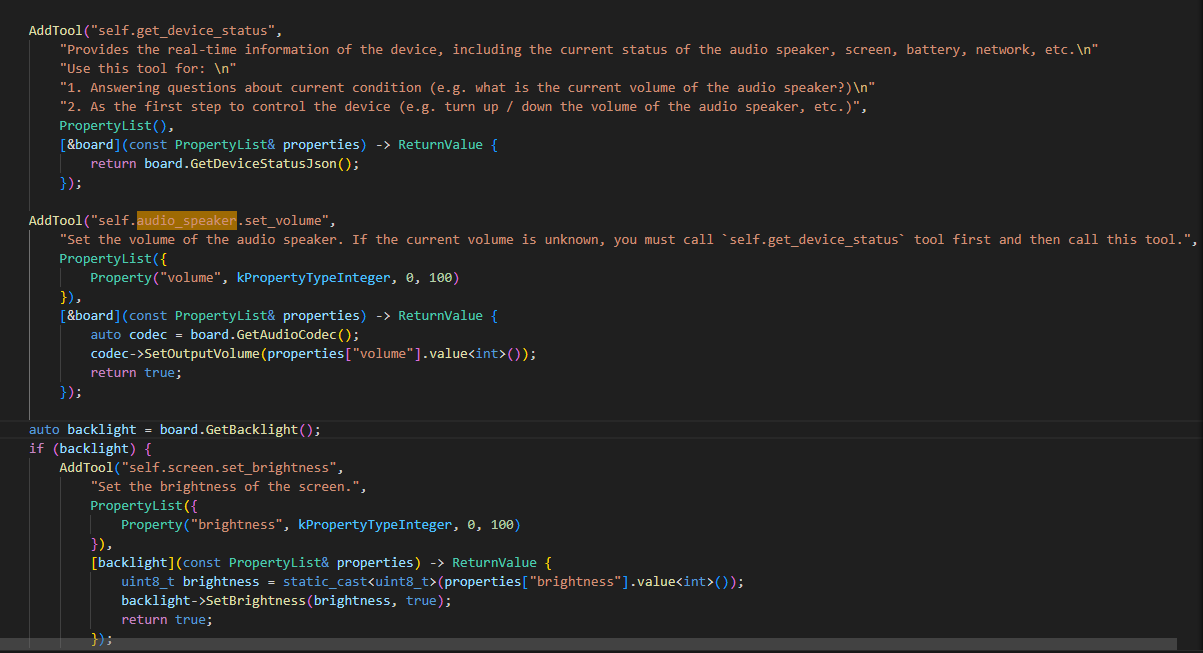
5. MCP 调用

















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









